 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Attention-based Multi-Relational Graph Convolutional Networks
May 20, 2018
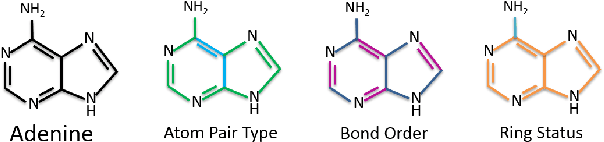
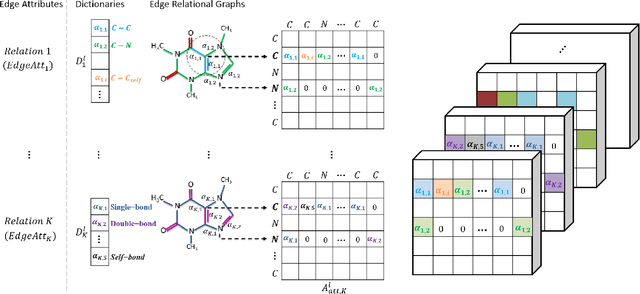
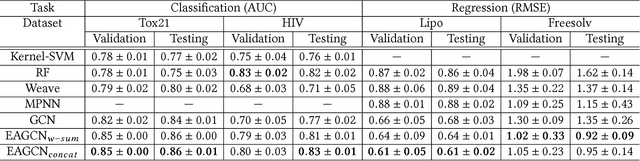
Graph convolutional network (GCN) is generalization of convolutional neural network (CNN) to work with arbitrarily structured graphs. A binary adjacency matrix is commonly used in training a GCN. Recently, the attention mechanism allows the network to learn a dynamic and adaptive aggregation of the neighborhood. We propose a new GCN model on the graphs where edges are characterized in multiple views or precisely in terms of multiple relationships. For instance, in chemical graph theory, compound structures are often represented by the hydrogen-depleted molecular graph where nodes correspond to atoms and edges correspond to chemical bonds. Multiple attributes can be important to characterize chemical bonds, such as atom pair (the types of atoms that a bond connects), aromaticity, and whether a bond is in a ring. The different attributes lead to different graph representations for the same molecule. There is growing interests in both chemistry and machine learning fields to directly learn molecular properties of compounds from the molecular graph, instead of from fingerprints predefined by chemists. The proposed GCN model, which we call edge attention-based multi-relational GCN (EAGCN), jointly learns attention weights and node features in graph convolution. For each bond attribute, a real-valued attention matrix is used to replace the binary adjacency matrix. By designing a dictionary for the edge attention, and forming the attention matrix of each molecule by looking up the dictionary, the EAGCN exploits correspondence between bonds in different molecules. The prediction of compound properties is based on the aggregated node features, which is independent of the varying molecule (graph) size. We demonstrate the efficacy of the EAGCN on multiple chemical datasets: Tox21, HIV, Freesolv, and Lipophilicity, and interpret the resultant attention weights.
VIGAN: Missing View Imputation with Generative Adversarial Networks
Nov 01, 2017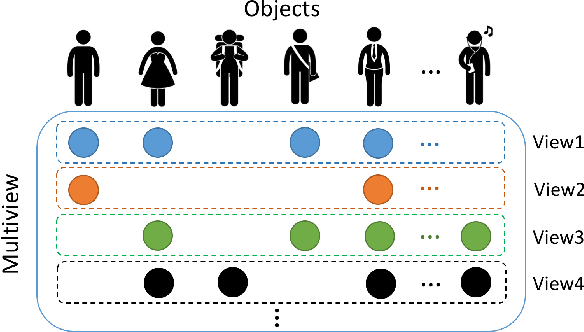
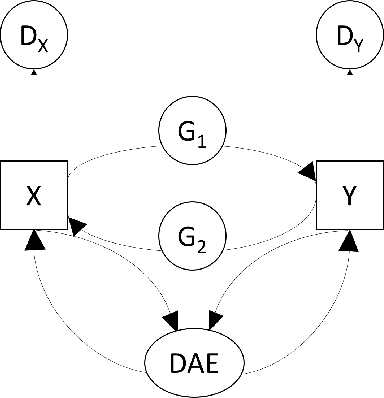
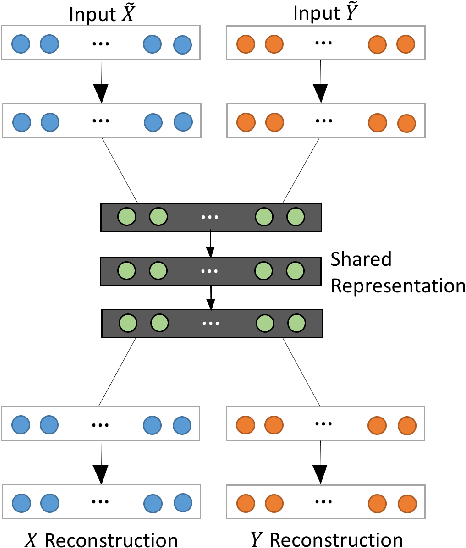
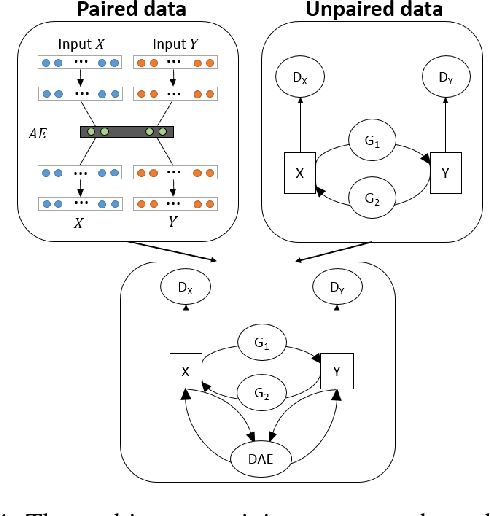
In an era when big data are becoming the norm, there is less concern with the quantity but more with the quality and completeness of the data. In many disciplines, data are collected from heterogeneous sources, resulting in multi-view or multi-modal datasets. The missing data problem has been challenging to address in multi-view data analysis. Especially, when certain samples miss an entire view of data, it creates the missing view problem. Classic multiple imputations or matrix completion methods are hardly effective here when no information can be based on in the specific view to impute data for such samples. The commonly-used simple method of removing samples with a missing view can dramatically reduce sample size, thus diminishing the statistical power of a subsequent analysis. In this paper, we propose a novel approach for view imputation via generative adversarial networks (GANs), which we name by VIGAN. This approach first treats each view as a separate domain and identifies domain-to-domain mappings via a GAN using randomly-sampled data from each view, and then employs a multi-modal denoising autoencoder (DAE) to reconstruct the missing view from the GAN outputs based on paired data across the views. Then, by optimizing the GAN and DAE jointly, our model enables the knowledge integration for domain mappings and view correspondences to effectively recover the missing view. Empirical results on benchmark datasets validate the VIGAN approach by comparing against the state of the art. The evaluation of VIGAN in a genetic study of substance use disorders further proves the effectiveness and usability of this approach in life science.