 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025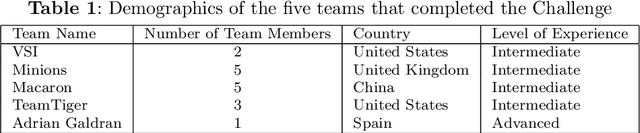
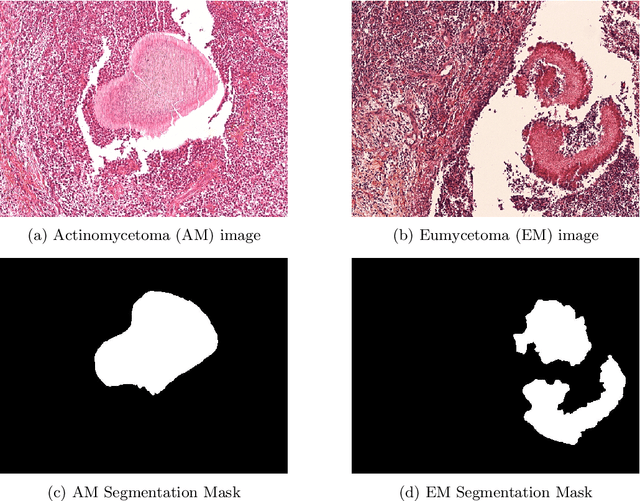
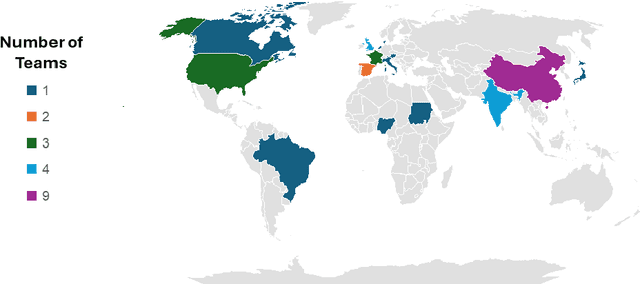

Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
WiCV@CVPR2024: The Thirteenth Women In Computer Vision Workshop at the Annual CVPR Conference
Nov 03, 2024In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2024, organized alongside the CVPR 2024 in Seattle, Washington, United States. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a)~opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate financial burdens and d)~a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2024 workshop.
WiCV@CVPR2023: The Eleventh Women In Computer Vision Workshop at the Annual CVPR Conference
Sep 22, 2023In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2023, organized alongside the hybrid CVPR 2023 in Vancouver, Canada. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a) opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate finanacial burdens and d) a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2023 workshop.
UnseenNet: Fast Training Detector for Any Unseen Concept
Mar 26, 2022
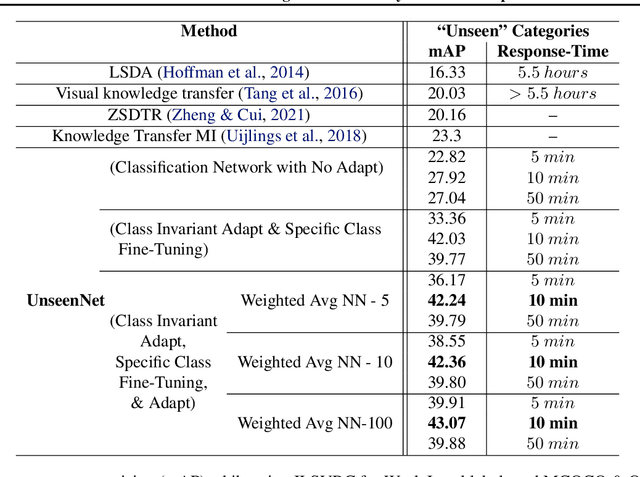
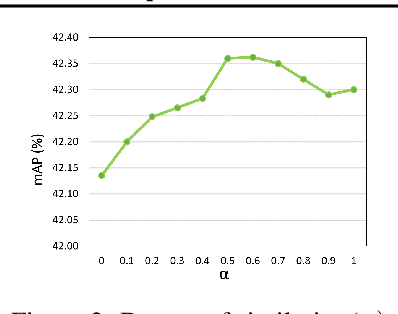
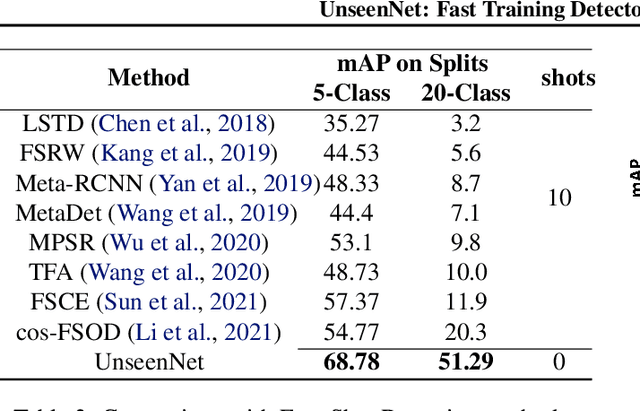
Training of object detection models using less data is currently the focus of existing N-shot learning models in computer vision. Such methods use object-level labels and takes hours to train on unseen classes. There are many cases where we have large amount of image-level labels available for training but cannot be utilized by few shot object detection models for training. There is a need for a machine learning framework that can be used for training any unseen class and can become useful in real-time situations. In this paper, we proposed an "Unseen Class Detector" that can be trained within a very short time for any possible unseen class without bounding boxes with competitive accuracy. We build our approach on "Strong" and "Weak" baseline detectors, which we trained on existing object detection and image classification datasets, respectively. Unseen concepts are fine-tuned on the strong baseline detector using only image-level labels and further adapted by transferring the classifier-detector knowledge between baselines. We use semantic as well as visual similarities to identify the source class (i.e. Sheep) for the fine-tuning and adaptation of unseen class (i.e. Goat). Our model (UnseenNet) is trained on the ImageNet classification dataset for unseen classes and tested on an object detection dataset (OpenImages). UnseenNet