 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAME: Pre-Training Video Feature Representations via Anticipation and Memory
Jun 05, 2025Dense video prediction tasks, such as object tracking and semantic segmentation, require video encoders that generate temporally consistent, spatially dense features for every frame. However, existing approaches fall short: image encoders like DINO or CLIP lack temporal awareness, while video models such as VideoMAE underperform compared to image encoders on dense prediction tasks. We address this gap with FRAME, a self-supervised video frame encoder tailored for dense video understanding. FRAME learns to predict current and future DINO patch features from past and present RGB frames, leading to spatially precise and temporally coherent representations. To our knowledge, FRAME is the first video encoder to leverage image-based models for dense prediction while outperforming them on tasks requiring fine-grained visual correspondence. As an auxiliary capability, FRAME aligns its class token with CLIP's semantic space, supporting language-driven tasks such as video classification. We evaluate FRAME across six dense prediction tasks on seven datasets, where it consistently outperforms image encoders and existing self-supervised video models. Despite its versatility, FRAME maintains a compact architecture suitable for a range of downstream applications.
REN: Fast and Efficient Region Encodings from Patch-Based Image Encoders
May 23, 2025



We introduce the Region Encoder Network (REN), a fast and effective model for generating region-based image representations using point prompts. Recent methods combine class-agnostic segmenters (e.g., SAM) with patch-based image encoders (e.g., DINO) to produce compact and effective region representations, but they suffer from high computational cost due to the segmentation step. REN bypasses this bottleneck using a lightweight module that directly generates region tokens, enabling 60x faster token generation with 35x less memory, while also improving token quality. It uses a few cross-attention blocks that take point prompts as queries and features from a patch-based image encoder as keys and values to produce region tokens that correspond to the prompted objects. We train REN with three popular encoders-DINO, DINOv2, and OpenCLIP-and show that it can be extended to other encoders without dedicated training. We evaluate REN on semantic segmentation and retrieval tasks, where it consistently outperforms the original encoders in both performance and compactness, and matches or exceeds SAM-based region methods while being significantly faster. Notably, REN achieves state-of-the-art results on the challenging Ego4D VQ2D benchmark and outperforms proprietary LMMs on Visual Haystacks' single-needle challenge. Code and models are available at: https://github.com/savya08/REN.
MAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
Jan 15, 2025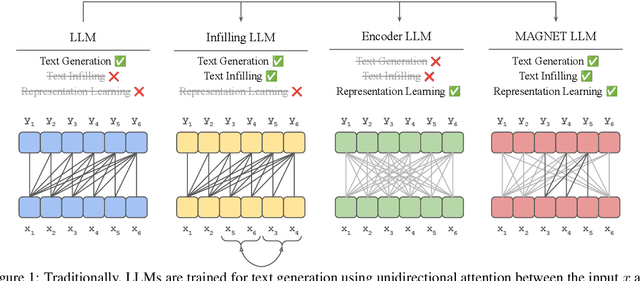
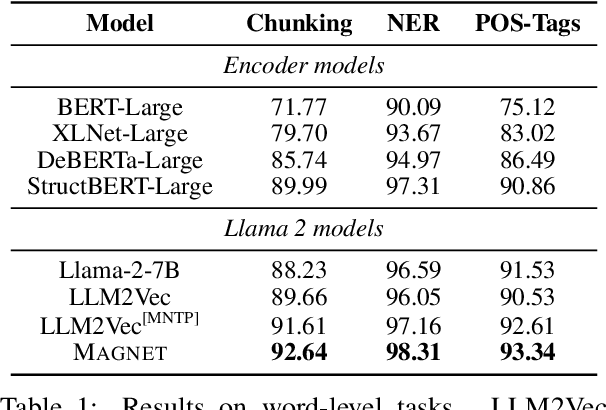
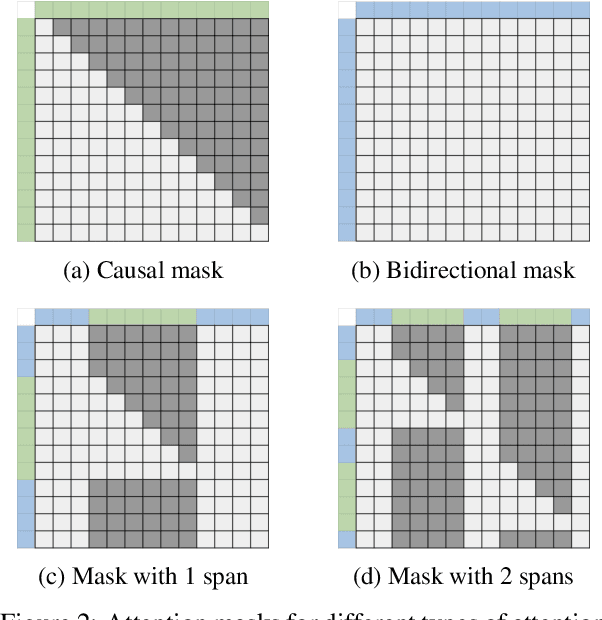
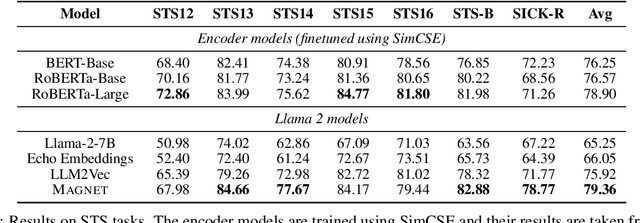
