 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Completion using Deep Structural Priors
Feb 09, 2023



Humans can easily perceive illusory contours and complete missing forms in fragmented shapes. This work investigates whether such capability can arise in convolutional neural networks (CNNs) using deep structural priors computed directly from images. In this work, we present a framework that completes disconnected contours and connects fragmented lines and curves. In our framework, we propose a model that does not even need to know which regions of the contour are eliminated. We introduce an iterative process that completes an incomplete image and we propose novel measures that guide this to find regions it needs to complete. Our model trains on a single image and fills in the contours with no additional training data. Our work builds a robust framework to achieve contour completion using deep structural priors and extensively investigate how such a model could be implemented.
Medial Spectral Coordinates for 3D Shape Analysis
Nov 30, 2021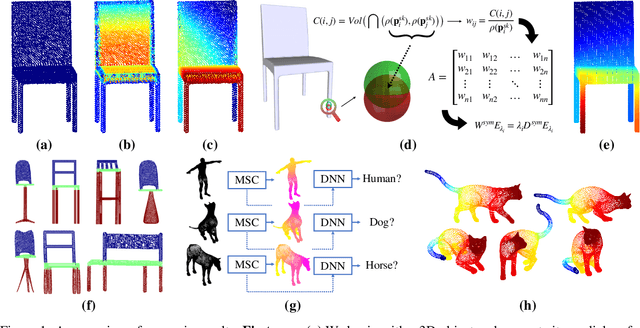
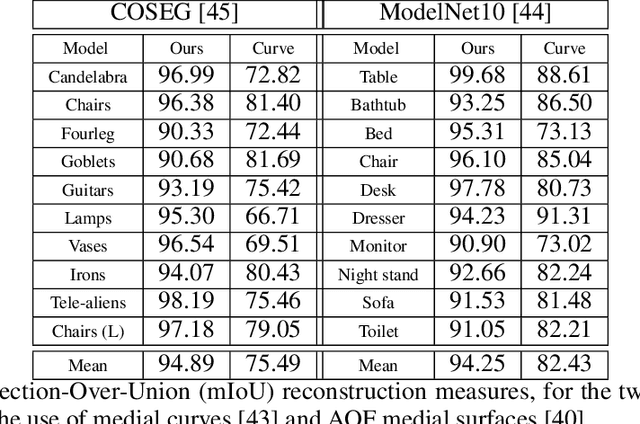
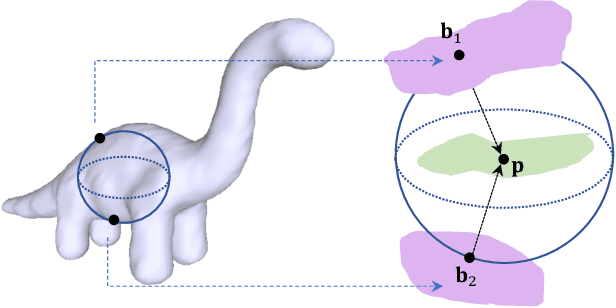
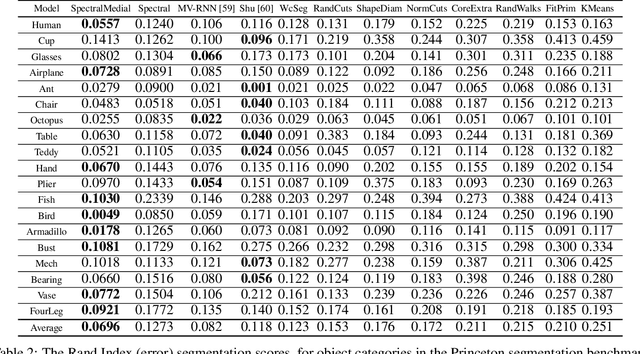
In recent years there has been a resurgence of interest in our community in the shape analysis of 3D objects represented by surface meshes, their voxelized interiors, or surface point clouds. In part, this interest has been stimulated by the increased availability of RGBD cameras, and by applications of computer vision to autonomous driving, medical imaging, and robotics. In these settings, spectral coordinates have shown promise for shape representation due to their ability to incorporate both local and global shape properties in a manner that is qualitatively invariant to isometric transformations. Yet, surprisingly, such coordinates have thus far typically considered only local surface positional or derivative information. In the present article, we propose to equip spectral coordinates with medial (object width) information, so as to enrich them. The key idea is to couple surface points that share a medial ball, via the weights of the adjacency matrix. We develop a spectral feature using this idea, and the algorithms to compute it. The incorporation of object width and medial coupling has direct benefits, as illustrated by our experiments on object classification, object part segmentation, and surface point correspondence.
Contour-guided Image Completion with Perceptual Grouping
Nov 22, 2021
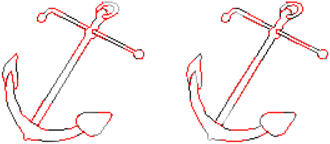

