 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVA: Dataset Derivative of a Learning Task
Nov 18, 2021
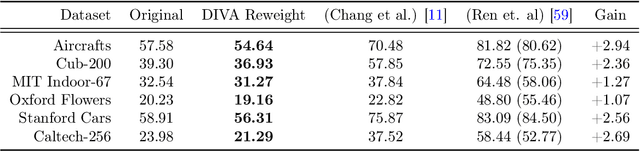

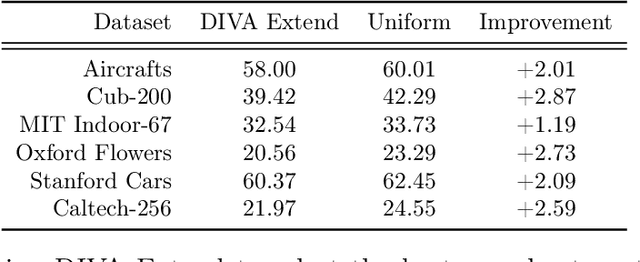
We present a method to compute the derivative of a learning task with respect to a dataset. A learning task is a function from a training set to the validation error, which can be represented by a trained deep neural network (DNN). The "dataset derivative" is a linear operator, computed around the trained model, that informs how perturbations of the weight of each training sample affect the validation error, usually computed on a separate validation dataset. Our method, DIVA (Differentiable Validation) hinges on a closed-form differentiable expression of the leave-one-out cross-validation error around a pre-trained DNN. Such expression constitutes the dataset derivative. DIVA could be used for dataset auto-curation, for example removing samples with faulty annotations, augmenting a dataset with additional relevant samples, or rebalancing. More generally, DIVA can be used to optimize the dataset, along with the parameters of the model, as part of the training process without the need for a separate validation dataset, unlike bi-level optimization methods customary in AutoML. To illustrate the flexibility of DIVA, we report experiments on sample auto-curation tasks such as outlier rejection, dataset extension, and automatic aggregation of multi-modal data.
Representation Consolidation for Training Expert Students
Jul 16, 2021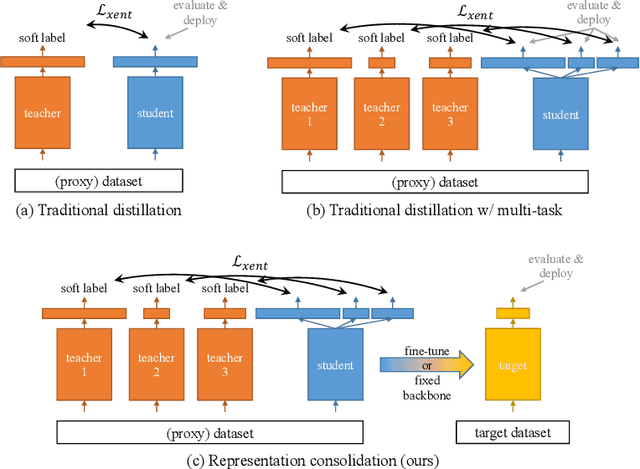

