Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Expression Representations from Facial Images
Aug 18, 2020
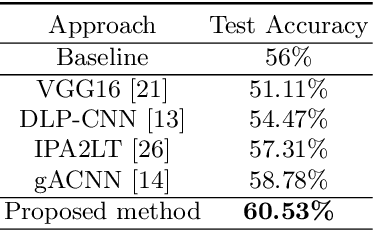


Face images are subject to many different factors of variation, especially in unconstrained in-the-wild scenarios. For most tasks involving such images, e.g. expression recognition from video streams, having enough labeled data is prohibitively expensive. One common strategy to tackle such a problem is to learn disentangled representations for the different factors of variation of the observed data using adversarial learning. In this paper, we use a formulation of the adversarial loss to learn disentangled representations for face images. The used model facilitates learning on single-task datasets and improves the state-of-the-art in expression recognition with an accuracy of60.53%on the AffectNetdataset, without using any additional data.
* Accepted at ECCV2020 workshops
Via