 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Reinforcement Learning-based Process Synthesis via Quantum Computing
May 20, 2026In this work, we present quantum reinforcement learning (RL) as a solution strategy for process synthesis problems. Building on our prior work, we develop a generalized framework that formally poses process synthesis as a Markov decision process and introduces quantum-enhanced RL algorithms to solve it with improved scalability. Earlier implementations of quantum-based RL for process synthesis were limited by qubit requirements, which scaled poorly with problem complexity. This work overcomes this challenge by introducing state encoding algorithms to decouple qubit requirements from problem size. A classical RL-based solution strategy is used as a baseline to benchmark the quantum algorithms under identical training conditions. All algorithms are evaluated across a flowsheet synthesis problem of increasing unit counts to analyze their performance and scalability. Results show that all approaches are capable of identifying the optimal flowsheet designs in small design spaces. For moderate-scale unit counts, quantum approaches demonstrate competitive performance on a per-episode basis and improved efficiency on a per-parameter basis versus the classical RL benchmark. This work provides a foundation for future quantum computing applications within process systems engineering, establishes a controlled benchmark for comparing classical and quantum algorithms, and shows that the proposed quantum variants remain competitive for the process synthesis problem examined in this work.
Deep Generative Models-Assisted Automated Labeling for Electron Microscopy Images Segmentation
Jul 28, 2024



The rapid advancement of deep learning has facilitated the automated processing of electron microscopy (EM) big data stacks. However, designing a framework that eliminates manual labeling and adapts to domain gaps remains challenging. Current research remains entangled in the dilemma of pursuing complete automation while still requiring simulations or slight manual annotations. Here we demonstrate tandem generative adversarial network (tGAN), a fully label-free and simulation-free pipeline capable of generating EM images for computer vision training. The tGAN can assimilate key features from new data stacks, thus producing a tailored virtual dataset for the training of automated EM analysis tools. Using segmenting nanoparticles for analyzing size distribution of supported catalysts as the demonstration, our findings showcased that the recognition accuracy of tGAN even exceeds the manually-labeling method by 5%. It can also be adaptively deployed to various data domains without further manual manipulation, which is verified by transfer learning from HAADF-STEM to BF-TEM. This generalizability may enable it to extend its application to a broader range of imaging characterizations, liberating microscopists and materials scientists from tedious dataset annotations.
Generative AI and Process Systems Engineering: The Next Frontier
Feb 15, 2024



This article explores how emerging generative artificial intelligence (GenAI) models, such as large language models (LLMs), can enhance solution methodologies within process systems engineering (PSE). These cutting-edge GenAI models, particularly foundation models (FMs), which are pre-trained on extensive, general-purpose datasets, offer versatile adaptability for a broad range of tasks, including responding to queries, image generation, and complex decision-making. Given the close relationship between advancements in PSE and developments in computing and systems technologies, exploring the synergy between GenAI and PSE is essential. We begin our discussion with a compact overview of both classic and emerging GenAI models, including FMs, and then dive into their applications within key PSE domains: synthesis and design, optimization and integration, and process monitoring and control. In each domain, we explore how GenAI models could potentially advance PSE methodologies, providing insights and prospects for each area. Furthermore, the article identifies and discusses potential challenges in fully leveraging GenAI within PSE, including multiscale modeling, data requirements, evaluation metrics and benchmarks, and trust and safety, thereby deepening the discourse on effective GenAI integration into systems analysis, design, optimization, operations, monitoring, and control. This paper provides a guide for future research focused on the applications of emerging GenAI in PSE.