Humans are excellent at perceiving illusory outlines. We are readily able to complete contours, shapes, scenes, and even unseen objects when provided with images that contain broken fragments of a connected appearance. In vision science, this ability is largely explained by perceptual grouping: a foundational set of processes in human vision that describes how separated elements can be grouped. In this paper, we revisit an algorithm called Stochastic Completion Fields (SCFs) that mechanizes a set of such processes -- good continuity, closure, and proximity -- through contour completion. This paper implements a modernized model of the SCF algorithm, and uses it in an image editing framework where we propose novel methods to complete fragmented contours. We show how the SCF algorithm plausibly mimics results in human perception. We use the SCF completed contours as guides for inpainting, and show that our guides improve the performance of state-of-the-art models. Additionally, we show that the SCF aids in finding edges in high-noise environments. Overall, our described algorithms resemble an important mechanism in the human visual system, and offer a novel framework that modern computer vision models can benefit from.
Automatic selection of eye tracking variables in visual categorization in adults and infants
Oct 28, 2020



Visual categorization and learning of visual categories exhibit early onset, however the underlying mechanisms of early categorization are not well understood. The main limiting factor for examining these mechanisms is the limited duration of infant cooperation (10-15 minutes), which leaves little room for multiple test trials. With its tight link to visual attention, eye tracking is a promising method for getting access to the mechanisms of category learning. But how should researchers decide which aspects of the rich eye tracking data to focus on? To date, eye tracking variables are generally handpicked, which may lead to biases in the eye tracking data. Here, we propose an automated method for selecting eye tracking variables based on analyses of their usefulness to discriminate learners from non-learners of visual categories. We presented infants and adults with a category learning task and tracked their eye movements. We then extracted an over-complete set of eye tracking variables encompassing durations, probabilities, latencies, and the order of fixations and saccadic eye movements. We compared three statistical techniques for identifying those variables among this large set that are useful for discriminating learners form non-learners: ANOVA ranking, Bayes ranking, and L1 regularized logistic regression. We found remarkable agreement between these methods in identifying a small set of discriminant variables. Moreover, the same eye tracking variables allow us to classify category learners from non-learners among adults and 6- to 8-month-old infants with accuracies above 71%.
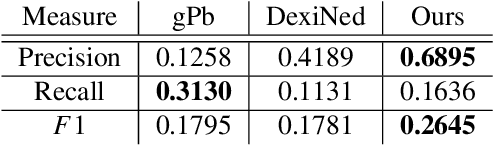
Scene Categorization from Contours: Medial Axis Based Salience Measures
Nov 26, 2018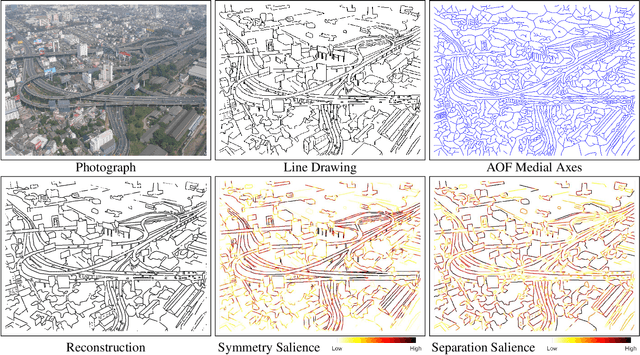

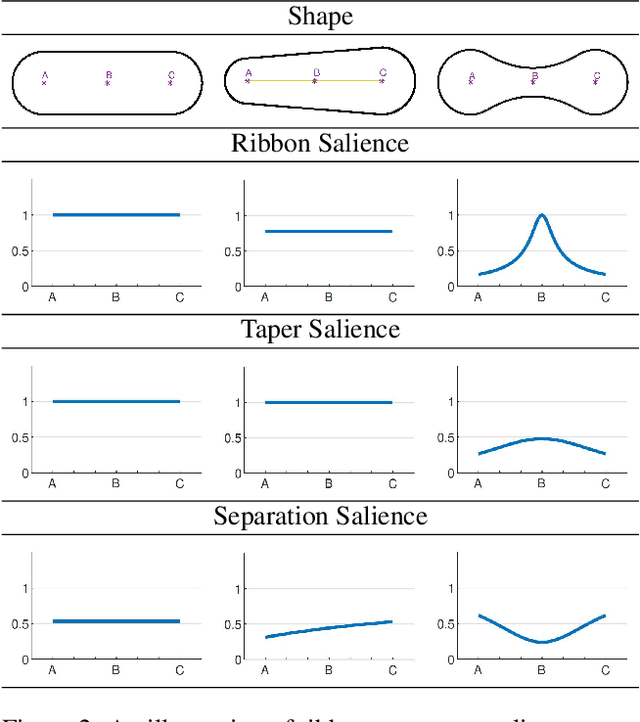

The computer vision community has witnessed recent advances in scene categorization from images, with the state-of-the art systems now achieving impressive recognition rates on challenging benchmarks such as the Places365 dataset. Such systems have been trained on photographs which include color, texture and shading cues. The geometry of shapes and surfaces, as conveyed by scene contours, is not explicitly considered for this task. Remarkably, humans can accurately recognize natural scenes from line drawings, which consist solely of contour-based shape cues. Here we report the first computer vision study on scene categorization of line drawings derived from popular databases including an artist scene database, MIT67, and Places365. Specifically, we use off-the-shelf pre-trained CNNs to perform scene classification given only contour information as input and find performance levels well above chance. We also show that medial-axis based contour salience methods can be used to select more informative subsets of contour pixels and that the variation in CNN classification performance on various choices for these subsets is qualitatively similar to that observed in human performance. Moreover, when the salience measures are used to weight the contours, as opposed to pruning them, we find that these weights boost our CNN performance above that for unweighted contour input. That is, the medial axis based salience weights appear to add useful information that is not available when CNNs are trained to use contours alone.