 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
Dec 28, 2023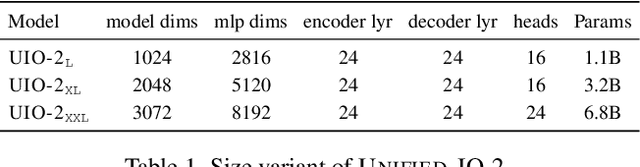
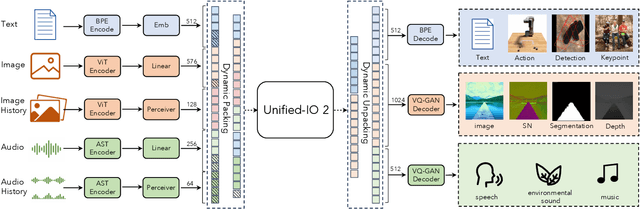
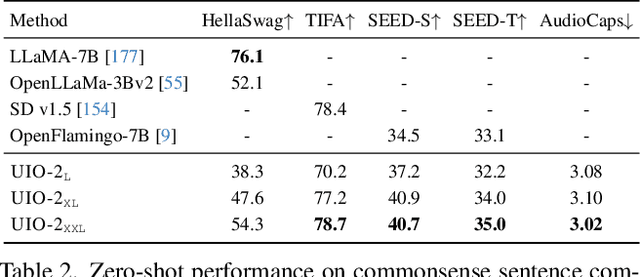

We present Unified-IO 2, the first autoregressive multimodal model that is capable of understanding and generating image, text, audio, and action. To unify different modalities, we tokenize inputs and outputs -- images, text, audio, action, bounding boxes, etc., into a shared semantic space and then process them with a single encoder-decoder transformer model. Since training with such diverse modalities is challenging, we propose various architectural improvements to stabilize model training. We train our model from scratch on a large multimodal pre-training corpus from diverse sources with a multimodal mixture of denoisers objective. To learn an expansive set of skills, such as following multimodal instructions, we construct and finetune on an ensemble of 120 datasets with prompts and augmentations. With a single unified model, Unified-IO 2 achieves state-of-the-art performance on the GRIT benchmark and strong results in more than 35 benchmarks, including image generation and understanding, natural language understanding, video and audio understanding, and robotic manipulation. We release all our models to the research community.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
GRIT: General Robust Image Task Benchmark
May 02, 2022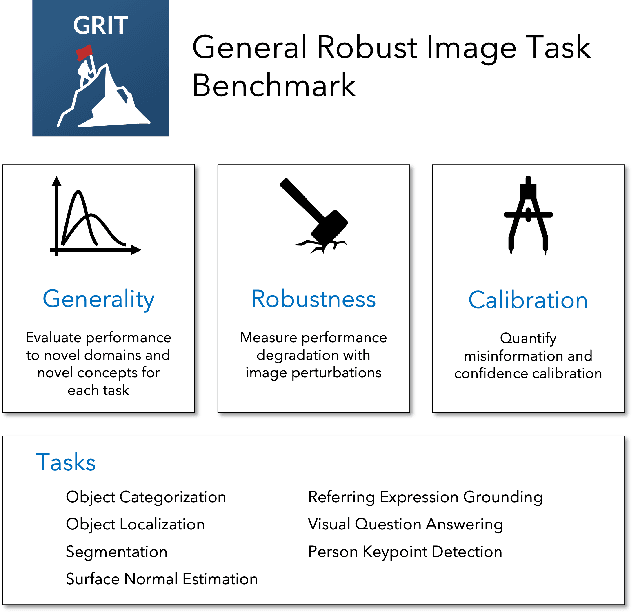
