 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Mouse from Incomplete Body-Part Observations and Deep-Learned Deformable-Mouse Model Motion-Track Constraint for Behavior Analysis
Jan 19, 2025Tracking mouse body parts in video is often incomplete due to occlusions such that - e.g. - subsequent action and behavior analysis is impeded. In this conceptual work, videos from several perspectives are integrated via global exterior camera orientation; body part positions are estimated by 3D triangulation and bundle adjustment. Consistency of overall 3D track reconstruction is achieved by introduction of a 3D mouse model, deep-learned body part movements, and global motion-track smoothness constraint. The resulting 3D body and body part track estimates are substantially more complete than the original single-frame-based body part detection, therefore, allowing improved animal behavior analysis.
* 10 pages
ConDL: Detector-Free Dense Image Matching
Aug 05, 2024



In this work, we introduce a deep-learning framework designed for estimating dense image correspondences. Our fully convolutional model generates dense feature maps for images, where each pixel is associated with a descriptor that can be matched across multiple images. Unlike previous methods, our model is trained on synthetic data that includes significant distortions, such as perspective changes, illumination variations, shadows, and specular highlights. Utilizing contrastive learning, our feature maps achieve greater invariance to these distortions, enabling robust matching. Notably, our method eliminates the need for a keypoint detector, setting it apart from many existing image-matching techniques.
Decomposer: Semi-supervised Learning of Image Restoration and Image Decomposition
Nov 28, 2023



We present Decomposer, a semi-supervised reconstruction model that decomposes distorted image sequences into their fundamental building blocks - the original image and the applied augmentations, i.e., shadow, light, and occlusions. To solve this problem, we use the SIDAR dataset that provides a large number of distorted image sequences: each sequence contains images with shadows, lighting, and occlusions applied to an undistorted version. Each distortion changes the original signal in different ways, e.g., additive or multiplicative noise. We propose a transformer-based model to explicitly learn this decomposition. The sequential model uses 3D Swin-Transformers for spatio-temporal encoding and 3D U-Nets as prediction heads for individual parts of the decomposition. We demonstrate that by separately pre-training our model on weakly supervised pseudo labels, we can steer our model to optimize for our ambiguous problem definition and learn to differentiate between the different image distortions.
DIAR: Deep Image Alignment and Reconstruction using Swin Transformers
Oct 17, 2023When taking images of some occluded content, one is often faced with the problem that every individual image frame contains unwanted artifacts, but a collection of images contains all relevant information if properly aligned and aggregated. In this paper, we attempt to build a deep learning pipeline that simultaneously aligns a sequence of distorted images and reconstructs them. We create a dataset that contains images with image distortions, such as lighting, specularities, shadows, and occlusion. We create perspective distortions with corresponding ground-truth homographies as labels. We use our dataset to train Swin transformer models to analyze sequential image data. The attention maps enable the model to detect relevant image content and differentiate it from outliers and artifacts. We further explore using neural feature maps as alternatives to classical key point detectors. The feature maps of trained convolutional layers provide dense image descriptors that can be used to find point correspondences between images. We utilize this to compute coarse image alignments and explore its limitations.
SIDAR: Synthetic Image Dataset for Alignment & Restoration
May 19, 2023



