 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMERA: Computing- and Memory-Efficient Training via Rank-Adaptive Tensor Optimization
May 23, 2024



Training large AI models such as deep learning recommendation systems and foundation language (or multi-modal) models costs massive GPUs and computing time. The high training cost has become only affordable to big tech companies, meanwhile also causing increasing concerns about the environmental impact. This paper presents CoMERA, a Computing- and Memory-Efficient training method via Rank-Adaptive tensor optimization. CoMERA achieves end-to-end rank-adaptive tensor-compressed training via a multi-objective optimization formulation, and improves the training to provide both a high compression ratio and excellent accuracy in the training process. Our optimized numerical computation (e.g., optimized tensorized embedding and tensor-vector contractions) and GPU implementation eliminate part of the run-time overhead in the tensorized training on GPU. This leads to, for the first time, $2-3\times$ speedup per training epoch compared with standard training. CoMERA also outperforms the recent GaLore in terms of both memory and computing efficiency. Specifically, CoMERA is $2\times$ faster per training epoch and $9\times$ more memory-efficient than GaLore on a tested six-encoder transformer with single-batch training. With further HPC optimization, CoMERA may significantly reduce the training cost of large language models.
Quantization-Aware and Tensor-Compressed Training of Transformers for Natural Language Understanding
Jun 01, 2023Fine-tuned transformer models have shown superior performances in many natural language tasks. However, the large model size prohibits deploying high-performance transformer models on resource-constrained devices. This paper proposes a quantization-aware tensor-compressed training approach to reduce the model size, arithmetic operations, and ultimately runtime latency of transformer-based models. We compress the embedding and linear layers of transformers into small low-rank tensor cores, which significantly reduces model parameters. A quantization-aware training with learnable scale factors is used to further obtain low-precision representations of the tensor-compressed models. The developed approach can be used for both end-to-end training and distillation-based training. To improve the convergence, a layer-by-layer distillation is applied to distill a quantized and tensor-compressed student model from a pre-trained transformer. The performance is demonstrated in two natural language understanding tasks, showing up to $63\times$ compression ratio, little accuracy loss and remarkable inference and training speedup.
End-to-End Spoken Language Understanding for Generalized Voice Assistants
Jun 16, 2021
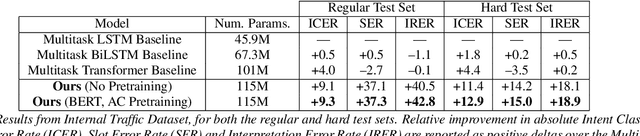