Online Learning Based Risk-Averse Stochastic MPC of Constrained Linear Uncertain Systems
Nov 20, 2020
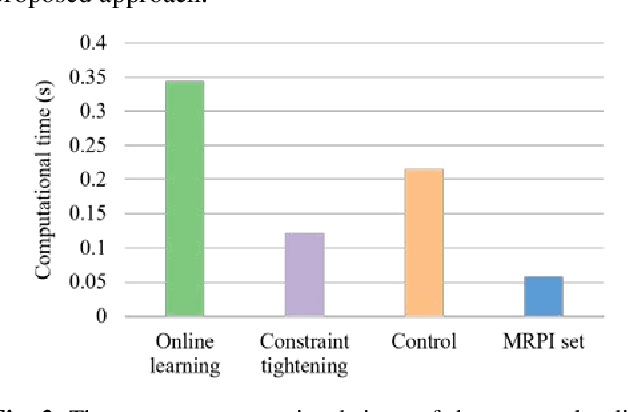
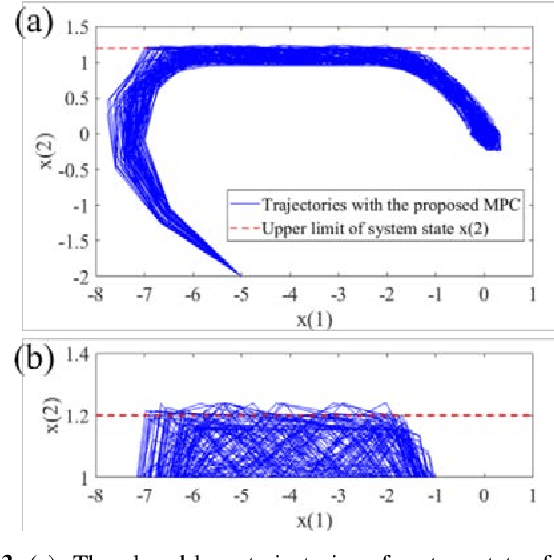
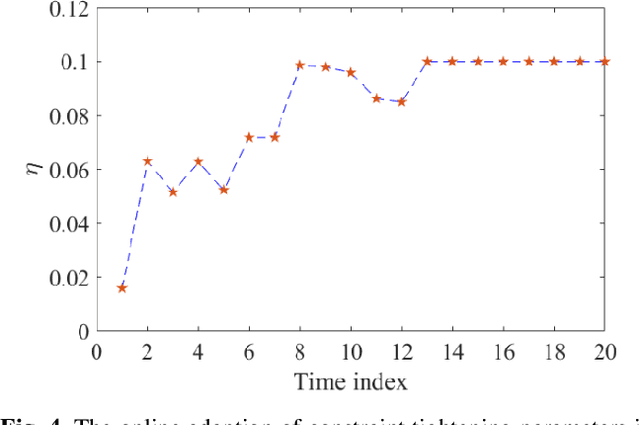
This paper investigates the problem of designing data-driven stochastic Model Predictive Control (MPC) for linear time-invariant systems under additive stochastic disturbance, whose probability distribution is unknown but can be partially inferred from data. We propose a novel online learning based risk-averse stochastic MPC framework in which Conditional Value-at-Risk (CVaR) constraints on system states are required to hold for a family of distributions called an ambiguity set. The ambiguity set is constructed from disturbance data by leveraging a Dirichlet process mixture model that is self-adaptive to the underlying data structure and complexity. Specifically, the structural property of multimodality is exploit-ed, so that the first- and second-order moment information of each mixture component is incorporated into the ambiguity set. A novel constraint tightening strategy is then developed based on an equivalent reformulation of distributionally ro-bust CVaR constraints over the proposed ambiguity set. As more data are gathered during the runtime of the controller, the ambiguity set is updated online using real-time disturbance data, which enables the risk-averse stochastic MPC to cope with time-varying disturbance distributions. The online variational inference algorithm employed does not require all collected data be learned from scratch, and therefore the proposed MPC is endowed with the guaranteed computational complexity of online learning. The guarantees on recursive feasibility and closed-loop stability of the proposed MPC are established via a safe update scheme. Numerical examples are used to illustrate the effectiveness and advantages of the proposed MPC.
