 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation by Topology Regularization
Jan 28, 2021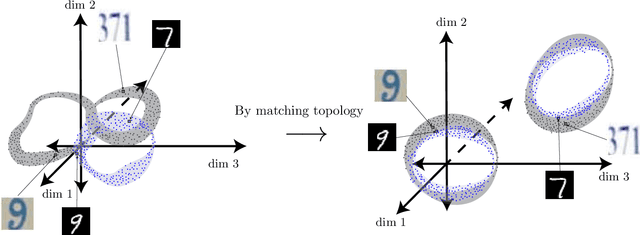

Deep learning has become the leading approach to assisted target recognition. While these methods typically require large amounts of labeled training data, domain adaptation (DA) or transfer learning (TL) enables these algorithms to transfer knowledge from a labelled (source) data set to an unlabelled but related (target) data set of interest. DA enables networks to overcome the distribution mismatch between the source and target that leads to poor generalization in the target domain. DA techniques align these distributions by minimizing a divergence measurement between source and target, making the transfer of knowledge from source to target possible. While these algorithms have advanced significantly in recent years, most do not explicitly leverage global data manifold structure in aligning the source and target. We propose to leverage global data structure by applying a topological data analysis (TDA) technique called persistent homology to TL. In this paper, we examine the use of persistent homology in a domain adversarial (DAd) convolutional neural network (CNN) architecture. The experiments show that aligning persistence alone is insufficient for transfer, but must be considered along with the lifetimes of the topological singularities. In addition, we found that longer lifetimes indicate robust discriminative features and more favorable structure in data. We found that existing divergence minimization based approaches to DA improve the topological structure, as indicated over a baseline without these regularization techniques. We hope these experiments highlight how topological structure can be leveraged to boost performance in TL tasks.
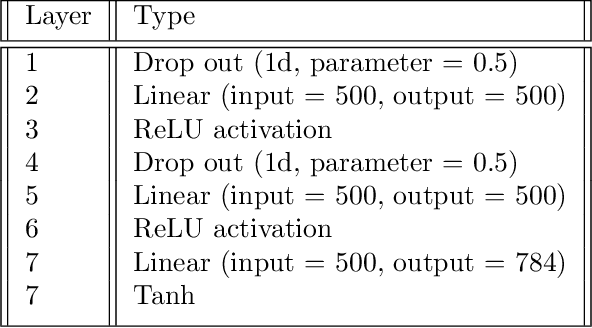
Flexible deep transfer learning by separate feature embeddings and manifold alignment
Dec 22, 2020Object recognition is a key enabler across industry and defense. As technology changes, algorithms must keep pace with new requirements and data. New modalities and higher resolution sensors should allow for increased algorithm robustness. Unfortunately, algorithms trained on existing labeled datasets do not directly generalize to new data because the data distributions do not match. Transfer learning (TL) or domain adaptation (DA) methods have established the groundwork for transferring knowledge from existing labeled source data to new unlabeled target datasets. However, current DA approaches assume similar source and target feature spaces and suffer in the case of massive domain shifts or changes in the feature space. Existing methods assume the data are either the same modality, or can be aligned to a common feature space. Therefore, most methods are not designed to support a fundamental domain change such as visual to auditory data. We propose a novel deep learning framework that overcomes this limitation by learning separate feature extractions for each domain while minimizing the distance between the domains in a latent lower-dimensional space. The alignment is achieved by considering the data manifold along with an adversarial training procedure. We demonstrate the effectiveness of the approach versus traditional methods with several ablation experiments on synthetic, measured, and satellite image datasets. We also provide practical guidelines for training the network while overcoming vanishing gradients which inhibit learning in some adversarial training settings.
Transfer Learning for Aided Target Recognition: Comparing Deep Learning to other Machine Learning Approaches
Nov 25, 2020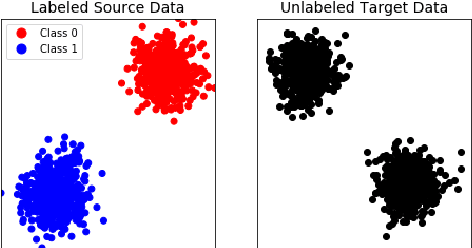

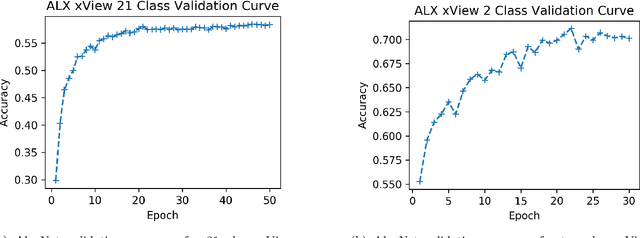

Aided target recognition (AiTR), the problem of classifying objects from sensor data, is an important problem with applications across industry and defense. While classification algorithms continue to improve, they often require more training data than is available or they do not transfer well to settings not represented in the training set. These problems are mitigated by transfer learning (TL), where knowledge gained in a well-understood source domain is transferred to a target domain of interest. In this context, the target domain could represents a poorly-labeled dataset, a different sensor, or an altogether new set of classes to identify. While TL for classification has been an active area of machine learning (ML) research for decades, transfer learning within a deep learning framework remains a relatively new area of research. Although deep learning (DL) provides exceptional modeling flexibility and accuracy on recent real world problems, open questions remain regarding how much transfer benefit is gained by using DL versus other ML architectures. Our goal is to address this shortcoming by comparing transfer learning within a DL framework to other ML approaches across transfer tasks and datasets. Our main contributions are: 1) an empirical analysis of DL and ML algorithms on several transfer tasks and domains including gene expressions and satellite imagery, and 2) a discussion of the limitations and assumptions of TL for aided target recognition -- both for DL and ML in general. We close with a discussion of future directions for DL transfer.
Automatic selection of eye tracking variables in visual categorization in adults and infants
Oct 28, 2020



Visual categorization and learning of visual categories exhibit early onset, however the underlying mechanisms of early categorization are not well understood. The main limiting factor for examining these mechanisms is the limited duration of infant cooperation (10-15 minutes), which leaves little room for multiple test trials. With its tight link to visual attention, eye tracking is a promising method for getting access to the mechanisms of category learning. But how should researchers decide which aspects of the rich eye tracking data to focus on? To date, eye tracking variables are generally handpicked, which may lead to biases in the eye tracking data. Here, we propose an automated method for selecting eye tracking variables based on analyses of their usefulness to discriminate learners from non-learners of visual categories. We presented infants and adults with a category learning task and tracked their eye movements. We then extracted an over-complete set of eye tracking variables encompassing durations, probabilities, latencies, and the order of fixations and saccadic eye movements. We compared three statistical techniques for identifying those variables among this large set that are useful for discriminating learners form non-learners: ANOVA ranking, Bayes ranking, and L1 regularized logistic regression. We found remarkable agreement between these methods in identifying a small set of discriminant variables. Moreover, the same eye tracking variables allow us to classify category learners from non-learners among adults and 6- to 8-month-old infants with accuracies above 71%.