 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRNN: Innovation-driven Recurrent Neural Network for Time-Series Data Modeling and Prediction
May 09, 2025Many real-world datasets are time series that are sequentially collected and contain rich temporal information. Thus, a common interest in practice is to capture dynamics of time series and predict their future evolutions. To this end, the recurrent neural network (RNN) has been a prevalent and effective machine learning option, which admits a nonlinear state-space model representation. Motivated by the resemblance between RNN and Kalman filter (KF) for linear state-space models, we propose in this paper Innovation-driven RNN (IRNN), a novel RNN architecture tailored to time-series data modeling and prediction tasks. By adapting the concept of "innovation" from KF to RNN, past prediction errors are adopted as additional input signals to update hidden states of RNN and boost prediction performance. Since innovation data depend on network parameters, existing training algorithms for RNN do not apply to IRNN straightforwardly. Thus, a tailored training algorithm dubbed input updating-based back-propagation through time (IU-BPTT) is further proposed, which alternates between updating innovations and optimizing network parameters via gradient descent. Experiments on real-world benchmark datasets show that the integration of innovations into various forms of RNN leads to remarkably improved prediction accuracy of IRNN without increasing the training cost substantially.
Towards An Unsupervised Learning Scheme for Efficiently Solving Parameterized Mixed-Integer Programs
Dec 24, 2024In this paper, we describe a novel unsupervised learning scheme for accelerating the solution of a family of mixed integer programming (MIP) problems. Distinct substantially from existing learning-to-optimize methods, our proposal seeks to train an autoencoder (AE) for binary variables in an unsupervised learning fashion, using data of optimal solutions to historical instances for a parametric family of MIPs. By a deliberate design of AE architecture and exploitation of its statistical implication, we present a simple and straightforward strategy to construct a class of cutting plane constraints from the decoder parameters of an offline-trained AE. These constraints reliably enclose the optimal binary solutions of new problem instances thanks to the representation strength of the AE. More importantly, their integration into the primal MIP problem leads to a tightened MIP with the reduced feasible region, which can be resolved at decision time using off-the-shelf solvers with much higher efficiency. Our method is applied to a benchmark batch process scheduling problem formulated as a mixed integer linear programming (MILP) problem. Comprehensive results demonstrate that our approach significantly reduces the computational cost of off-the-shelf MILP solvers while retaining a high solution quality. The codes of this work are open-sourced at https://github.com/qushiyuan/AE4BV.