Deep Learning and Knowledge-Based Methods for Computer Aided Molecular Design -- Toward a Unified Approach: State-of-the-Art and Future Directions
May 18, 2020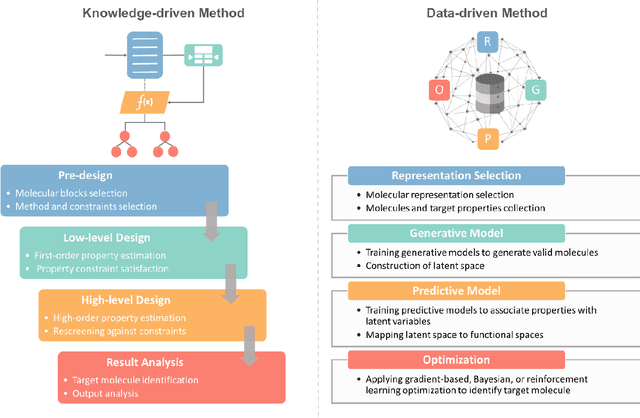
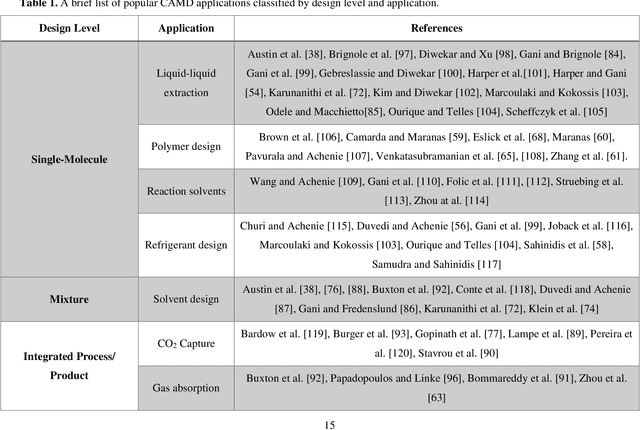
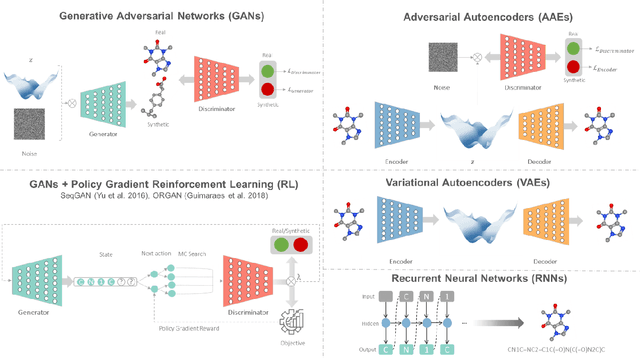
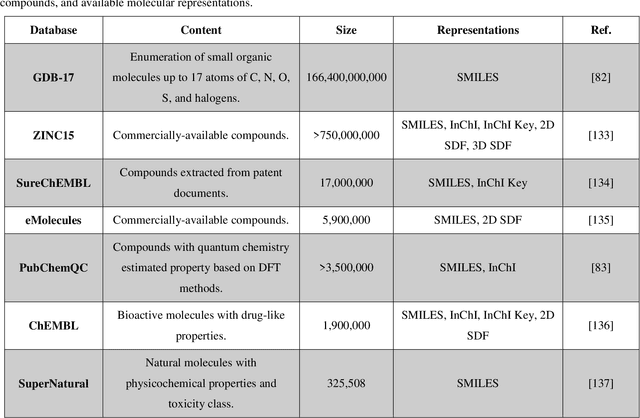
The optimal design of compounds through manipulating properties at the molecular level is often the key to considerable scientific advances and improved process systems performance. This paper highlights key trends, challenges, and opportunities underpinning the Computer-Aided Molecular Design (CAMD) problems. A brief review of knowledge-driven property estimation methods and solution techniques, as well as corresponding CAMD tools and applications, are first presented. In view of the computational challenges plaguing knowledge-based methods and techniques, we survey the current state-of-the-art applications of deep learning to molecular design as a fertile approach towards overcoming computational limitations and navigating uncharted territories of the chemical space. The main focus of the survey is given to deep generative modeling of molecules under various deep learning architectures and different molecular representations. Further, the importance of benchmarking and empirical rigor in building deep learning models is spotlighted. The review article also presents a detailed discussion of the current perspectives and challenges of knowledge-based and data-driven CAMD and identifies key areas for future research directions. Special emphasis is on the fertile avenue of hybrid modeling paradigm, in which deep learning approaches are exploited while leveraging the accumulated wealth of knowledge-driven CAMD methods and tools.