improves the mean average precision (mAP) by 10% to 30% over existing baselines (semi-supervised and few-shot) of object detection on different unseen class splits. Moreover, training time of our model is <10 min for each unseen class. Qualitative results demonstrate that UnseenNet is suitable not only for few classes of Pascal VOC but for unseen classes of any dataset or web. Code is available at https://github.com/Asra-Aslam/UnseenNet.
A Survey of Modern Deep Learning based Object Detection Models
May 12, 2021



Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors. Concise overview of benchmark datasets and evaluation metrics used in detection is also provided along with some of the prominent backbone architectures used in recognition tasks. It also covers contemporary lightweight classification models used on edge devices. Lastly, we compare the performances of these architectures on multiple metrics.
A Novel Falling-Ball Algorithm for Image Segmentation
May 12, 2021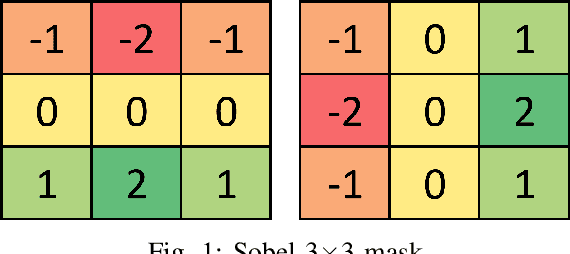
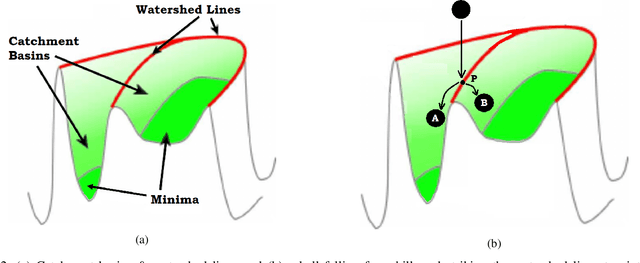
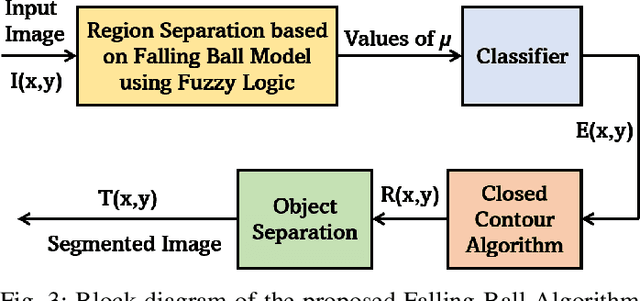
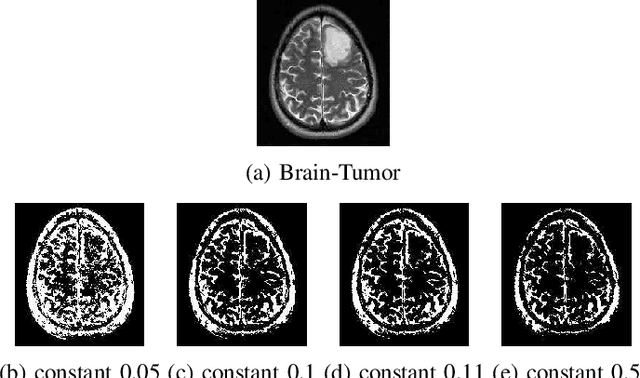
Image segmentation refers to the separation of objects from the background, and has been one of the most challenging aspects of digital image processing. Practically it is impossible to design a segmentation algorithm which has 100% accuracy, and therefore numerous segmentation techniques have been proposed in the literature, each with certain limitations. In this paper, a novel Falling-Ball algorithm is presented, which is a region-based segmentation algorithm, and an alternative to watershed transform (based on waterfall model). The proposed algorithm detects the catchment basins by assuming that a ball falling from hilly terrains will stop in a catchment basin. Once catchment basins are identified, the association of each pixel with one of the catchment basin is obtained using multi-criterion fuzzy logic. Edges are constructed by dividing image into different catchment basins with the help of a membership function. Finally closed contour algorithm is applied to find closed regions and objects within closed regions are segmented using intensity information. The performance of the proposed algorithm is evaluated both objectively as well as subjectively. Simulation results show that the proposed algorithms gives superior performance over conventional Sobel edge detection methods and the watershed segmentation algorithm. For comparative analysis, various comparison methods are used for demonstrating the superiority of proposed methods over existing segmentation methods.
