 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoPP: Metric-Scaled Self-Supervised Monocular Depth Estimation by Planar-Parallax Geometry in Automotive Applications
Paper and Code
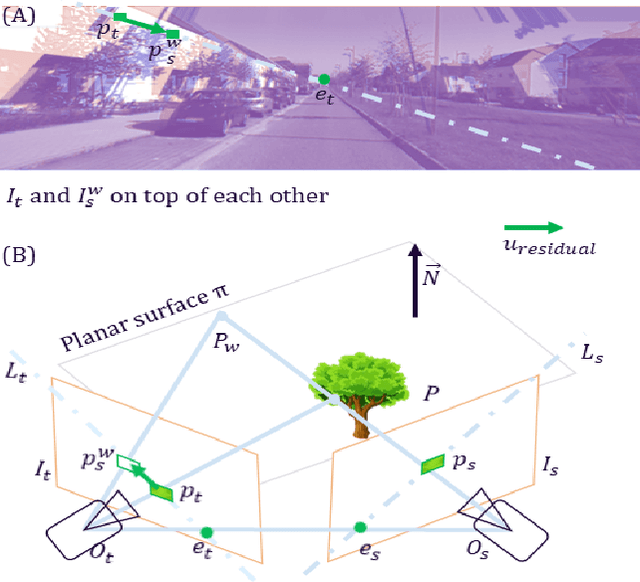
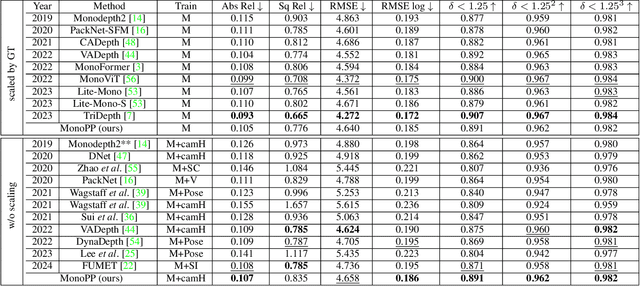

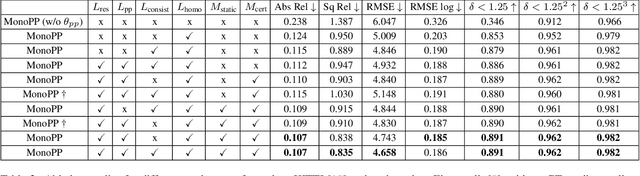
Self-supervised monocular depth estimation (MDE) has gained popularity for obtaining depth predictions directly from videos. However, these methods often produce scale invariant results, unless additional training signals are provided. Addressing this challenge, we introduce a novel self-supervised metric-scaled MDE model that requires only monocular video data and the camera's mounting position, both of which are readily available in modern vehicles. Our approach leverages planar-parallax geometry to reconstruct scene structure. The full pipeline consists of three main networks, a multi-frame network, a singleframe network, and a pose network. The multi-frame network processes sequential frames to estimate the structure of the static scene using planar-parallax geometry and the camera mounting position. Based on this reconstruction, it acts as a teacher, distilling knowledge such as scale information, masked drivable area, metric-scale depth for the static scene, and dynamic object mask to the singleframe network. It also aids the pose network in predicting a metric-scaled relative pose between two subsequent images. Our method achieved state-of-the-art results for the driving benchmark KITTI for metric-scaled depth prediction. Notably, it is one of the first methods to produce self-supervised metric-scaled depth prediction for the challenging Cityscapes dataset, demonstrating its effectiveness and versatility.