Quantum Computing Assisted Deep Learning for Fault Detection and Diagnosis in Industrial Process Systems
Feb 29, 2020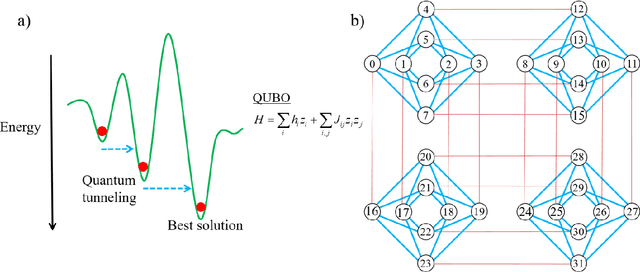
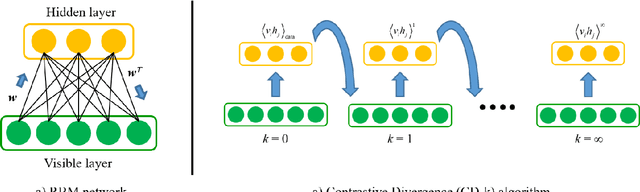
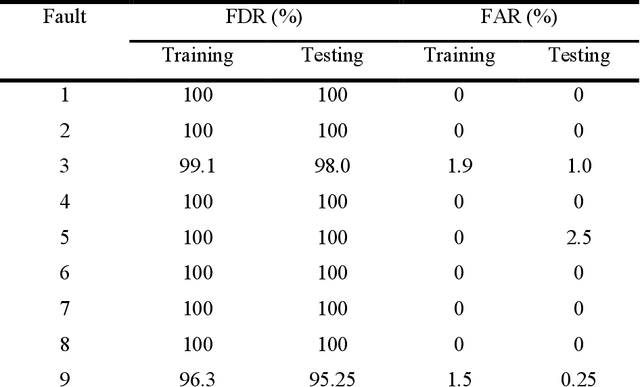
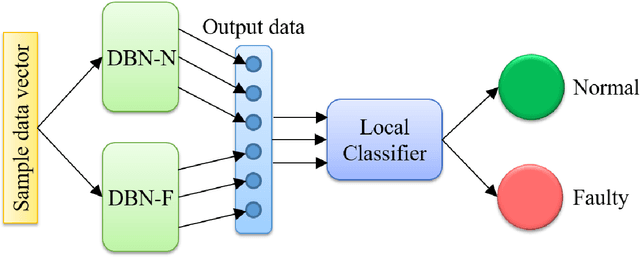
Quantum computing (QC) and deep learning techniques have attracted widespread attention in the recent years. This paper proposes QC-based deep learning methods for fault diagnosis that exploit their unique capabilities to overcome the computational challenges faced by conventional data-driven approaches performed on classical computers. Deep belief networks are integrated into the proposed fault diagnosis model and are used to extract features at different levels for normal and faulty process operations. The QC-based fault diagnosis model uses a quantum computing assisted generative training process followed by discriminative training to address the shortcomings of classical algorithms. To demonstrate its applicability and efficiency, the proposed fault diagnosis method is applied to process monitoring of continuous stirred tank reactor (CSTR) and Tennessee Eastman (TE) process. The proposed QC-based deep learning approach enjoys superior fault detection and diagnosis performance with obtained average fault detection rates of 79.2% and 99.39% for CSTR and TE process, respectively.