Image alignment and image restoration are classical computer vision tasks. However, there is still a lack of datasets that provide enough data to train and evaluate end-to-end deep learning models. Obtaining ground-truth data for image alignment requires sophisticated structure-from-motion methods or optical flow systems that often do not provide enough data variance, i.e., typically providing a high number of image correspondences, while only introducing few changes of scenery within the underlying image sequences. Alternative approaches utilize random perspective distortions on existing image data. However, this only provides trivial distortions, lacking the complexity and variance of real-world scenarios. Instead, our proposed data augmentation helps to overcome the issue of data scarcity by using 3D rendering: images are added as textures onto a plane, then varying lighting conditions, shadows, and occlusions are added to the scene. The scene is rendered from multiple viewpoints, generating perspective distortions more consistent with real-world scenarios, with homographies closely resembling those of camera projections rather than randomized homographies. For each scene, we provide a sequence of distorted images with corresponding occlusion masks, homographies, and ground-truth labels. The resulting dataset can serve as a training and evaluation set for a multitude of tasks involving image alignment and artifact removal, such as deep homography estimation, dense image matching, 2D bundle adjustment, inpainting, shadow removal, denoising, content retrieval, and background subtraction. Our data generation pipeline is customizable and can be applied to any existing dataset, serving as a data augmentation to further improve the feature learning of any existing method.
Image-based Detection of Surface Defects in Concrete during Construction
Aug 03, 2022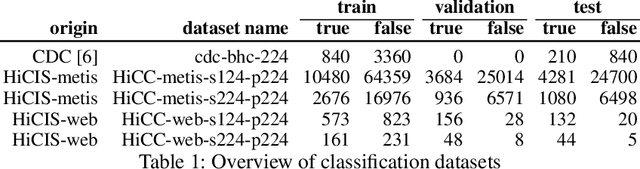
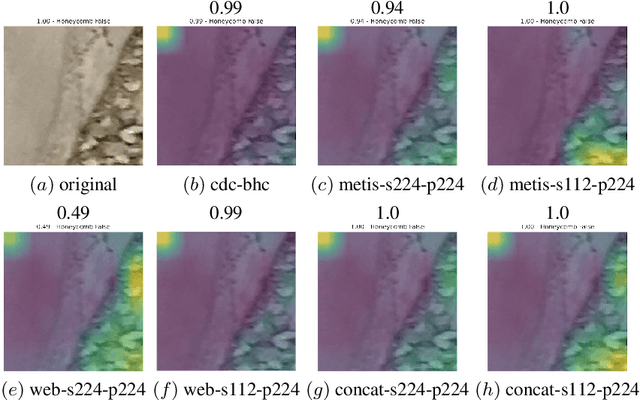


Defects increase the cost and duration of construction projects. Automating defect detection would reduce documentation efforts that are necessary to decrease the risk of defects delaying construction projects. Since concrete is a widely used construction material, this work focuses on detecting honeycombs, a substantial defect in concrete structures that may even affect structural integrity. First, images were compared that were either scraped from the web or obtained from actual practice. The results demonstrate that web images represent just a selection of honeycombs and do not capture the complete variance. Second, Mask R-CNN and EfficientNet-B0 were trained for honeycomb detection to evaluate instance segmentation and patch-based classification, respectively achieving 47.7% precision and 34.2% recall as well as 68.5% precision and 55.7% recall. Although the performance of those models is not sufficient for completely automated defect detection, the models could be used for active learning integrated into defect documentation systems. In conclusion, CNNs can assist detecting honeycombs in concrete.
Content-Based Landmark Retrieval Combining Global and Local Features using Siamese Neural Networks
Aug 03, 2022
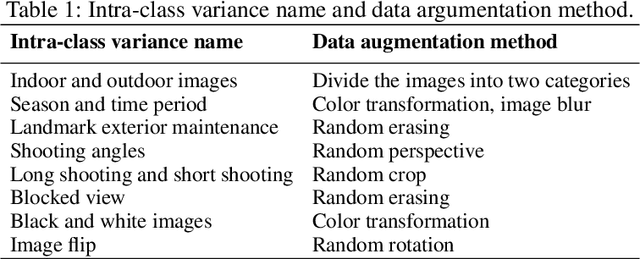

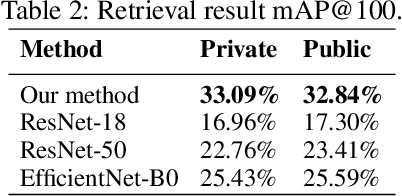
In this work, we present a method for landmark retrieval that utilizes global and local features. A Siamese network is used for global feature extraction and metric learning, which gives an initial ranking of the landmark search. We utilize the extracted feature maps from the Siamese architecture as local descriptors, the search results are then further refined using a cosine similarity between local descriptors. We conduct a deeper analysis of the Google Landmark Dataset, which is used for evaluation, and augment the dataset to handle various intra-class variances. Furthermore, we conduct several experiments to compare the effects of transfer learning and metric learning, as well as experiments using other local descriptors. We show that a re-ranking using local features can improve the search results. We believe that the proposed local feature extraction using cosine similarity is a simple approach that can be extended to many other retrieval tasks.