 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouse Lockbox Dataset: Behavior Recognition for Mice Solving Lockboxes
May 21, 2025Machine learning and computer vision methods have a major impact on the study of natural animal behavior, as they enable the (semi-)automatic analysis of vast amounts of video data. Mice are the standard mammalian model system in most research fields, but the datasets available today to refine such methods focus either on simple or social behaviors. In this work, we present a video dataset of individual mice solving complex mechanical puzzles, so-called lockboxes. The more than 110 hours of total playtime show their behavior recorded from three different perspectives. As a benchmark for frame-level action classification methods, we provide human-annotated labels for all videos of two different mice, that equal 13% of our dataset. Our keypoint (pose) tracking-based action classification framework illustrates the challenges of automated labeling of fine-grained behaviors, such as the manipulation of objects. We hope that our work will help accelerate the advancement of automated action and behavior classification in the computational neuroscience community. Our dataset is publicly available at https://doi.org/10.14279/depositonce-23850
Tracking Mouse from Incomplete Body-Part Observations and Deep-Learned Deformable-Mouse Model Motion-Track Constraint for Behavior Analysis
Jan 19, 2025Tracking mouse body parts in video is often incomplete due to occlusions such that - e.g. - subsequent action and behavior analysis is impeded. In this conceptual work, videos from several perspectives are integrated via global exterior camera orientation; body part positions are estimated by 3D triangulation and bundle adjustment. Consistency of overall 3D track reconstruction is achieved by introduction of a 3D mouse model, deep-learned body part movements, and global motion-track smoothness constraint. The resulting 3D body and body part track estimates are substantially more complete than the original single-frame-based body part detection, therefore, allowing improved animal behavior analysis.
* 10 pages
Discovering Minimal Reinforcement Learning Environments
Jun 18, 2024Reinforcement learning (RL) agents are commonly trained and evaluated in the same environment. In contrast, humans often train in a specialized environment before being evaluated, such as studying a book before taking an exam. The potential of such specialized training environments is still vastly underexplored, despite their capacity to dramatically speed up training. The framework of synthetic environments takes a first step in this direction by meta-learning neural network-based Markov decision processes (MDPs). The initial approach was limited to toy problems and produced environments that did not transfer to unseen RL algorithms. We extend this approach in three ways: Firstly, we modify the meta-learning algorithm to discover environments invariant towards hyperparameter configurations and learning algorithms. Secondly, by leveraging hardware parallelism and introducing a curriculum on an agent's evaluation episode horizon, we can achieve competitive results on several challenging continuous control problems. Thirdly, we surprisingly find that contextual bandits enable training RL agents that transfer well to their evaluation environment, even if it is a complex MDP. Hence, we set up our experiments to train synthetic contextual bandits, which perform on par with synthetic MDPs, yield additional insights into the evaluation environment, and can speed up downstream applications.
Boosting Fairness and Robustness in Over-the-Air Federated Learning
Mar 07, 2024Over-the-Air Computation is a beyond-5G communication strategy that has recently been shown to be useful for the decentralized training of machine learning models due to its efficiency. In this paper, we propose an Over-the-Air federated learning algorithm that aims to provide fairness and robustness through minmax optimization. By using the epigraph form of the problem at hand, we show that the proposed algorithm converges to the optimal solution of the minmax problem. Moreover, the proposed approach does not require reconstructing channel coefficients by complex encoding-decoding schemes as opposed to state-of-the-art approaches. This improves both efficiency and privacy.
Lottery Tickets in Evolutionary Optimization: On Sparse Backpropagation-Free Trainability
May 31, 2023Is the lottery ticket phenomenon an idiosyncrasy of gradient-based training or does it generalize to evolutionary optimization? In this paper we establish the existence of highly sparse trainable initializations for evolution strategies (ES) and characterize qualitative differences compared to gradient descent (GD)-based sparse training. We introduce a novel signal-to-noise iterative pruning procedure, which incorporates loss curvature information into the network pruning step. This can enable the discovery of even sparser trainable network initializations when using black-box evolution as compared to GD-based optimization. Furthermore, we find that these initializations encode an inductive bias, which transfers across different ES, related tasks and even to GD-based training. Finally, we compare the local optima resulting from the different optimization paradigms and sparsity levels. In contrast to GD, ES explore diverse and flat local optima and do not preserve linear mode connectivity across sparsity levels and independent runs. The results highlight qualitative differences between evolution and gradient-based learning dynamics, which can be uncovered by the study of iterative pruning procedures.
Federated Learning in Wireless Networks via Over-the-Air Computations
May 08, 2023

In a multi-agent system, agents can cooperatively learn a model from data by exchanging their estimated model parameters, without the need to exchange the locally available data used by the agents. This strategy, often called federated learning, is mainly employed for two reasons: (i) improving resource-efficiency by avoiding to share potentially large datasets and (ii) guaranteeing privacy of local agents' data. Efficiency can be further increased by adopting a beyond-5G communication strategy that goes under the name of Over-the-Air Computation. This strategy exploits the interference property of the wireless channel. Standard communication schemes prevent interference by enabling transmissions of signals from different agents at distinct time or frequency slots, which is not required with Over-the-Air Computation, thus saving resources. In this case, the received signal is a weighted sum of transmitted signals, with unknown weights (fading channel coefficients). State of the art papers in the field aim at reconstructing those unknown coefficients. In contrast, the approach presented here does not require reconstructing channel coefficients by complex encoding-decoding schemes. This improves both efficiency and privacy.