End-to-end (E2E) spoken language understanding (SLU) systems predict utterance semantics directly from speech using a single model. Previous work in this area has focused on targeted tasks in fixed domains, where the output semantic structure is assumed a priori and the input speech is of limited complexity. In this work we present our approach to developing an E2E model for generalized SLU in commercial voice assistants (VAs). We propose a fully differentiable, transformer-based, hierarchical system that can be pretrained at both the ASR and NLU levels. This is then fine-tuned on both transcription and semantic classification losses to handle a diverse set of intent and argument combinations. This leads to an SLU system that achieves significant improvements over baselines on a complex internal generalized VA dataset with a 43% improvement in accuracy, while still meeting the 99% accuracy benchmark on the popular Fluent Speech Commands dataset. We further evaluate our model on a hard test set, exclusively containing slot arguments unseen in training, and demonstrate a nearly 20% improvement, showing the efficacy of our approach in truly demanding VA scenarios.
Extreme Model Compression for On-device Natural Language Understanding
Nov 30, 2020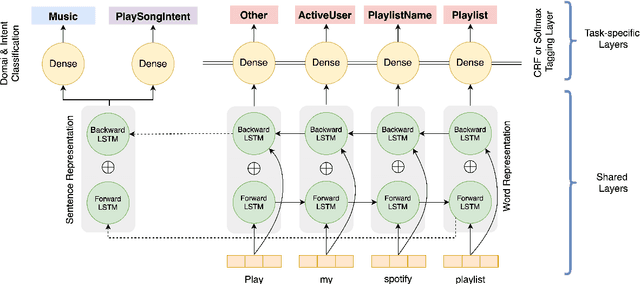
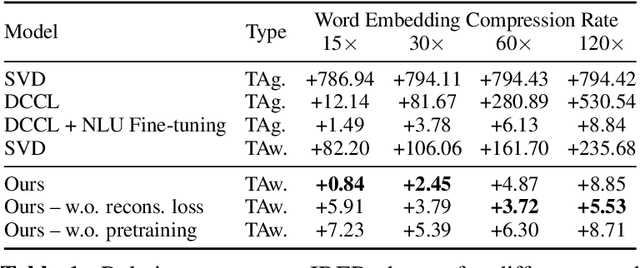
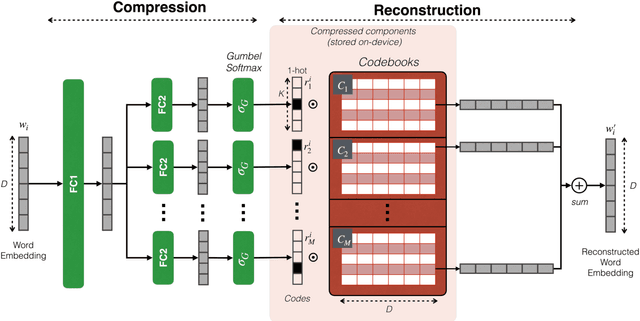
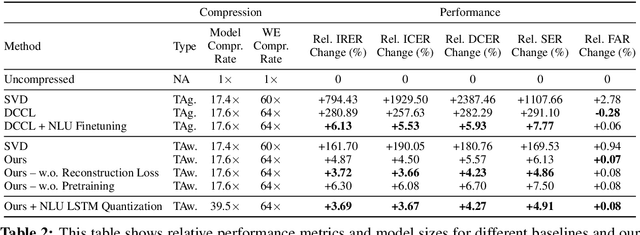
In this paper, we propose and experiment with techniques for extreme compression of neural natural language understanding (NLU) models, making them suitable for execution on resource-constrained devices. We propose a task-aware, end-to-end compression approach that performs word-embedding compression jointly with NLU task learning. We show our results on a large-scale, commercial NLU system trained on a varied set of intents with huge vocabulary sizes. Our approach outperforms a range of baselines and achieves a compression rate of 97.4% with less than 3.7% degradation in predictive performance. Our analysis indicates that the signal from the downstream task is important for effective compression with minimal degradation in performance.
Tie Your Embeddings Down: Cross-Modal Latent Spaces for End-to-end Spoken Language Understanding
Nov 18, 2020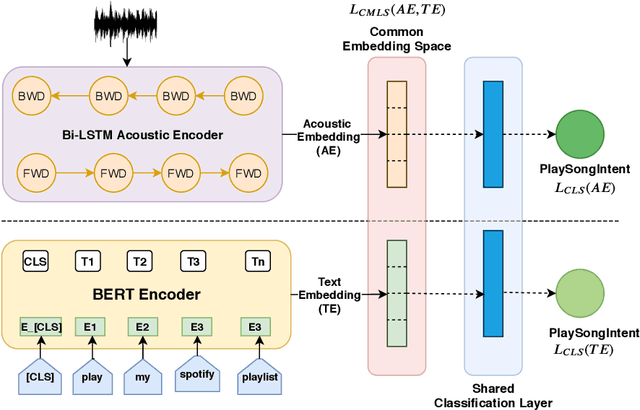

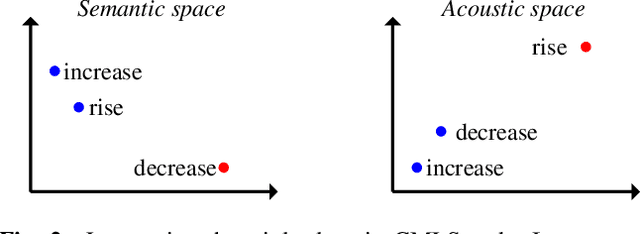

End-to-end (E2E) spoken language understanding (SLU) systems can infer the semantics of a spoken utterance directly from an audio signal. However, training an E2E system remains a challenge, largely due to the scarcity of paired audio-semantics data. In this paper, we treat an E2E system as a multi-modal model, with audio and text functioning as its two modalities, and use a cross-modal latent space (CMLS) architecture, where a shared latent space is learned between the `acoustic' and `text' embeddings. We propose using different multi-modal losses to explicitly guide the acoustic embeddings to be closer to the text embeddings, obtained from a semantically powerful pre-trained BERT model. We train the CMLS model on two publicly available E2E datasets, across different cross-modal losses and show that our proposed triplet loss function achieves the best performance. It achieves a relative improvement of 1.4% and 4% respectively over an E2E model without a cross-modal space and a relative improvement of 0.7% and 1% over a previously published CMLS model using $L_2$ loss. The gains are higher for a smaller, more complicated E2E dataset, demonstrating the efficacy of using an efficient cross-modal loss function, especially when there is limited E2E training data available.
Semantic Complexity in End-to-End Spoken Language Understanding
Aug 06, 2020


