 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIT: General Robust Image Task Benchmark
Paper and Code
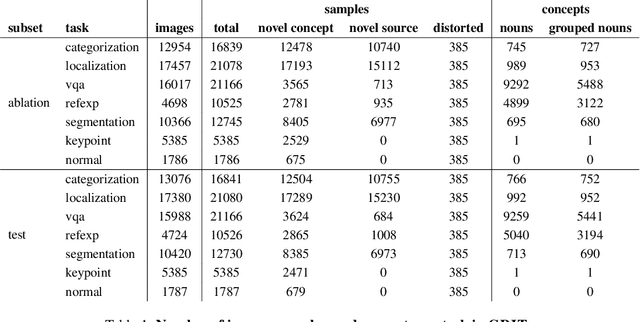
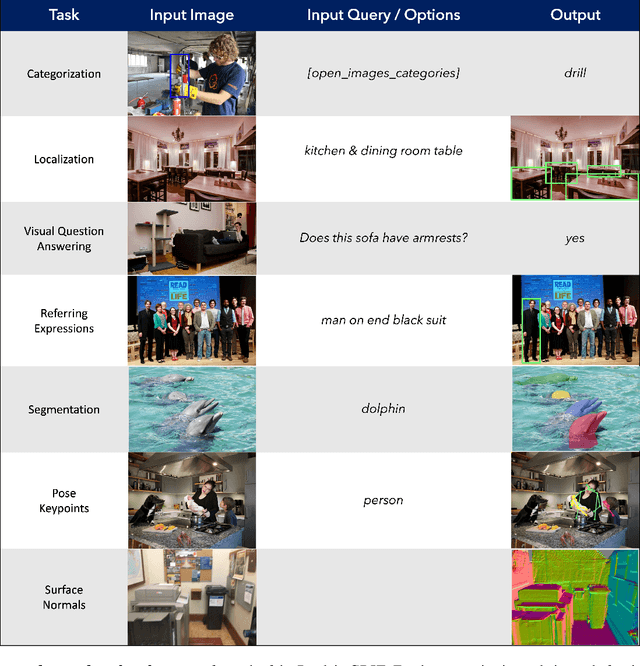
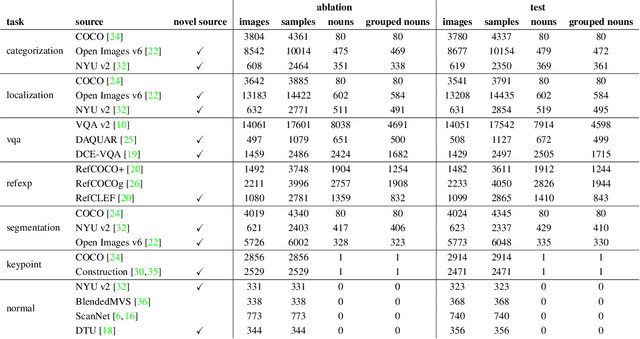
Computer vision models excel at making predictions when the test distribution closely resembles the training distribution. Such models have yet to match the ability of biological vision to learn from multiple sources and generalize to new data sources and tasks. To facilitate the development and evaluation of more general vision systems, we introduce the General Robust Image Task (GRIT) benchmark. GRIT evaluates the performance, robustness, and calibration of a vision system across a variety of image prediction tasks, concepts, and data sources. The seven tasks in GRIT are selected to cover a range of visual skills: object categorization, object localization, referring expression grounding, visual question answering, segmentation, human keypoint detection, and surface normal estimation. GRIT is carefully designed to enable the evaluation of robustness under image perturbations, image source distribution shift, and concept distribution shift. By providing a unified platform for thorough assessment of skills and concepts learned by a vision model, we hope GRIT catalyzes the development of performant and robust general purpose vision systems.