Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Model Compression for On-device Natural Language Understanding
Nov 30, 2020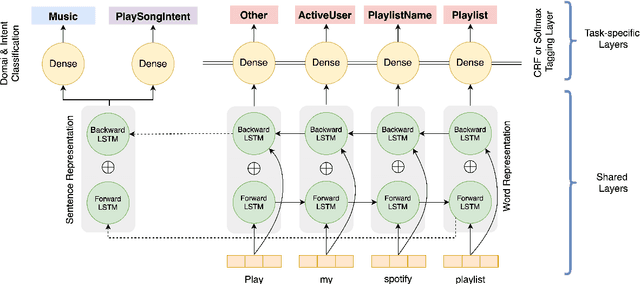
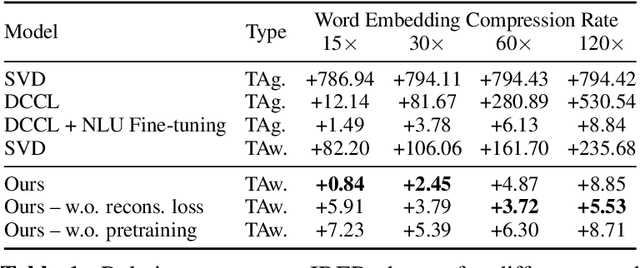
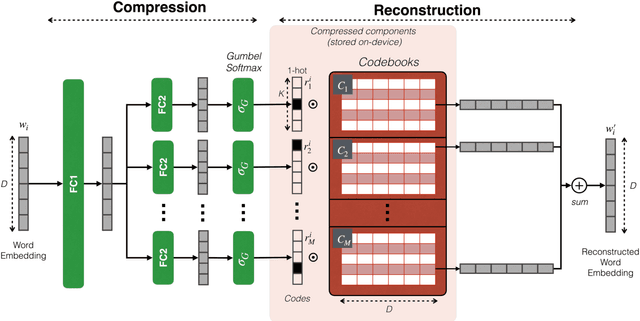
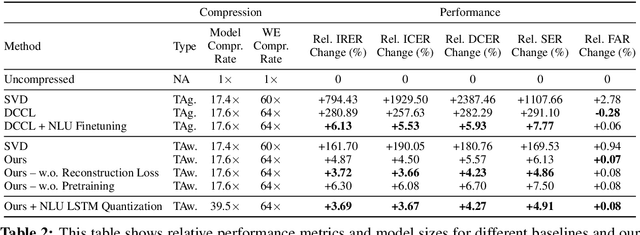
In this paper, we propose and experiment with techniques for extreme compression of neural natural language understanding (NLU) models, making them suitable for execution on resource-constrained devices. We propose a task-aware, end-to-end compression approach that performs word-embedding compression jointly with NLU task learning. We show our results on a large-scale, commercial NLU system trained on a varied set of intents with huge vocabulary sizes. Our approach outperforms a range of baselines and achieves a compression rate of 97.4% with less than 3.7% degradation in predictive performance. Our analysis indicates that the signal from the downstream task is important for effective compression with minimal degradation in performance.
* Long paper at COLING 2020
Via