Depth-Map Generation using Pixel Matching in Stereoscopic Pair of Images
Feb 12, 2019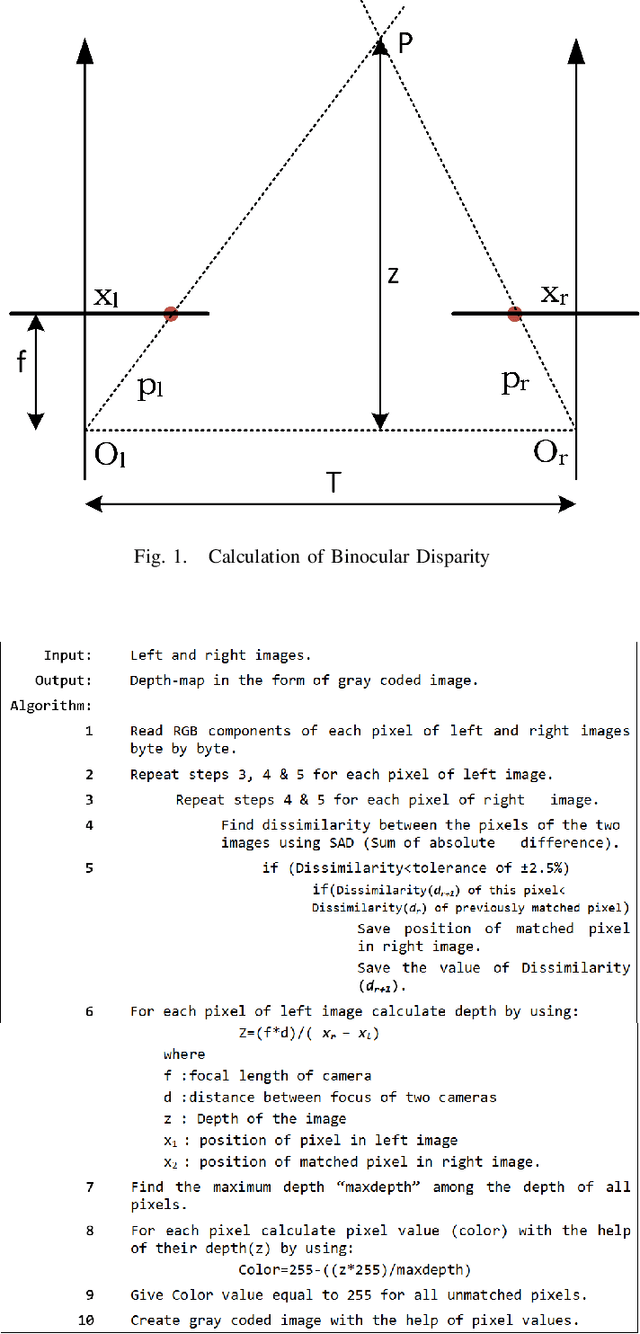


Modern day multimedia content generation and dissemination is moving towards the presentation of more and more `realistic' scenarios. The switch from 2-dimensional (2D) to 3-dimensional (3D) has been a major driving force in that direction. Over the recent past, a large number of approaches have been proposed for creating 3D images/videos most of which are based on the generation of depth-maps. This paper presents a new algorithm for obtaining depth information pertaining to a depicted scene from a set of available pair of stereoscopic images. The proposed algorithm performs a pixel-to-pixel matching of the two images in the stereo pair for estimation of depth. It is shown that the obtained depth-maps show improvements over the reported counterparts.