Unraveling and Mitigating Safety Alignment Degradation of Vision-Language Models
Oct 11, 2024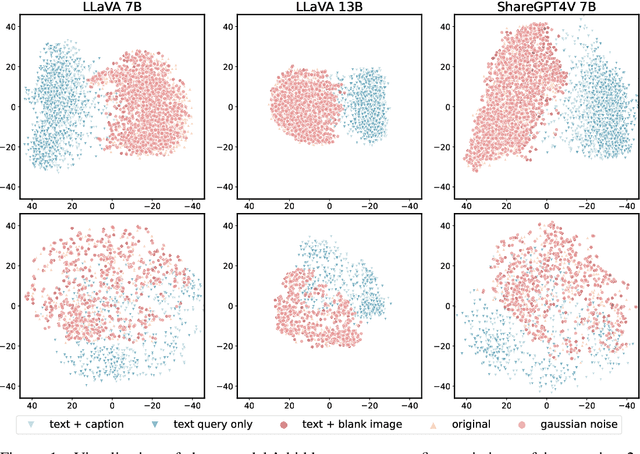
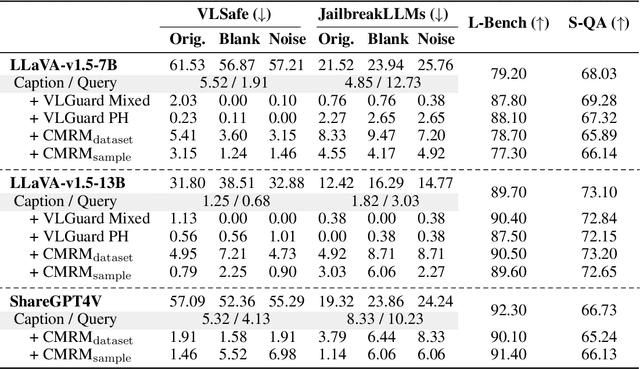
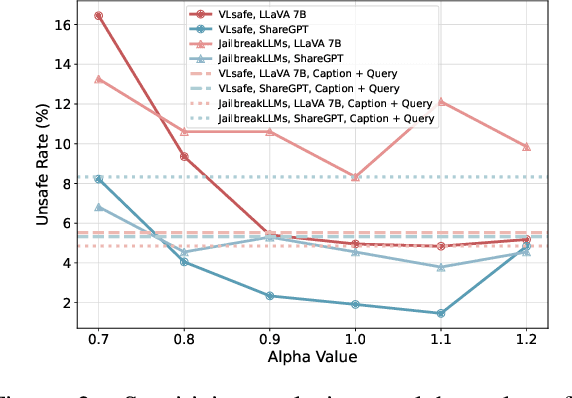

The safety alignment ability of Vision-Language Models (VLMs) is prone to be degraded by the integration of the vision module compared to its LLM backbone. We investigate this phenomenon, dubbed as ''safety alignment degradation'' in this paper, and show that the challenge arises from the representation gap that emerges when introducing vision modality to VLMs. In particular, we show that the representations of multi-modal inputs shift away from that of text-only inputs which represent the distribution that the LLM backbone is optimized for. At the same time, the safety alignment capabilities, initially developed within the textual embedding space, do not successfully transfer to this new multi-modal representation space. To reduce safety alignment degradation, we introduce Cross-Modality Representation Manipulation (CMRM), an inference time representation intervention method for recovering the safety alignment ability that is inherent in the LLM backbone of VLMs, while simultaneously preserving the functional capabilities of VLMs. The empirical results show that our framework significantly recovers the alignment ability that is inherited from the LLM backbone with minimal impact on the fluency and linguistic capabilities of pre-trained VLMs even without additional training. Specifically, the unsafe rate of LLaVA-7B on multi-modal input can be reduced from 61.53% to as low as 3.15% with only inference-time intervention. WARNING: This paper contains examples of toxic or harmful language.
From Instructions to Constraints: Language Model Alignment with Automatic Constraint Verification
Mar 10, 2024User alignment is crucial for adapting general-purpose language models (LMs) to downstream tasks, but human annotations are often not available for all types of instructions, especially those with customized constraints. We observe that user instructions typically contain constraints. While assessing response quality in terms of the whole instruction is often costly, efficiently evaluating the satisfaction rate of constraints is feasible. We investigate common constraints in NLP tasks, categorize them into three classes based on the types of their arguments, and propose a unified framework, ACT (Aligning to ConsTraints), to automatically produce supervision signals for user alignment with constraints. Specifically, ACT uses constraint verifiers, which are typically easy to implement in practice, to compute constraint satisfaction rate (CSR) of each response. It samples multiple responses for each prompt and collect preference labels based on their CSR automatically. Subsequently, ACT adapts the LM to the target task through a ranking-based learning process. Experiments on fine-grained entity typing, abstractive summarization, and temporal question answering show that ACT is able to enhance LMs' capability to adhere to different classes of constraints, thereby improving task performance. Further experiments show that the constraint-following capabilities are transferable.
