 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025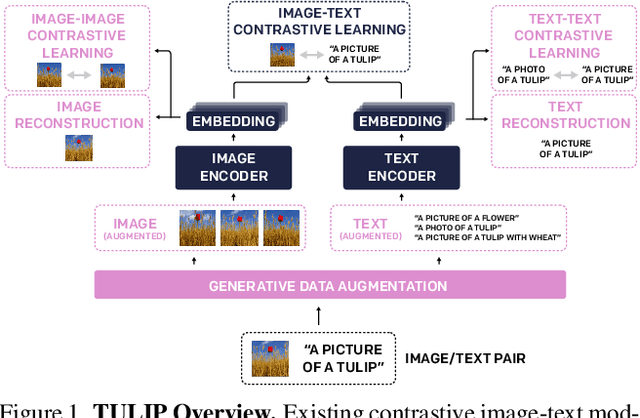
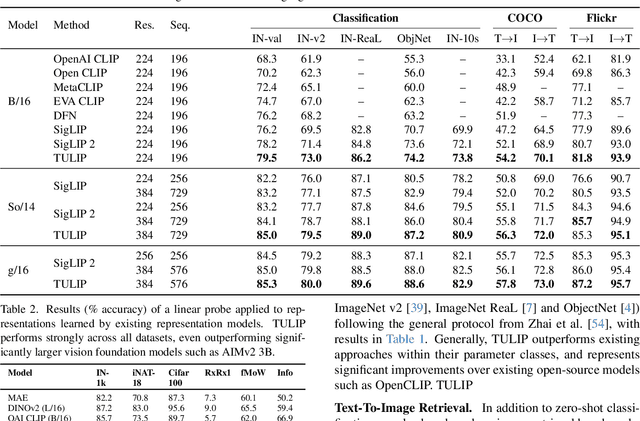
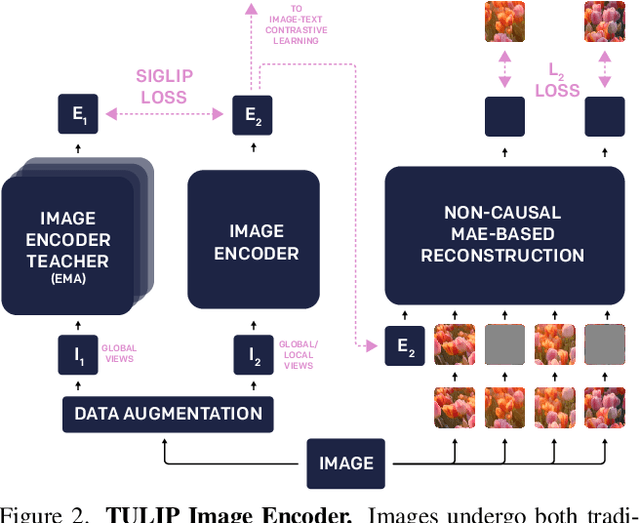
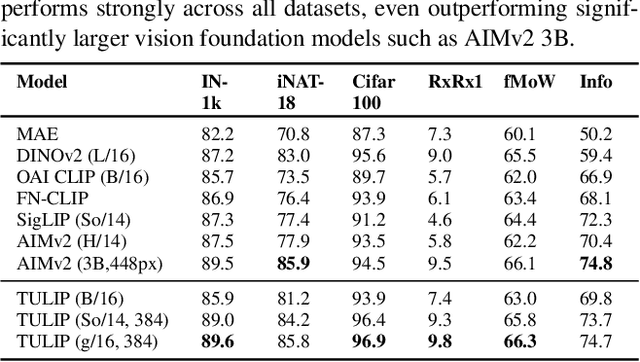
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
Evaluating Model Perception of Color Illusions in Photorealistic Scenes
Dec 09, 2024



We study the perception of color illusions by vision-language models. Color illusion, where a person's visual system perceives color differently from actual color, is well-studied in human vision. However, it remains underexplored whether vision-language models (VLMs), trained on large-scale human data, exhibit similar perceptual biases when confronted with such color illusions. We propose an automated framework for generating color illusion images, resulting in RCID (Realistic Color Illusion Dataset), a dataset of 19,000 realistic illusion images. Our experiments show that all studied VLMs exhibit perceptual biases similar human vision. Finally, we train a model to distinguish both human perception and actual pixel differences.
Grounding Language in Multi-Perspective Referential Communication
Oct 04, 2024
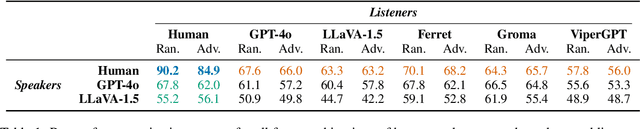
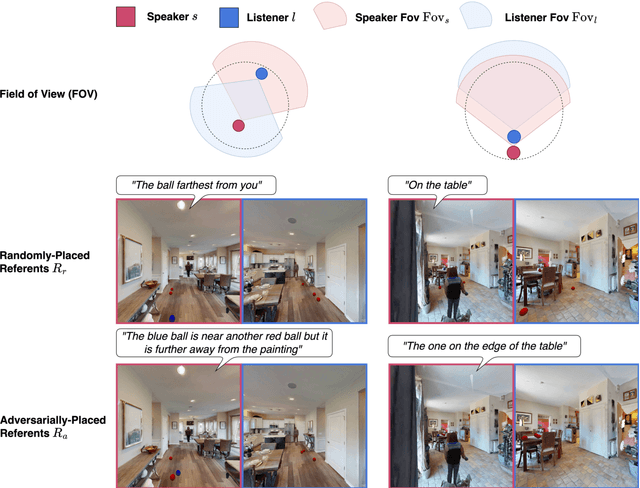
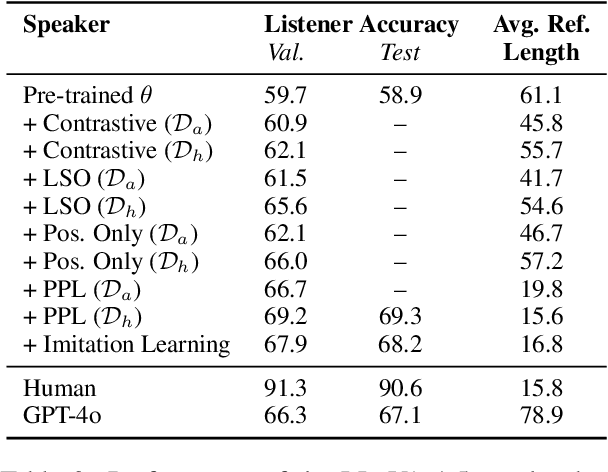
We introduce a task and dataset for referring expression generation and comprehension in multi-agent embodied environments. In this task, two agents in a shared scene must take into account one another's visual perspective, which may be different from their own, to both produce and understand references to objects in a scene and the spatial relations between them. We collect a dataset of 2,970 human-written referring expressions, each paired with human comprehension judgments, and evaluate the performance of automated models as speakers and listeners paired with human partners, finding that model performance in both reference generation and comprehension lags behind that of pairs of human agents. Finally, we experiment training an open-weight speaker model with evidence of communicative success when paired with a listener, resulting in an improvement from 58.9 to 69.3% in communicative success and even outperforming the strongest proprietary model.
AMONGAGENTS: Evaluating Large Language Models in the Interactive Text-Based Social Deduction Game
Jul 24, 2024

