 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Multi-Modal Self-Supervised Learning for Facial Expression Recognition
Apr 16, 2024
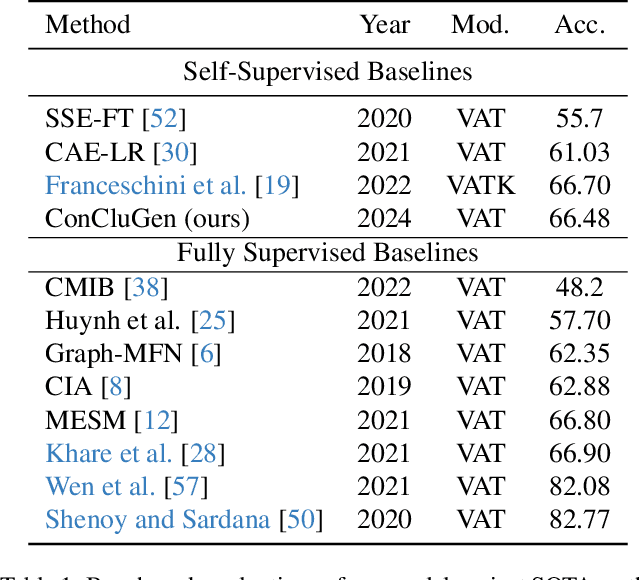
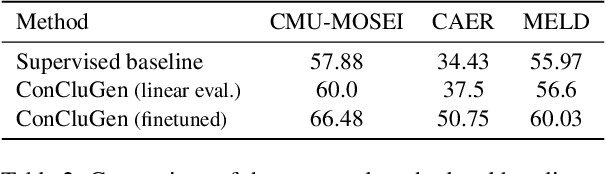

Human communication is multi-modal; e.g., face-to-face interaction involves auditory signals (speech) and visual signals (face movements and hand gestures). Hence, it is essential to exploit multiple modalities when designing machine learning-based facial expression recognition systems. In addition, given the ever-growing quantities of video data that capture human facial expressions, such systems should utilize raw unlabeled videos without requiring expensive annotations. Therefore, in this work, we employ a multitask multi-modal self-supervised learning method for facial expression recognition from in-the-wild video data. Our model combines three self-supervised objective functions: First, a multi-modal contrastive loss, that pulls diverse data modalities of the same video together in the representation space. Second, a multi-modal clustering loss that preserves the semantic structure of input data in the representation space. Finally, a multi-modal data reconstruction loss. We conduct a comprehensive study on this multimodal multi-task self-supervised learning method on three facial expression recognition benchmarks. To that end, we examine the performance of learning through different combinations of self-supervised tasks on the facial expression recognition downstream task. Our model ConCluGen outperforms several multi-modal self-supervised and fully supervised baselines on the CMU-MOSEI dataset. Our results generally show that multi-modal self-supervision tasks offer large performance gains for challenging tasks such as facial expression recognition, while also reducing the amount of manual annotations required. We release our pre-trained models as well as source code publicly
WiCV@CVPR2023: The Eleventh Women In Computer Vision Workshop at the Annual CVPR Conference
Sep 22, 2023In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2023, organized alongside the hybrid CVPR 2023 in Vancouver, Canada. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a) opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate finanacial burdens and d) a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2023 workshop.
WiCV 2022: The Tenth Women In Computer Vision Workshop
Aug 24, 2022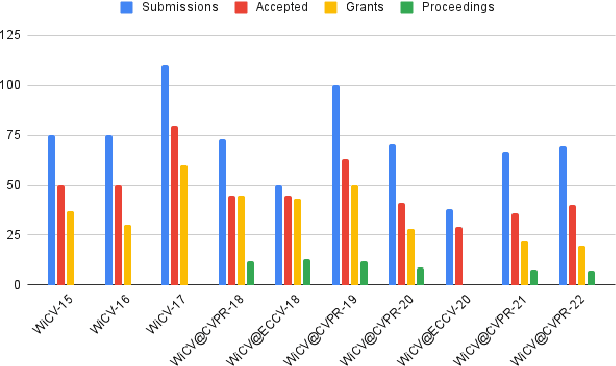
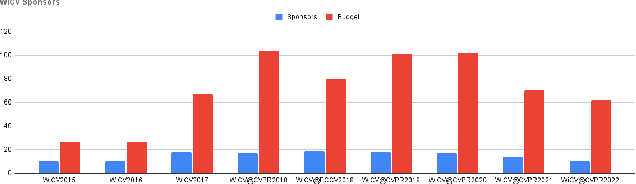
In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2022, organized alongside the hybrid CVPR 2022 in New Orleans, Louisiana. It provides a voice to a minority (female) group in the computer vision community and focuses on increasing the visibility of these researchers, both in academia and industry. WiCV believes that such an event can play an important role in lowering the gender imbalance in the field of computer vision. WiCV is organized each year where it provides a) opportunity for collaboration between researchers from minority groups, b) mentorship to female junior researchers, c) financial support to presenters to overcome monetary burden and d) large and diverse choice of role models, who can serve as examples to younger researchers at the beginning of their careers. In this paper, we present a report on the workshop program, trends over the past years, a summary of statistics regarding presenters, attendees, and sponsorship for the WiCV 2022 workshop.
Action-based Contrastive Learning for Trajectory Prediction
Jul 18, 2022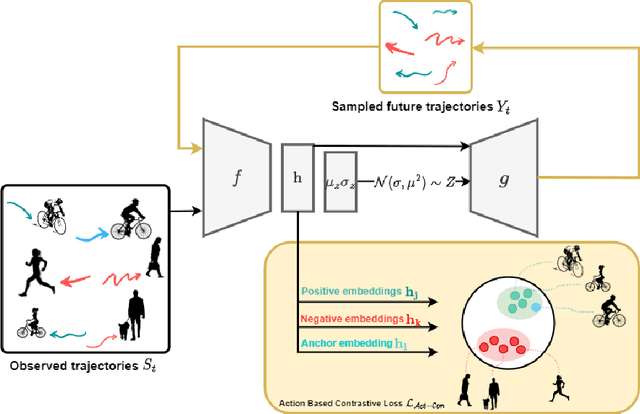
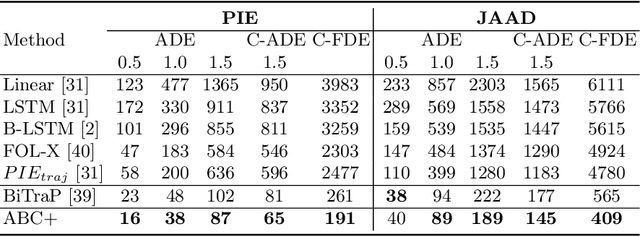