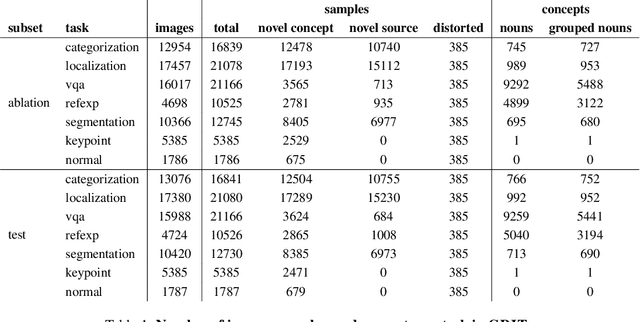
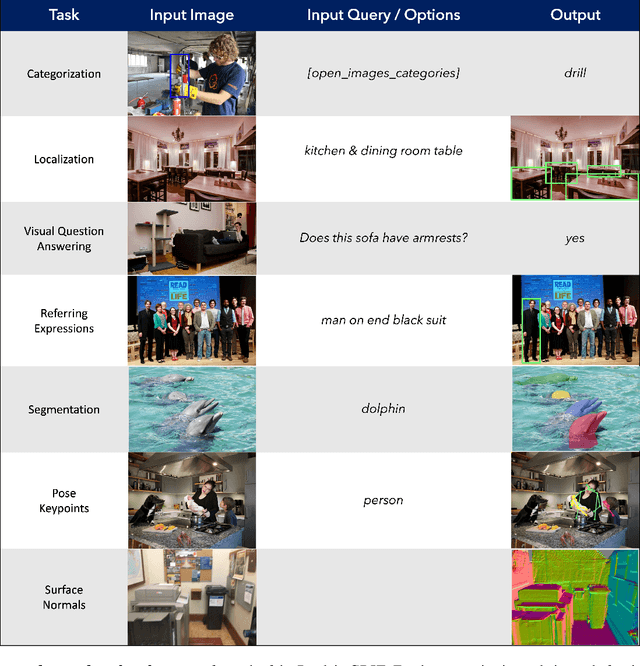
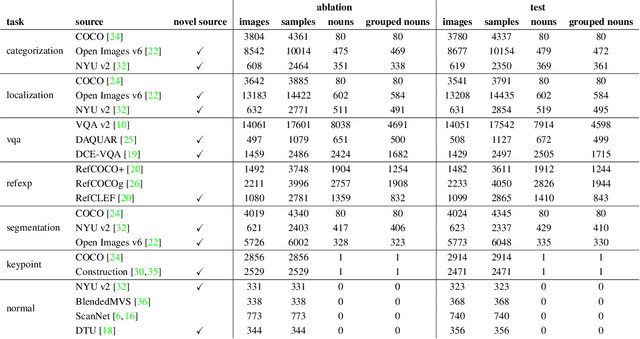
Computer vision models excel at making predictions when the test distribution closely resembles the training distribution. Such models have yet to match the ability of biological vision to learn from multiple sources and generalize to new data sources and tasks. To facilitate the development and evaluation of more general vision systems, we introduce the General Robust Image Task (GRIT) benchmark. GRIT evaluates the performance, robustness, and calibration of a vision system across a variety of image prediction tasks, concepts, and data sources. The seven tasks in GRIT are selected to cover a range of visual skills: object categorization, object localization, referring expression grounding, visual question answering, segmentation, human keypoint detection, and surface normal estimation. GRIT is carefully designed to enable the evaluation of robustness under image perturbations, image source distribution shift, and concept distribution shift. By providing a unified platform for thorough assessment of skills and concepts learned by a vision model, we hope GRIT catalyzes the development of performant and robust general purpose vision systems.
Contour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
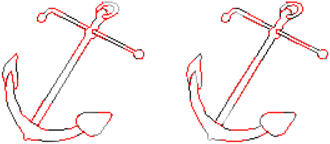

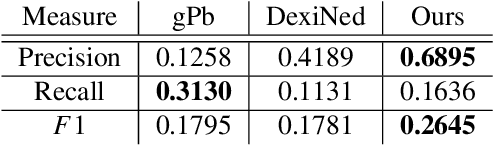
Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.