 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Fairness and Robustness in Over-the-Air Federated Learning
Mar 07, 2024Over-the-Air Computation is a beyond-5G communication strategy that has recently been shown to be useful for the decentralized training of machine learning models due to its efficiency. In this paper, we propose an Over-the-Air federated learning algorithm that aims to provide fairness and robustness through minmax optimization. By using the epigraph form of the problem at hand, we show that the proposed algorithm converges to the optimal solution of the minmax problem. Moreover, the proposed approach does not require reconstructing channel coefficients by complex encoding-decoding schemes as opposed to state-of-the-art approaches. This improves both efficiency and privacy.
Federated Learning in Wireless Networks via Over-the-Air Computations
May 08, 2023In a multi-agent system, agents can cooperatively learn a model from data by exchanging their estimated model parameters, without the need to exchange the locally available data used by the agents. This strategy, often called federated learning, is mainly employed for two reasons: (i) improving resource-efficiency by avoiding to share potentially large datasets and (ii) guaranteeing privacy of local agents' data. Efficiency can be further increased by adopting a beyond-5G communication strategy that goes under the name of Over-the-Air Computation. This strategy exploits the interference property of the wireless channel. Standard communication schemes prevent interference by enabling transmissions of signals from different agents at distinct time or frequency slots, which is not required with Over-the-Air Computation, thus saving resources. In this case, the received signal is a weighted sum of transmitted signals, with unknown weights (fading channel coefficients). State of the art papers in the field aim at reconstructing those unknown coefficients. In contrast, the approach presented here does not require reconstructing channel coefficients by complex encoding-decoding schemes. This improves both efficiency and privacy.
Collective Iterative Learning Control: Exploiting Diversity in Multi-Agent Systems for Reference Tracking Tasks
Apr 15, 2021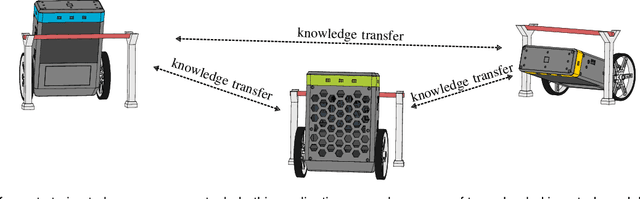

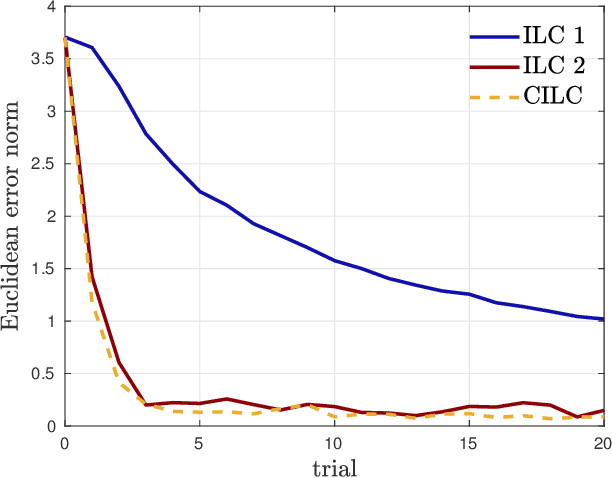
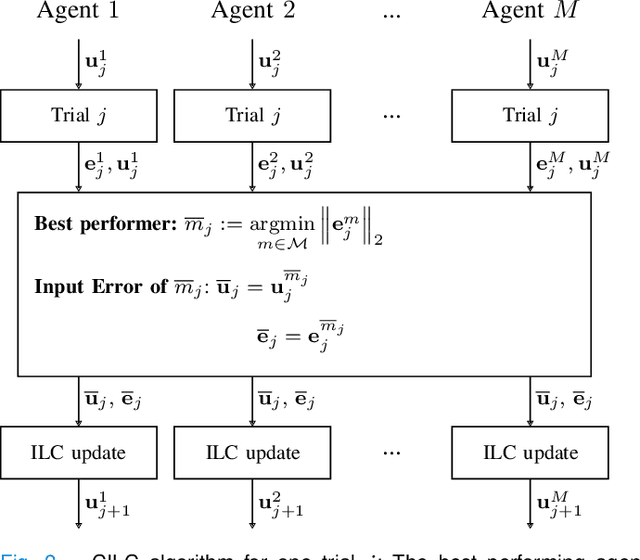
This paper considers a group of autonomous agents learning to track the same given reference trajectory in a possibly small number of trials. We propose a novel collective learning control method (namely, CILC) that combines Iterative Learning Control (ILC) with a collective input update strategy. We derive conditions for desirable convergence properties of such systems. We show that the proposed method allows the collective to combine the advantages of the agents' individual learning strategies and thereby overcomes trade-offs and limitations of single-agent ILC. This benefit is leveraged by designing a heterogeneous collective, i.e., a different learning law is assigned to each agent. All theoretical results are confirmed in simulations and experiments with two-wheeled-inverted-pendulums robots (TWIPRs) that jointly learn to perform a desired maneuver.