Distributionally Robust Chance Constrained Programming with Generative Adversarial Networks
Feb 28, 2020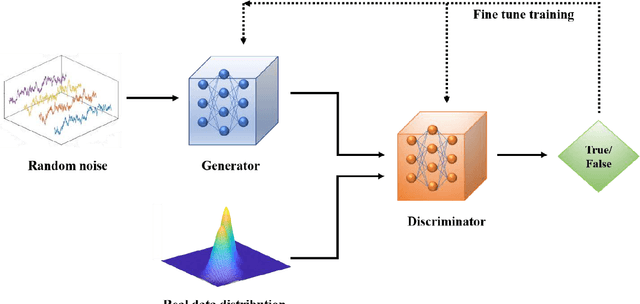
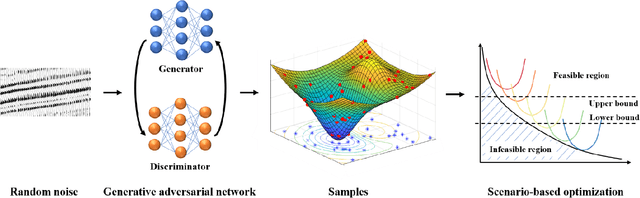
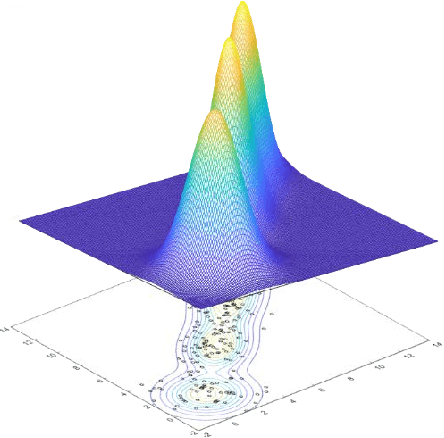
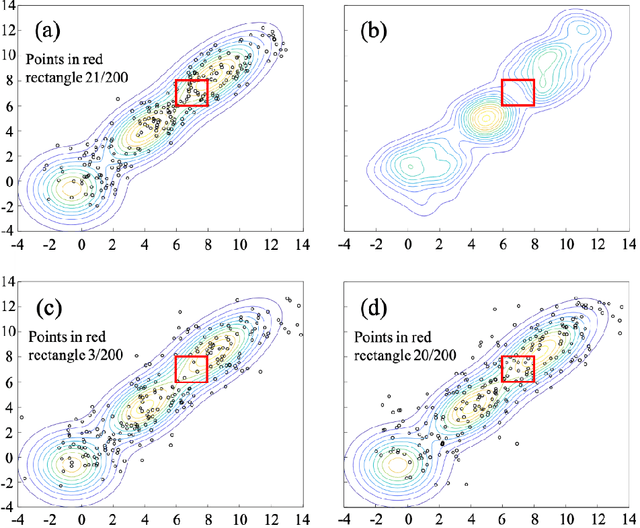
This paper presents a novel deep learning based data-driven optimization method. A novel generative adversarial network (GAN) based data-driven distributionally robust chance constrained programming framework is proposed. GAN is applied to fully extract distributional information from historical data in a nonparametric and unsupervised way without a priori approximation or assumption. Since GAN utilizes deep neural networks, complicated data distributions and modes can be learned, and it can model uncertainty efficiently and accurately. Distributionally robust chance constrained programming takes into consideration ambiguous probability distributions of uncertain parameters. To tackle the computational challenges, sample average approximation method is adopted, and the required data samples are generated by GAN in an end-to-end way through the differentiable networks. The proposed framework is then applied to supply chain optimization under demand uncertainty. The applicability of the proposed approach is illustrated through a county-level case study of a spatially explicit biofuel supply chain in Illinois.