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning, respectively). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we introduce MAGNET, an adaptation of decoder-only LLMs that enhances their ability to generate robust representations and infill missing text spans, while preserving their knowledge and text generation capabilities. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging future context, (3) retain the ability for open-ended text generation without exhibiting repetition problem, and (4) preserve the knowledge gained by the LLM during pretraining.
RELOCATE: A Simple Training-Free Baseline for Visual Query Localization Using Region-Based Representations
Dec 02, 2024We present RELOCATE, a simple training-free baseline designed to perform the challenging task of visual query localization in long videos. To eliminate the need for task-specific training and efficiently handle long videos, RELOCATE leverages a region-based representation derived from pretrained vision models. At a high level, it follows the classic object localization approach: (1) identify all objects in each video frame, (2) compare the objects with the given query and select the most similar ones, and (3) perform bidirectional tracking to get a spatio-temporal response. However, we propose some key enhancements to handle small objects, cluttered scenes, partial visibility, and varying appearances. Notably, we refine the selected objects for accurate localization and generate additional visual queries to capture visual variations. We evaluate RELOCATE on the challenging Ego4D Visual Query 2D Localization dataset, establishing a new baseline that outperforms prior task-specific methods by 49% (relative improvement) in spatio-temporal average precision.
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
Dec 28, 2023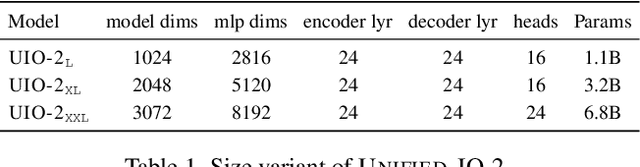
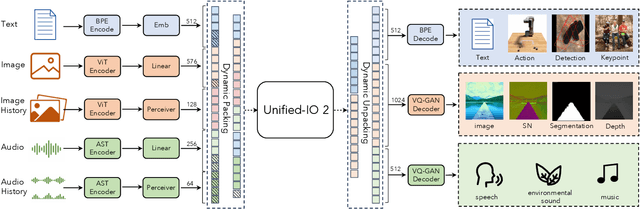
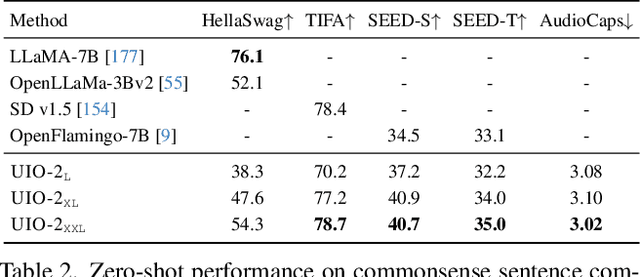

We present Unified-IO 2, the first autoregressive multimodal model that is capable of understanding and generating image, text, audio, and action. To unify different modalities, we tokenize inputs and outputs -- images, text, audio, action, bounding boxes, etc., into a shared semantic space and then process them with a single encoder-decoder transformer model. Since training with such diverse modalities is challenging, we propose various architectural improvements to stabilize model training. We train our model from scratch on a large multimodal pre-training corpus from diverse sources with a multimodal mixture of denoisers objective. To learn an expansive set of skills, such as following multimodal instructions, we construct and finetune on an ensemble of 120 datasets with prompts and augmentations. With a single unified model, Unified-IO 2 achieves state-of-the-art performance on the GRIT benchmark and strong results in more than 35 benchmarks, including image generation and understanding, natural language understanding, video and audio understanding, and robotic manipulation. We release all our models to the research community.