Diable: Efficient Dialogue State Tracking as Operations on Tables
May 26, 2023Sequence-to-sequence state-of-the-art systems for dialogue state tracking (DST) use the full dialogue history as input, represent the current state as a list with all the slots, and generate the entire state from scratch at each dialogue turn. This approach is inefficient, especially when the number of slots is large and the conversation is long. In this paper, we propose Diable, a new task formalisation that simplifies the design and implementation of efficient DST systems and allows one to easily plug and play large language models. We represent the dialogue state as a table and formalise DST as a table manipulation task. At each turn, the system updates the previous state by generating table operations based on the dialogue context. Extensive experimentation on the MultiWoz datasets demonstrates that Diable (i) outperforms strong efficient DST baselines, (ii) is 2.4x more time efficient than current state-of-the-art methods while retaining competitive Joint Goal Accuracy, and (iii) is robust to noisy data annotations due to the table operations approach.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022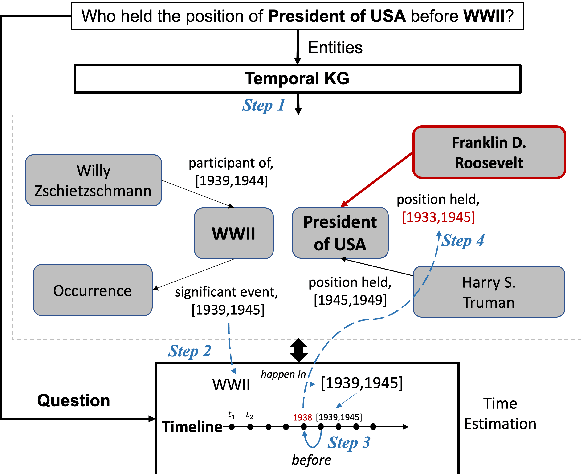
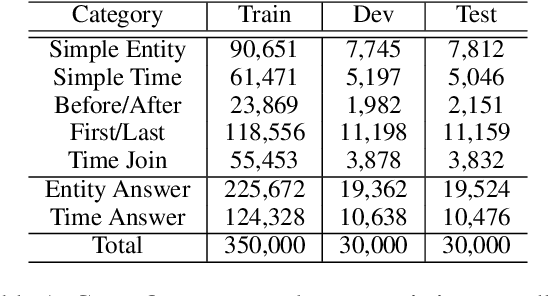
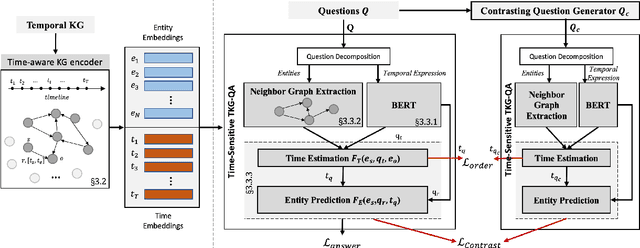
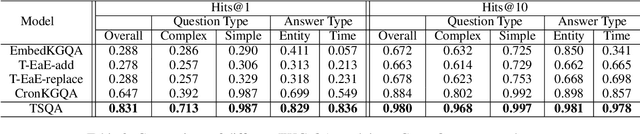
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
Discrete Graph Structure Learning for Forecasting Multiple Time Series
Feb 15, 2021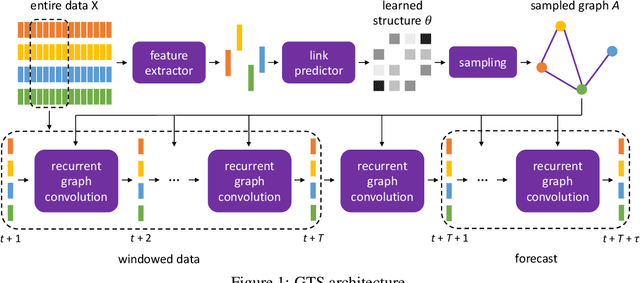

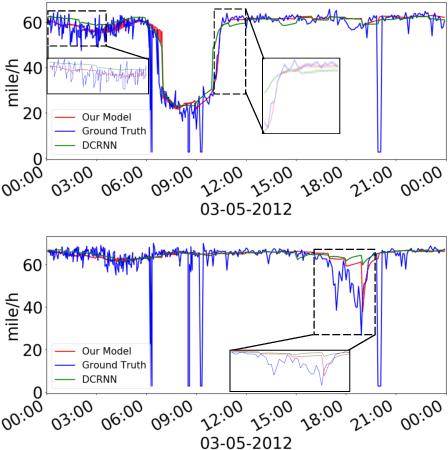

Time series forecasting is an extensively studied subject in statistics, economics, and computer science. Exploration of the correlation and causation among the variables in a multivariate time series shows promise in enhancing the performance of a time series model. When using deep neural networks as forecasting models, we hypothesize that exploiting the pairwise information among multiple (multivariate) time series also improves their forecast. If an explicit graph structure is known, graph neural networks (GNNs) have been demonstrated as powerful tools to exploit the structure. In this work, we propose learning the structure simultaneously with the GNN if the graph is unknown. We cast the problem as learning a probabilistic graph model through optimizing the mean performance over the graph distribution. The distribution is parameterized by a neural network so that discrete graphs can be sampled differentiably through reparameterization. Empirical evaluations show that our method is simpler, more efficient, and better performing than a recently proposed bilevel learning approach for graph structure learning, as well as a broad array of forecasting models, either deep or non-deep learning based, and graph or non-graph based.