Restoring speech intelligibility for hearing aid users with deep learning
Jun 23, 2022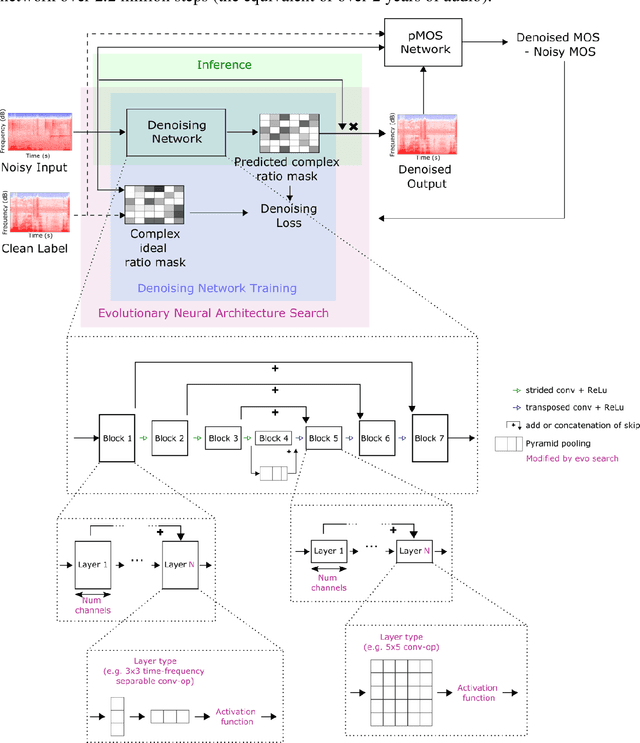
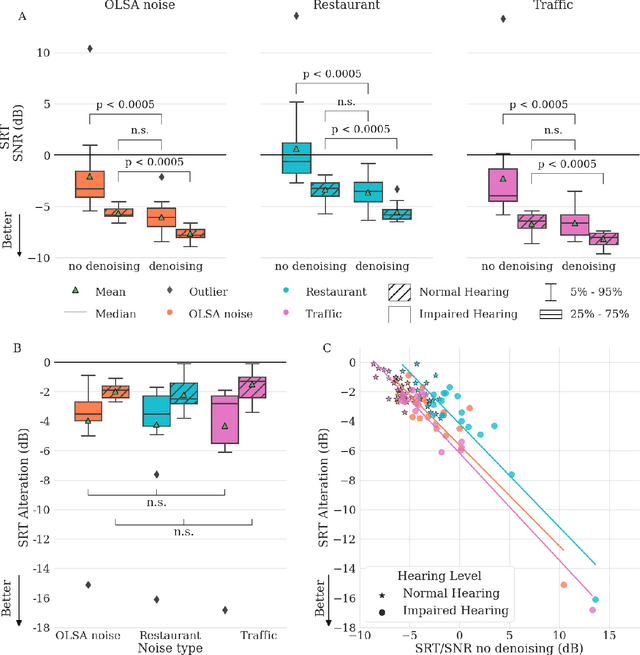

Almost half a billion people world-wide suffer from disabling hearing loss. While hearing aids can partially compensate for this, a large proportion of users struggle to understand speech in situations with background noise. Here, we present a deep learning-based algorithm that selectively suppresses noise while maintaining speech signals. The algorithm restores speech intelligibility for hearing aid users to the level of control subjects with normal hearing. It consists of a deep network that is trained on a large custom database of noisy speech signals and is further optimized by a neural architecture search, using a novel deep learning-based metric for speech intelligibility. The network achieves state-of-the-art denoising on a range of human-graded assessments, generalizes across different noise categories and - in contrast to classic beamforming approaches - operates on a single microphone. The system runs in real time on a laptop, suggesting that large-scale deployment on hearing aid chips could be achieved within a few years. Deep learning-based denoising therefore holds the potential to improve the quality of life of millions of hearing impaired people soon.