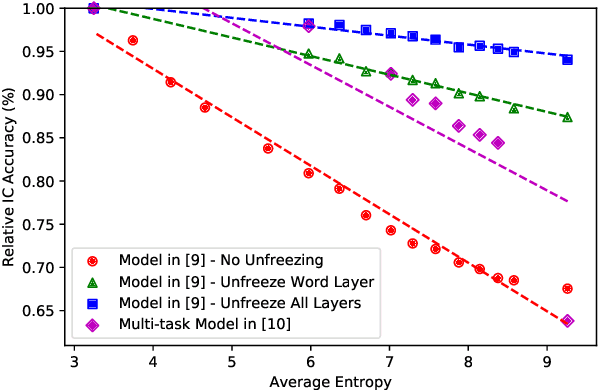
End-to-end spoken language understanding (SLU) models are a class of model architectures that predict semantics directly from speech. Because of their input and output types, we refer to them as speech-to-interpretation (STI) models. Previous works have successfully applied STI models to targeted use cases, such as recognizing home automation commands, however no study has yet addressed how these models generalize to broader use cases. In this work, we analyze the relationship between the performance of STI models and the difficulty of the use case to which they are applied. We introduce empirical measures of dataset semantic complexity to quantify the difficulty of the SLU tasks. We show that near-perfect performance metrics for STI models reported in the literature were obtained with datasets that have low semantic complexity values. We perform experiments where we vary the semantic complexity of a large, proprietary dataset and show that STI model performance correlates with our semantic complexity measures, such that performance increases as complexity values decrease. Our results show that it is important to contextualize an STI model's performance with the complexity values of its training dataset to reveal the scope of its applicability.
Linguistic Markers of Influence in Informal Interactions
Jul 14, 2017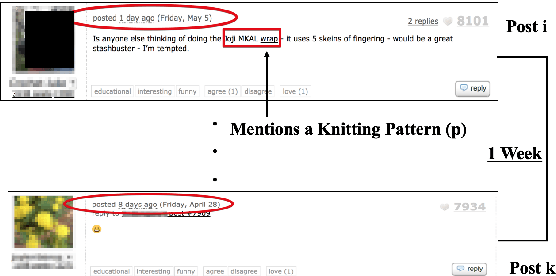
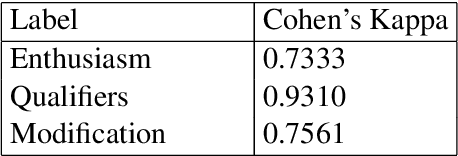
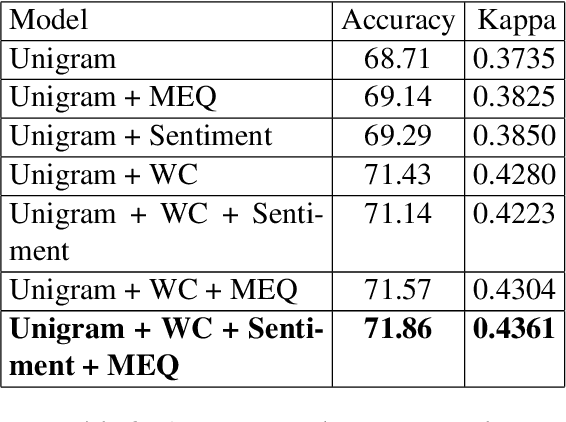
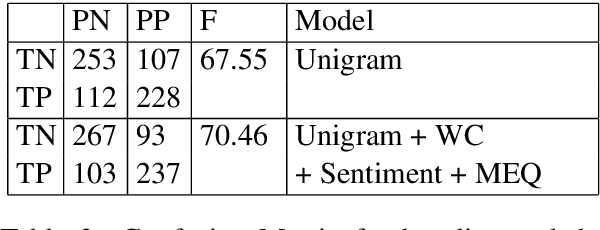
There has been a long standing interest in understanding `Social Influence' both in Social Sciences and in Computational Linguistics. In this paper, we present a novel approach to study and measure interpersonal influence in daily interactions. Motivated by the basic principles of influence, we attempt to identify indicative linguistic features of the posts in an online knitting community. We present the scheme used to operationalize and label the posts with indicator features. Experiments with the identified features show an improvement in the classification accuracy of influence by 3.15%. Our results illustrate the important correlation between the characteristics of the language and its potential to influence others.