 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Spoken Language Understanding for Generalized Voice Assistants
Jun 16, 2021
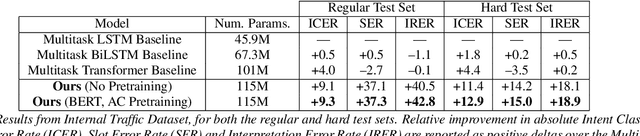

End-to-end (E2E) spoken language understanding (SLU) systems predict utterance semantics directly from speech using a single model. Previous work in this area has focused on targeted tasks in fixed domains, where the output semantic structure is assumed a priori and the input speech is of limited complexity. In this work we present our approach to developing an E2E model for generalized SLU in commercial voice assistants (VAs). We propose a fully differentiable, transformer-based, hierarchical system that can be pretrained at both the ASR and NLU levels. This is then fine-tuned on both transcription and semantic classification losses to handle a diverse set of intent and argument combinations. This leads to an SLU system that achieves significant improvements over baselines on a complex internal generalized VA dataset with a 43% improvement in accuracy, while still meeting the 99% accuracy benchmark on the popular Fluent Speech Commands dataset. We further evaluate our model on a hard test set, exclusively containing slot arguments unseen in training, and demonstrate a nearly 20% improvement, showing the efficacy of our approach in truly demanding VA scenarios.
Semantic Complexity in End-to-End Spoken Language Understanding
Aug 06, 2020


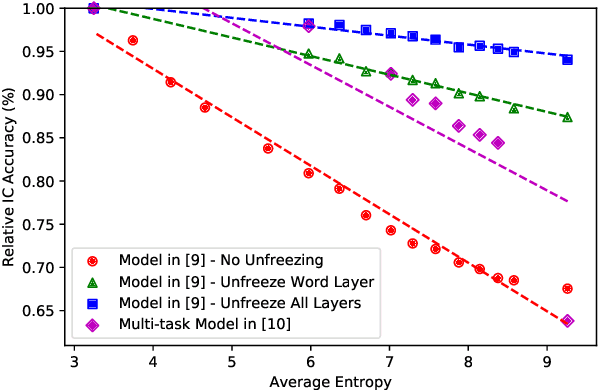
End-to-end spoken language understanding (SLU) models are a class of model architectures that predict semantics directly from speech. Because of their input and output types, we refer to them as speech-to-interpretation (STI) models. Previous works have successfully applied STI models to targeted use cases, such as recognizing home automation commands, however no study has yet addressed how these models generalize to broader use cases. In this work, we analyze the relationship between the performance of STI models and the difficulty of the use case to which they are applied. We introduce empirical measures of dataset semantic complexity to quantify the difficulty of the SLU tasks. We show that near-perfect performance metrics for STI models reported in the literature were obtained with datasets that have low semantic complexity values. We perform experiments where we vary the semantic complexity of a large, proprietary dataset and show that STI model performance correlates with our semantic complexity measures, such that performance increases as complexity values decrease. Our results show that it is important to contextualize an STI model's performance with the complexity values of its training dataset to reveal the scope of its applicability.