On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
May 31, 2021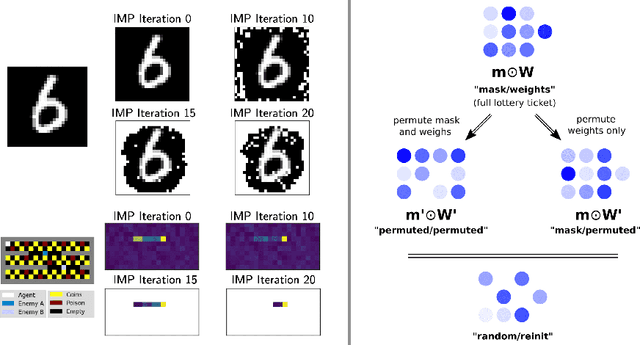
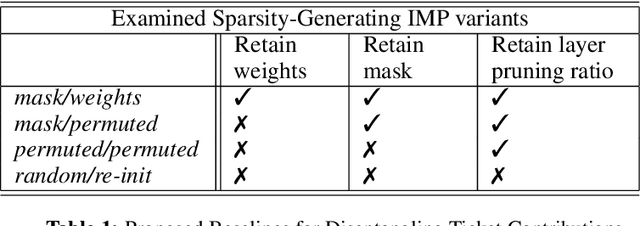
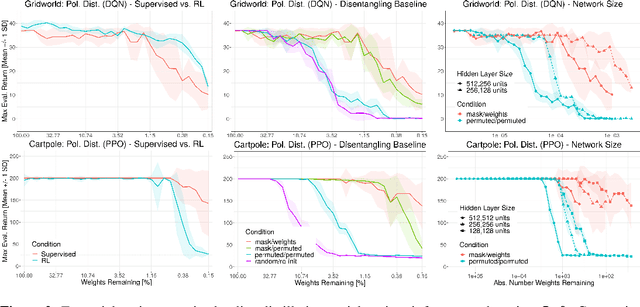
The lottery ticket hypothesis questions the role of overparameterization in supervised deep learning. But how is the performance of winning lottery tickets affected by the distributional shift inherent to reinforcement learning problems? In this work, we address this question by comparing sparse agents who have to address the non-stationarity of the exploration-exploitation problem with supervised agents trained to imitate an expert. We show that feed-forward networks trained via reinforcement learning and imitation learning can be pruned to the same level of sparsity, suggesting that the distributional shift has a limited impact on the size of winning tickets. Using a set of carefully designed baseline conditions, we find that the majority of the lottery ticket effect in both learning paradigms can be attributed to the identified mask rather than the weight initialization. The input layer mask selectively prunes entire input dimensions that turn out to be irrelevant for the task at hand. At a moderate level of sparsity the mask identified by iterative magnitude pruning yields minimal task-relevant representations, i.e., an interpretable inductive bias. Finally, we propose a simple initialization rescaling which promotes the robust identification of sparse task representations in low-dimensional control tasks.
Learning not to learn: Nature versus nurture in silico
Oct 09, 2020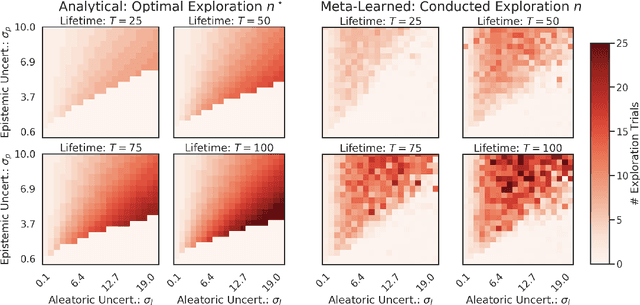

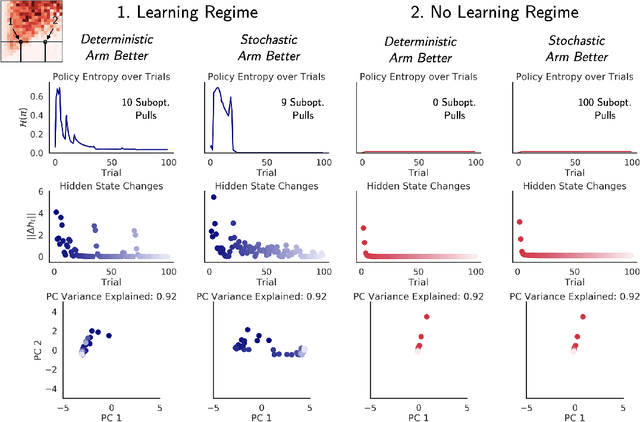

Animals are equipped with a rich innate repertoire of sensory, behavioral and motor skills, which allows them to interact with the world immediately after birth. At the same time, many behaviors are highly adaptive and can be tailored to specific environments by means of learning. In this work, we use mathematical analysis and the framework of meta-learning (or 'learning to learn') to answer when it is beneficial to learn such an adaptive strategy and when to hard-code a heuristic behavior. We find that the interplay of ecological uncertainty, task complexity and the agents' lifetime has crucial effects on the meta-learned amortized Bayesian inference performed by an agent. There exist two regimes: One in which meta-learning yields a learning algorithm that implements task-dependent information-integration and a second regime in which meta-learning imprints a heuristic or 'hard-coded' behavior. Further analysis reveals that non-adaptive behaviors are not only optimal for aspects of the environment that are stable across individuals, but also in situations where an adaptation to the environment would in fact be highly beneficial, but could not be done quickly enough to be exploited within the remaining lifetime. Hard-coded behaviors should hence not only be those that always work, but also those that are too complex to be learned within a reasonable time frame.