Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Deterministic Policy Improvement Stabilizes Approximated Reinforcement Learning
Paper and Code
Dec 22, 2016
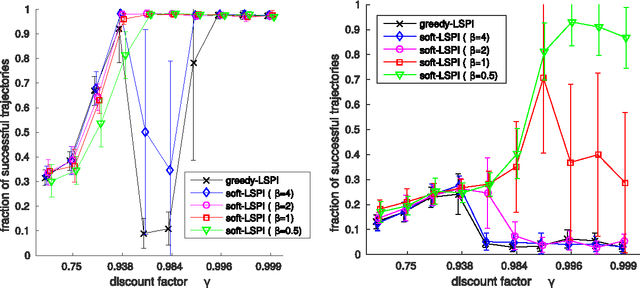
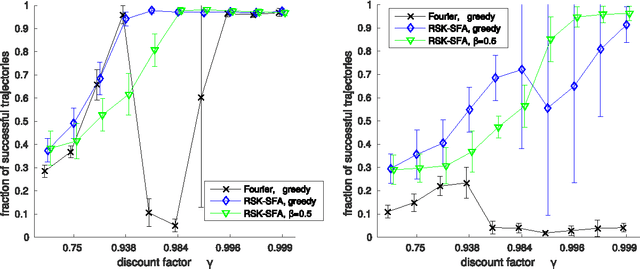
This paper investigates a type of instability that is linked to the greedy policy improvement in approximated reinforcement learning. We show empirically that non-deterministic policy improvement can stabilize methods like LSPI by controlling the improvements' stochasticity. Additionally we show that a suitable representation of the value function also stabilizes the solution to some degree. The presented approach is simple and should also be easily transferable to more sophisticated algorithms like deep reinforcement learning.
* This paper has been presented at the 13th European Workshop on
Reinforcement Learning (EWRL 2016) on the 3rd and 4th of December 2016 in
Barcelona, Spain
View paper on