Quantum Computing based Hybrid Solution Strategies for Large-scale Discrete-Continuous Optimization Problems
Oct 29, 2019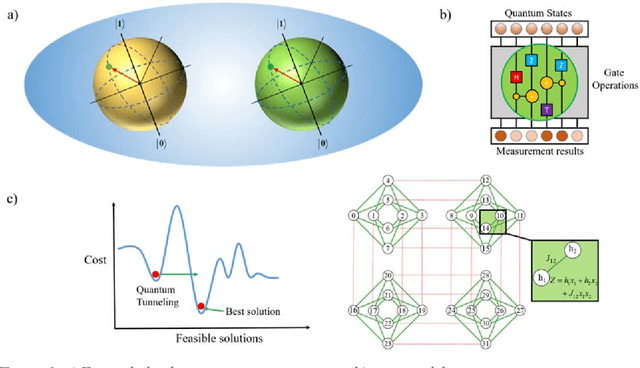
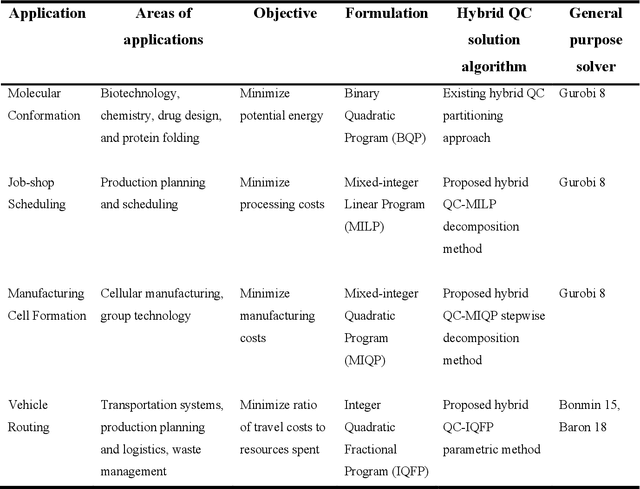
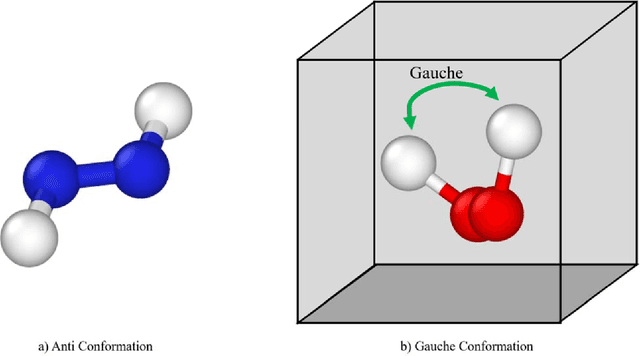
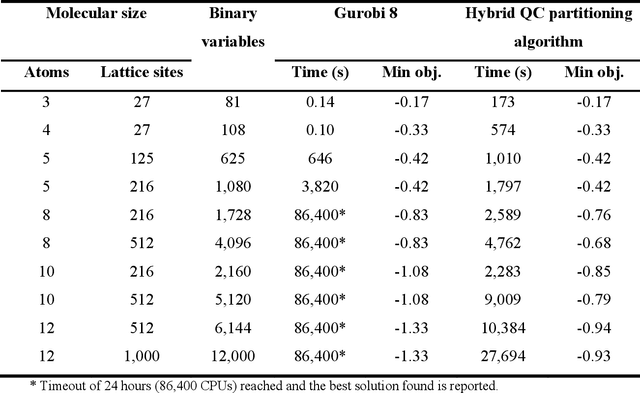
Quantum computing (QC) has gained popularity due to its unique capabilities that are quite different from that of classical computers in terms of speed and methods of operations. This paper proposes hybrid models and methods that effectively leverage the complementary strengths of deterministic algorithms and QC techniques to overcome combinatorial complexity for solving large-scale mixed-integer programming problems. Four applications, namely the molecular conformation problem, job-shop scheduling problem, manufacturing cell formation problem, and the vehicle routing problem, are specifically addressed. Large-scale instances of these application problems across multiple scales ranging from molecular design to logistics optimization are computationally challenging for deterministic optimization algorithms on classical computers. To address the computational challenges, hybrid QC-based algorithms are proposed and extensive computational experimental results are presented to demonstrate their applicability and efficiency. The proposed QC-based solution strategies enjoy high computational efficiency in terms of solution quality and computation time, by utilizing the unique features of both classical and quantum computers.
