 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
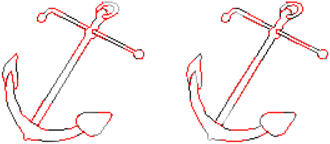

Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.
Scene Categorization from Contours: Medial Axis Based Salience Measures
Nov 26, 2018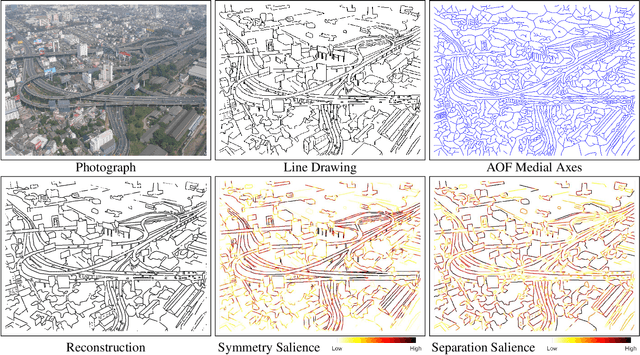

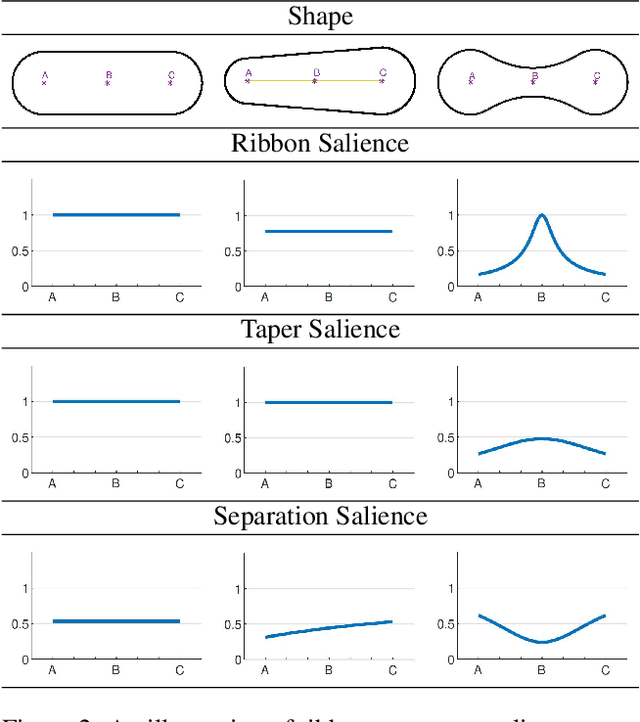

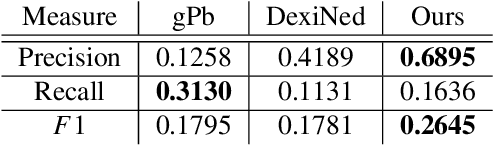
The computer vision community has witnessed recent advances in scene categorization from images, with the state-of-the art systems now achieving impressive recognition rates on challenging benchmarks such as the Places365 dataset. Such systems have been trained on photographs which include color, texture and shading cues. The geometry of shapes and surfaces, as conveyed by scene contours, is not explicitly considered for this task. Remarkably, humans can accurately recognize natural scenes from line drawings, which consist solely of contour-based shape cues. Here we report the first computer vision study on scene categorization of line drawings derived from popular databases including an artist scene database, MIT67, and Places365. Specifically, we use off-the-shelf pre-trained CNNs to perform scene classification given only contour information as input and find performance levels well above chance. We also show that medial-axis based contour salience methods can be used to select more informative subsets of contour pixels and that the variation in CNN classification performance on various choices for these subsets is qualitatively similar to that observed in human performance. Moreover, when the salience measures are used to weight the contours, as opposed to pruning them, we find that these weights boost our CNN performance above that for unweighted contour input. That is, the medial axis based salience weights appear to add useful information that is not available when CNNs are trained to use contours alone.