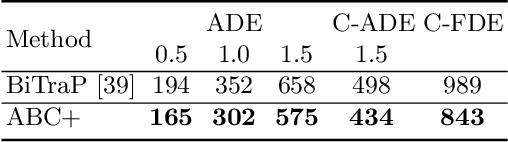
Trajectory prediction is an essential task for successful human robot interaction, such as in autonomous driving. In this work, we address the problem of predicting future pedestrian trajectories in a first person view setting with a moving camera. To that end, we propose a novel action-based contrastive learning loss, that utilizes pedestrian action information to improve the learned trajectory embeddings. The fundamental idea behind this new loss is that trajectories of pedestrians performing the same action should be closer to each other in the feature space than the trajectories of pedestrians with significantly different actions. In other words, we argue that behavioral information about pedestrian action influences their future trajectory. Furthermore, we introduce a novel sampling strategy for trajectories that is able to effectively increase negative and positive contrastive samples. Additional synthetic trajectory samples are generated using a trained Conditional Variational Autoencoder (CVAE), which is at the core of several models developed for trajectory prediction. Results show that our proposed contrastive framework employs contextual information about pedestrian behavior, i.e. action, effectively, and it learns a better trajectory representation. Thus, integrating the proposed contrastive framework within a trajectory prediction model improves its results and outperforms state-of-the-art methods on three trajectory prediction benchmarks [31, 32, 26].
Learning Disentangled Expression Representations from Facial Images
Aug 18, 2020
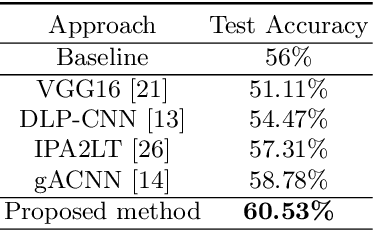


Face images are subject to many different factors of variation, especially in unconstrained in-the-wild scenarios. For most tasks involving such images, e.g. expression recognition from video streams, having enough labeled data is prohibitively expensive. One common strategy to tackle such a problem is to learn disentangled representations for the different factors of variation of the observed data using adversarial learning. In this paper, we use a formulation of the adversarial loss to learn disentangled representations for face images. The used model facilitates learning on single-task datasets and improves the state-of-the-art in expression recognition with an accuracy of60.53%on the AffectNetdataset, without using any additional data.