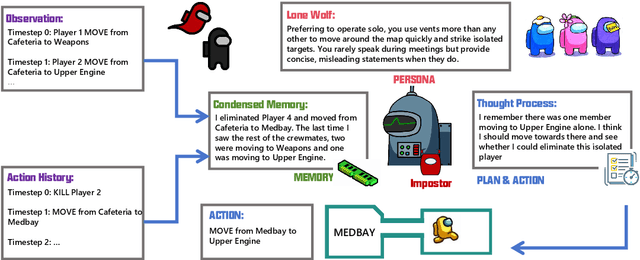

Strategic social deduction games serve as valuable testbeds for evaluating the understanding and inference skills of language models, offering crucial insights into social science, artificial intelligence, and strategic gaming. This paper focuses on creating proxies of human behavior in simulated environments, with Among Us utilized as a tool for studying simulated human behavior. The study introduces a text-based game environment, named AmongAgents, that mirrors the dynamics of Among Us. Players act as crew members aboard a spaceship, tasked with identifying impostors who are sabotaging the ship and eliminating the crew. Within this environment, the behavior of simulated language agents is analyzed. The experiments involve diverse game sequences featuring different configurations of Crewmates and Impostor personality archetypes. Our work demonstrates that state-of-the-art large language models (LLMs) can effectively grasp the game rules and make decisions based on the current context. This work aims to promote further exploration of LLMs in goal-oriented games with incomplete information and complex action spaces, as these settings offer valuable opportunities to assess language model performance in socially driven scenarios.
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023



We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
May 26, 2023



Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.
Any-to-Any Generation via Composable Diffusion
May 19, 2023



We present Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel and its input is not limited to a subset of modalities like text or image. Despite the absence of training datasets for many combinations of modalities, we propose to align modalities in both the input and output space. This allows CoDi to freely condition on any input combination and generate any group of modalities, even if they are not present in the training data. CoDi employs a novel composable generation strategy which involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio. Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis. The project page with demonstrations and code is at https://codi-gen.github.io
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 20, 2022



We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Nov 21, 2022We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy. Our code and checkpoints are available at: https://github.com/zinengtang/Perceiver_VL
TVLT: Textless Vision-Language Transformer
Sep 28, 2022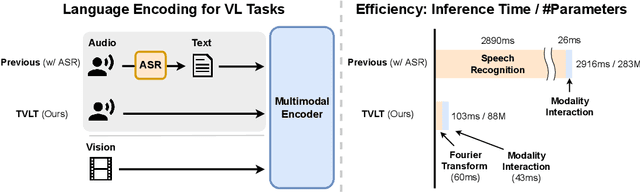
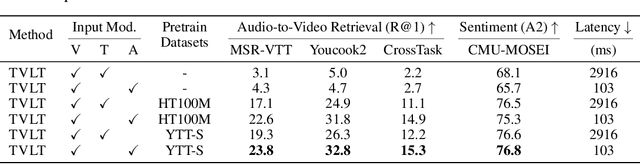
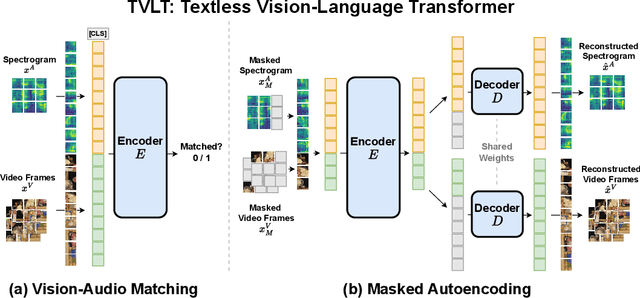
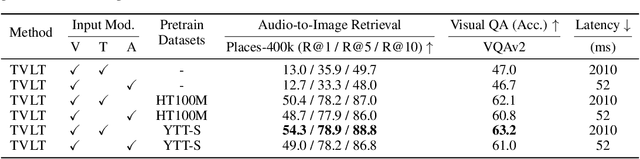
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart, on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text. Our code and checkpoints are available at: https://github.com/zinengtang/TVLT