Optimization under Uncertainty in the Era of Big Data and Deep Learning: When Machine Learning Meets Mathematical Programming
Apr 03, 2019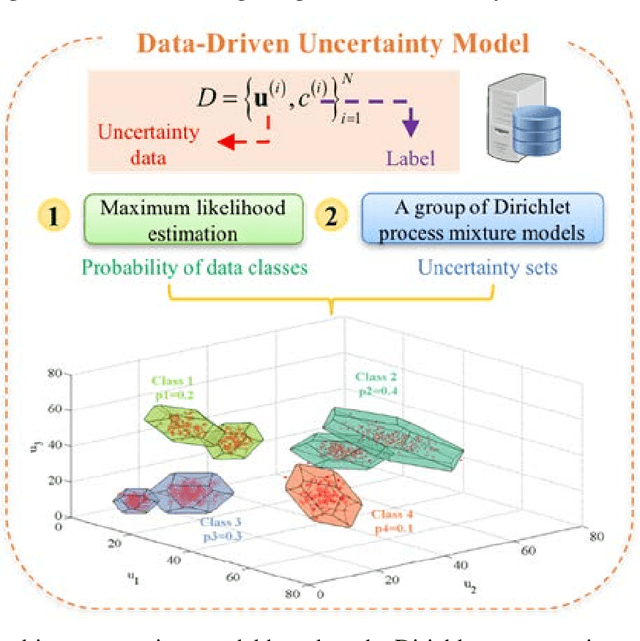
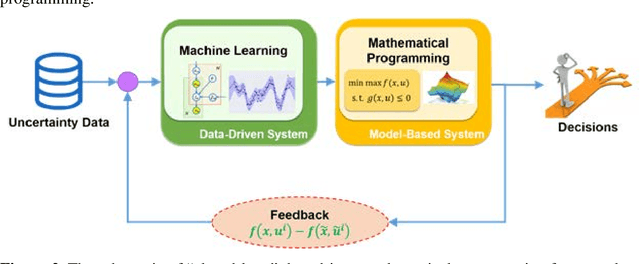
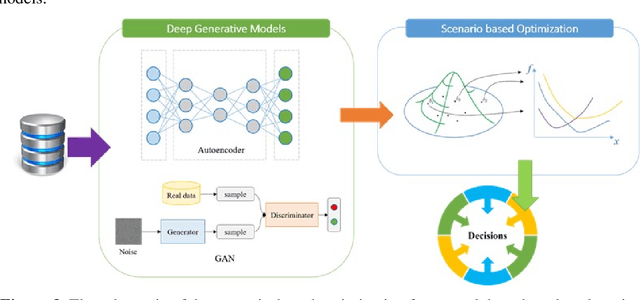
This paper reviews recent advances in the field of optimization under uncertainty via a modern data lens, highlights key research challenges and promise of data-driven optimization that organically integrates machine learning and mathematical programming for decision-making under uncertainty, and identifies potential research opportunities. A brief review of classical mathematical programming techniques for hedging against uncertainty is first presented, along with their wide spectrum of applications in Process Systems Engineering. A comprehensive review and classification of the relevant publications on data-driven distributionally robust optimization, data-driven chance constrained program, data-driven robust optimization, and data-driven scenario-based optimization is then presented. This paper also identifies fertile avenues for future research that focuses on a closed-loop data-driven optimization framework, which allows the feedback from mathematical programming to machine learning, as well as scenario-based optimization leveraging the power of deep learning techniques. Perspectives on online learning-based data-driven multistage optimization with a learning-while-optimizing scheme is presented.