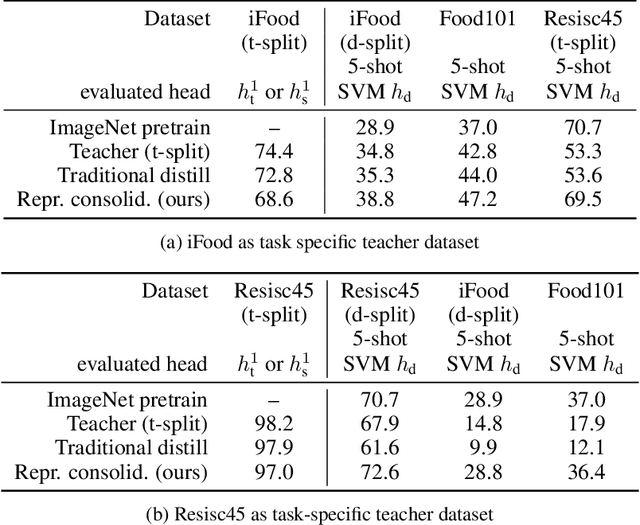

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).
Revisiting Contrastive Learning for Few-Shot Classification
Jan 26, 2021
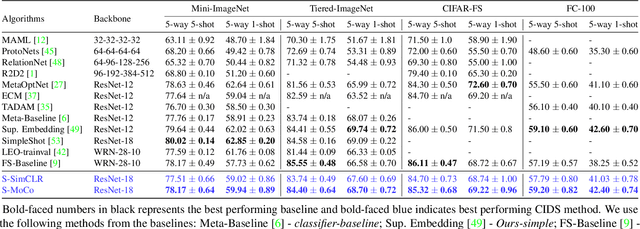
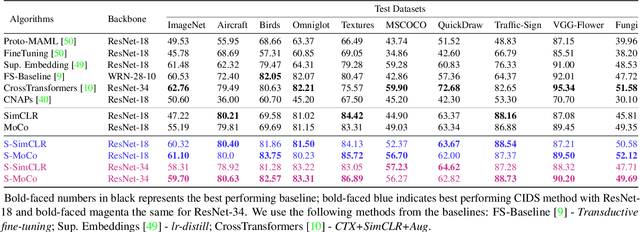
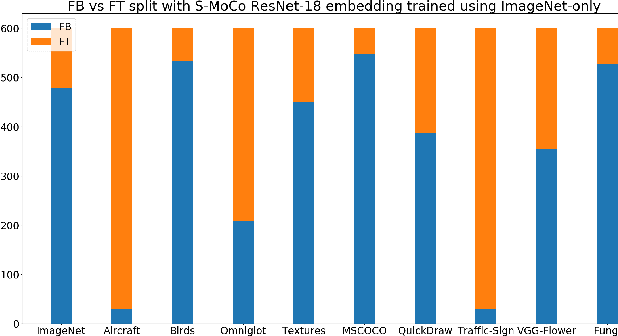
Instance discrimination based contrastive learning has emerged as a leading approach for self-supervised learning of visual representations. Yet, its generalization to novel tasks remains elusive when compared to representations learned with supervision, especially in the few-shot setting. We demonstrate how one can incorporate supervision in the instance discrimination based contrastive self-supervised learning framework to learn representations that generalize better to novel tasks. We call our approach CIDS (Contrastive Instance Discrimination with Supervision). CIDS performs favorably compared to existing algorithms on popular few-shot benchmarks like Mini-ImageNet or Tiered-ImageNet. We also propose a novel model selection algorithm that can be used in conjunction with a universal embedding trained using CIDS to outperform state-of-the-art algorithms on the challenging Meta-Dataset benchmark.
Mixed-Privacy Forgetting in Deep Networks
Dec 24, 2020


We show that the influence of a subset of the training samples can be removed -- or "forgotten" -- from the weights of a network trained on large-scale image classification tasks, and we provide strong computable bounds on the amount of remaining information after forgetting. Inspired by real-world applications of forgetting techniques, we introduce a novel notion of forgetting in mixed-privacy setting, where we know that a "core" subset of the training samples does not need to be forgotten. While this variation of the problem is conceptually simple, we show that working in this setting significantly improves the accuracy and guarantees of forgetting methods applied to vision classification tasks. Moreover, our method allows efficient removal of all information contained in non-core data by simply setting to zero a subset of the weights with minimal loss in performance. We achieve these results by replacing a standard deep network with a suitable linear approximation. With opportune changes to the network architecture and training procedure, we show that such linear approximation achieves comparable performance to the original network and that the forgetting problem becomes quadratic and can be solved efficiently even for large models. Unlike previous forgetting methods on deep networks, ours can achieve close to the state-of-the-art accuracy on large scale vision tasks. In particular, we show that our method allows forgetting without having to trade off the model accuracy.
LQF: Linear Quadratic Fine-Tuning
Dec 21, 2020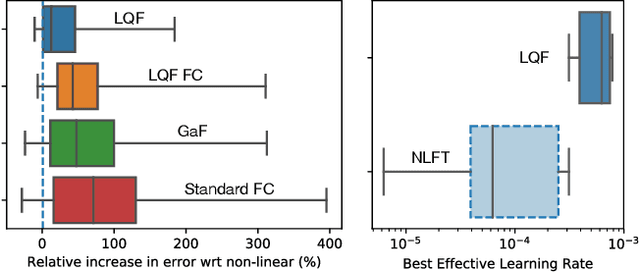

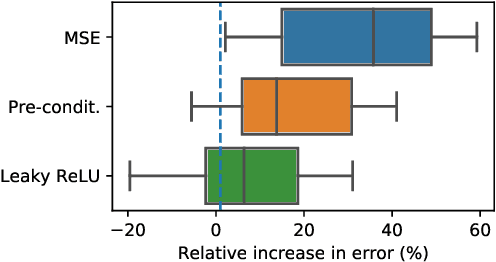
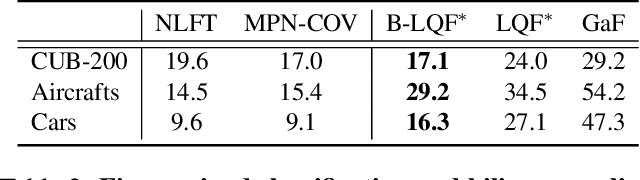
Classifiers that are linear in their parameters, and trained by optimizing a convex loss function, have predictable behavior with respect to changes in the training data, initial conditions, and optimization. Such desirable properties are absent in deep neural networks (DNNs), typically trained by non-linear fine-tuning of a pre-trained model. Previous attempts to linearize DNNs have led to interesting theoretical insights, but have not impacted the practice due to the substantial performance gap compared to standard non-linear optimization. We present the first method for linearizing a pre-trained model that achieves comparable performance to non-linear fine-tuning on most of real-world image classification tasks tested, thus enjoying the interpretability of linear models without incurring punishing losses in performance. LQF consists of simple modifications to the architecture, loss function and optimization typically used for classification: Leaky-ReLU instead of ReLU, mean squared loss instead of cross-entropy, and pre-conditioning using Kronecker factorization. None of these changes in isolation is sufficient to approach the performance of non-linear fine-tuning. When used in combination, they allow us to reach comparable performance, and even superior in the low-data regime, while enjoying the simplicity, robustness and interpretability of linear-quadratic optimization.