Survey on Memory-Augmented Neural Networks: Cognitive Insights to AI Applications
Dec 13, 2023This paper explores Memory-Augmented Neural Networks (MANNs), delving into how they blend human-like memory processes into AI. It covers different memory types, like sensory, short-term, and long-term memory, linking psychological theories with AI applications. The study investigates advanced architectures such as Hopfield Networks, Neural Turing Machines, Correlation Matrix Memories, Memformer, and Neural Attention Memory, explaining how they work and where they excel. It dives into real-world uses of MANNs across Natural Language Processing, Computer Vision, Multimodal Learning, and Retrieval Models, showing how memory boosters enhance accuracy, efficiency, and reliability in AI tasks. Overall, this survey provides a comprehensive view of MANNs, offering insights for future research in memory-based AI systems.
Neural Active Learning on Heteroskedastic Distributions
Nov 02, 2022



Models that can actively seek out the best quality training data hold the promise of more accurate, adaptable, and efficient machine learning. State-of-the-art active learning techniques tend to prefer examples that are the most difficult to classify. While this works well on homogeneous datasets, we find that it can lead to catastrophic failures when performed on multiple distributions with different degrees of label noise or heteroskedasticity. These active learning algorithms strongly prefer to draw from the distribution with more noise, even if their examples have no informative structure (such as solid color images with random labels). To this end, we demonstrate the catastrophic failure of these active learning algorithms on heteroskedastic distributions and propose a fine-tuning-based approach to mitigate these failures. Further, we propose a new algorithm that incorporates a model difference scoring function for each data point to filter out the noisy examples and sample clean examples that maximize accuracy, outperforming the existing active learning techniques on the heteroskedastic datasets. We hope these observations and techniques are immediately helpful to practitioners and can help to challenge common assumptions in the design of active learning algorithms.
MuRIL: Multilingual Representations for Indian Languages
Apr 02, 2021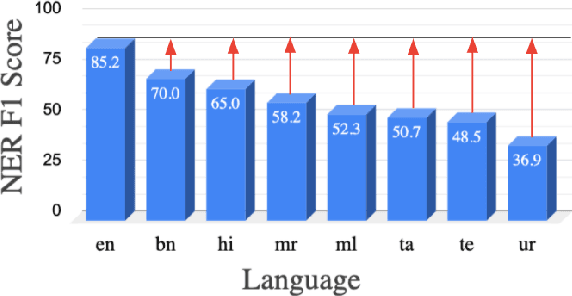


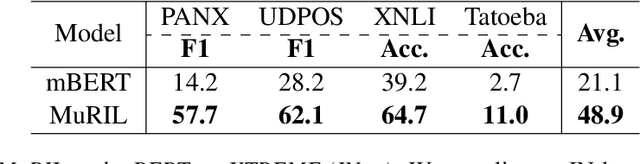
India is a multilingual society with 1369 rationalized languages and dialects being spoken across the country (INDIA, 2011). Of these, the 22 scheduled languages have a staggering total of 1.17 billion speakers and 121 languages have more than 10,000 speakers (INDIA, 2011). India also has the second largest (and an ever growing) digital footprint (Statista, 2020). Despite this, today's state-of-the-art multilingual systems perform suboptimally on Indian (IN) languages. This can be explained by the fact that multilingual language models (LMs) are often trained on 100+ languages together, leading to a small representation of IN languages in their vocabulary and training data. Multilingual LMs are substantially less effective in resource-lean scenarios (Wu and Dredze, 2020; Lauscher et al., 2020), as limited data doesn't help capture the various nuances of a language. One also commonly observes IN language text transliterated to Latin or code-mixed with English, especially in informal settings (for example, on social media platforms) (Rijhwani et al., 2017). This phenomenon is not adequately handled by current state-of-the-art multilingual LMs. To address the aforementioned gaps, we propose MuRIL, a multilingual LM specifically built for IN languages. MuRIL is trained on significantly large amounts of IN text corpora only. We explicitly augment monolingual text corpora with both translated and transliterated document pairs, that serve as supervised cross-lingual signals in training. MuRIL significantly outperforms multilingual BERT (mBERT) on all tasks in the challenging cross-lingual XTREME benchmark (Hu et al., 2020). We also present results on transliterated (native to Latin script) test sets of the chosen datasets and demonstrate the efficacy of MuRIL in handling transliterated data.