Posteriori Probabilistic Bounds of Convex Scenario Programs with Validation Tests
Mar 27, 2019
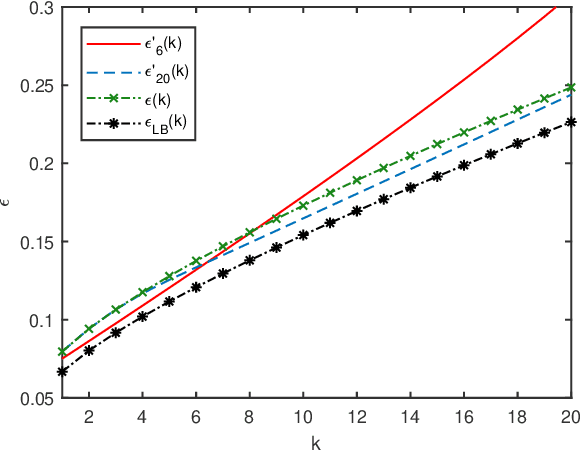
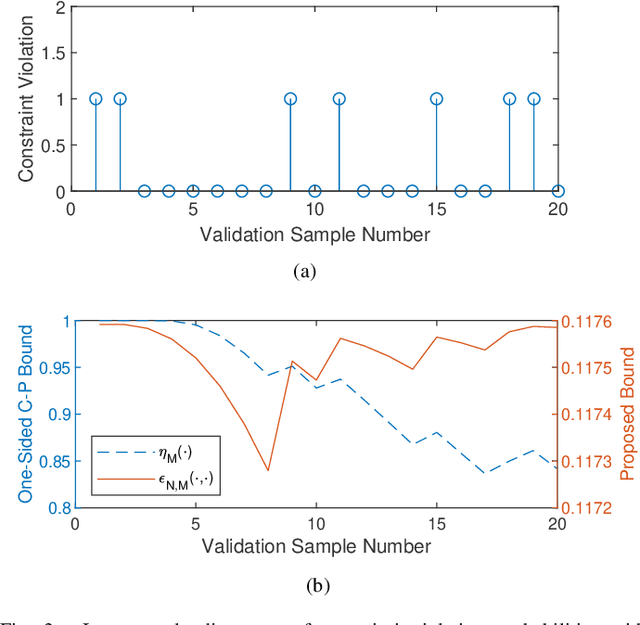
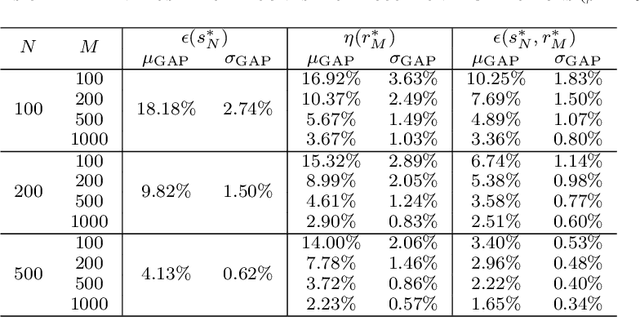
Scenario programs have established themselves as efficient tools towards decision-making under uncertainty. To assess the quality of scenario-based solutions a posteriori, validation tests based on Bernoulli trials have been widely adopted in practice. However, to reach a theoretically reliable conclusion, one typically needs to collect massive validation samples. In this work, we propose new posteriori bounds for convex scenario programs with validation tests, which are dependent on both realizations of support constraints and performance on out-of-sample validation data. The proposed bounds enjoy wide generality in that many existing theoretical results can be incorporated as particular cases. To facilitate practical use, a systematic approach for parameterizing posteriori probability functions is also developed, which is shown to possess a variety of desirable properties allowing for easy implementations and clear interpretations. By synthesizing information about support constraints and validation tests, less conservative estimates of reliability levels can be attained for randomized solutions in comparison with existing posteriori bounds. Case studies on controller design of aircraft lateral motion are presented to validate the effectiveness of the proposed posteriori bounds.