 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward and Reverse Gradient-Based Hyperparameter Optimization
Paper and Code
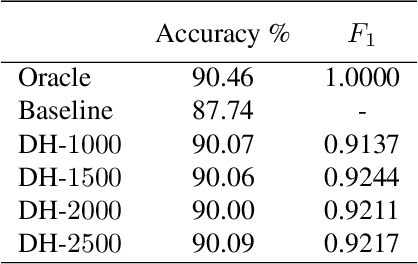
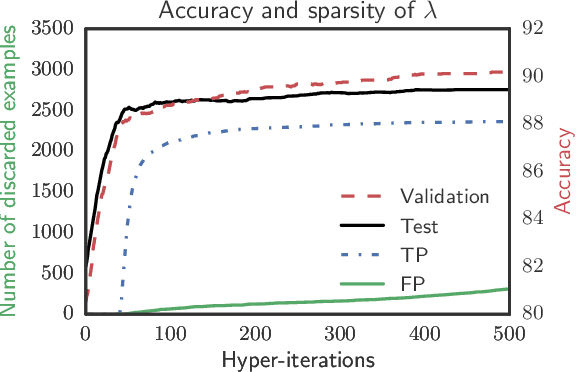
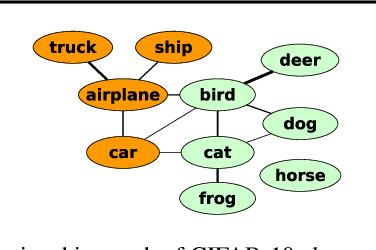
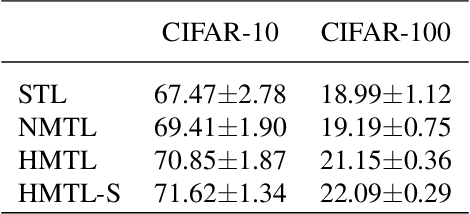
We study two procedures (reverse-mode and forward-mode) for computing the gradient of the validation error with respect to the hyperparameters of any iterative learning algorithm such as stochastic gradient descent. These procedures mirror two methods of computing gradients for recurrent neural networks and have different trade-offs in terms of running time and space requirements. Our formulation of the reverse-mode procedure is linked to previous work by Maclaurin et al. [2015] but does not require reversible dynamics. The forward-mode procedure is suitable for real-time hyperparameter updates, which may significantly speed up hyperparameter optimization on large datasets. We present experiments on data cleaning and on learning task interactions. We also present one large-scale experiment where the use of previous gradient-based methods would be prohibitive.