Posteriori Probabilistic Bounds of Convex Scenario Programs with Validation Tests
Mar 27, 2019
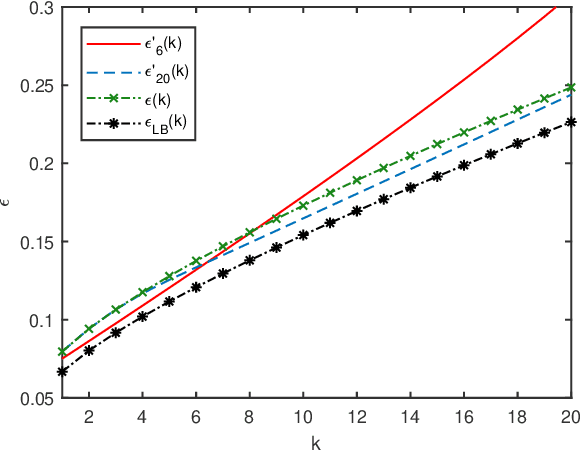
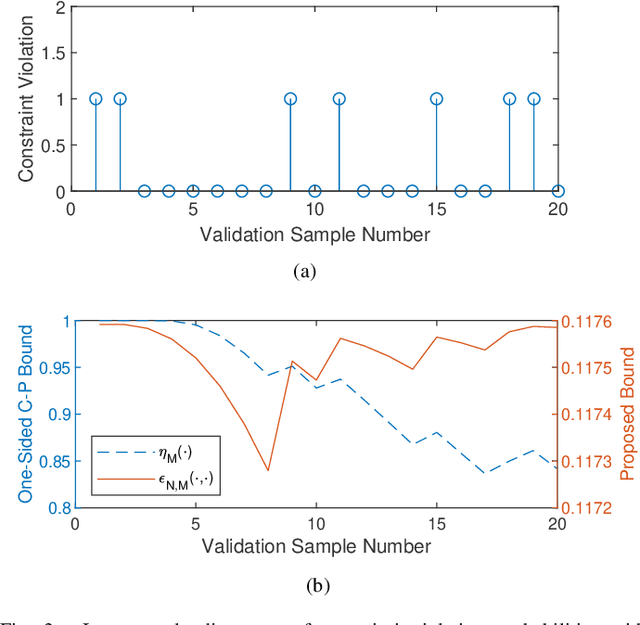
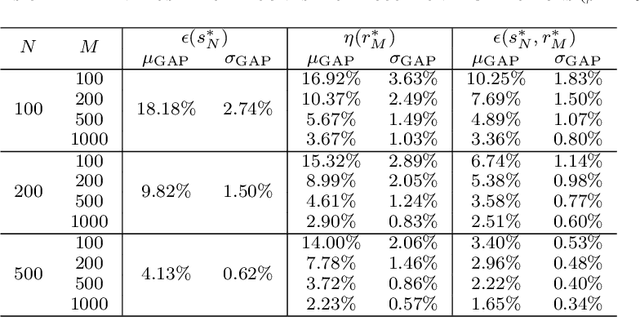
Scenario programs have established themselves as efficient tools towards decision-making under uncertainty. To assess the quality of scenario-based solutions a posteriori, validation tests based on Bernoulli trials have been widely adopted in practice. However, to reach a theoretically reliable conclusion, one typically needs to collect massive validation samples. In this work, we propose new posteriori bounds for convex scenario programs with validation tests, which are dependent on both realizations of support constraints and performance on out-of-sample validation data. The proposed bounds enjoy wide generality in that many existing theoretical results can be incorporated as particular cases. To facilitate practical use, a systematic approach for parameterizing posteriori probability functions is also developed, which is shown to possess a variety of desirable properties allowing for easy implementations and clear interpretations. By synthesizing information about support constraints and validation tests, less conservative estimates of reliability levels can be attained for randomized solutions in comparison with existing posteriori bounds. Case studies on controller design of aircraft lateral motion are presented to validate the effectiveness of the proposed posteriori bounds.
End-to-end Structure-Aware Convolutional Networks for Knowledge Base Completion
Nov 15, 2018


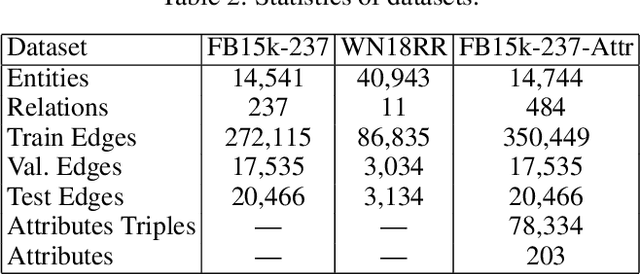
Knowledge graph embedding has been an active research topic for knowledge base completion, with progressive improvement from the initial TransE, TransH, DistMult et al to the current state-of-the-art ConvE. ConvE uses 2D convolution over embeddings and multiple layers of nonlinear features to model knowledge graphs. The model can be efficiently trained and scalable to large knowledge graphs. However, there is no structure enforcement in the embedding space of ConvE. The recent graph convolutional network (GCN) provides another way of learning graph node embedding by successfully utilizing graph connectivity structure. In this work, we propose a novel end-to-end Structure-Aware Convolutional Network (SACN) that takes the benefit of GCN and ConvE together. SACN consists of an encoder of a weighted graph convolutional network (WGCN), and a decoder of a convolutional network called Conv-TransE. WGCN utilizes knowledge graph node structure, node attributes and edge relation types. It has learnable weights that adapt the amount of information from neighbors used in local aggregation, leading to more accurate embeddings of graph nodes. Node attributes in the graph are represented as additional nodes in the WGCN. The decoder Conv-TransE enables the state-of-the-art ConvE to be translational between entities and relations while keeps the same link prediction performance as ConvE. We demonstrate the effectiveness of the proposed SACN on standard FB15k-237 and WN18RR datasets, and it gives about 10% relative improvement over the state-of-the-art ConvE in terms of HITS@1, HITS@3 and HITS@10.
Edge Attention-based Multi-Relational Graph Convolutional Networks
May 20, 2018
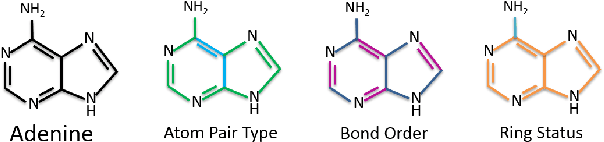
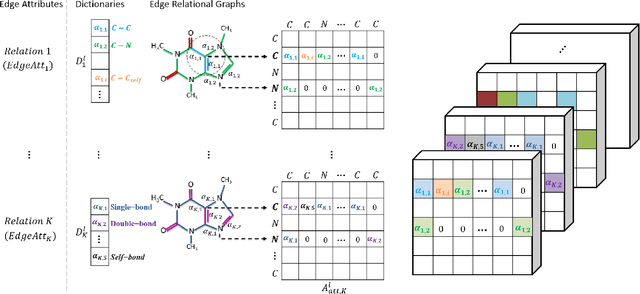
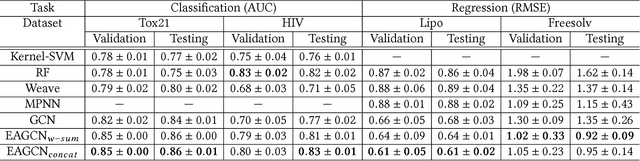
Graph convolutional network (GCN) is generalization of convolutional neural network (CNN) to work with arbitrarily structured graphs. A binary adjacency matrix is commonly used in training a GCN. Recently, the attention mechanism allows the network to learn a dynamic and adaptive aggregation of the neighborhood. We propose a new GCN model on the graphs where edges are characterized in multiple views or precisely in terms of multiple relationships. For instance, in chemical graph theory, compound structures are often represented by the hydrogen-depleted molecular graph where nodes correspond to atoms and edges correspond to chemical bonds. Multiple attributes can be important to characterize chemical bonds, such as atom pair (the types of atoms that a bond connects), aromaticity, and whether a bond is in a ring. The different attributes lead to different graph representations for the same molecule. There is growing interests in both chemistry and machine learning fields to directly learn molecular properties of compounds from the molecular graph, instead of from fingerprints predefined by chemists. The proposed GCN model, which we call edge attention-based multi-relational GCN (EAGCN), jointly learns attention weights and node features in graph convolution. For each bond attribute, a real-valued attention matrix is used to replace the binary adjacency matrix. By designing a dictionary for the edge attention, and forming the attention matrix of each molecule by looking up the dictionary, the EAGCN exploits correspondence between bonds in different molecules. The prediction of compound properties is based on the aggregated node features, which is independent of the varying molecule (graph) size. We demonstrate the efficacy of the EAGCN on multiple chemical datasets: Tox21, HIV, Freesolv, and Lipophilicity, and interpret the resultant attention weights.