 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
Human detectors are surprisingly powerful reward models
Jan 21, 2026Video generation models have recently achieved impressive visual fidelity and temporal coherence. Yet, they continue to struggle with complex, non-rigid motions, especially when synthesizing humans performing dynamic actions such as sports, dance, etc. Generated videos often exhibit missing or extra limbs, distorted poses, or physically implausible actions. In this work, we propose a remarkably simple reward model, HuDA, to quantify and improve the human motion in generated videos. HuDA integrates human detection confidence for appearance quality, and a temporal prompt alignment score to capture motion realism. We show this simple reward function that leverages off-the-shelf models without any additional training, outperforms specialized models finetuned with manually annotated data. Using HuDA for Group Reward Policy Optimization (GRPO) post-training of video models, we significantly enhance video generation, especially when generating complex human motions, outperforming state-of-the-art models like Wan 2.1, with win-rate of 73%. Finally, we demonstrate that HuDA improves generation quality beyond just humans, for instance, significantly improving generation of animal videos and human-object interactions.
Visually Prompted Benchmarks Are Surprisingly Fragile
Dec 19, 2025



A key challenge in evaluating VLMs is testing models' ability to analyze visual content independently from their textual priors. Recent benchmarks such as BLINK probe visual perception through visual prompting, where questions about visual content are paired with coordinates to which the question refers, with the coordinates explicitly marked in the image itself. While these benchmarks are an important part of VLM evaluation, we find that existing models are surprisingly fragile to seemingly irrelevant details of visual prompting: simply changing a visual marker from red to blue can completely change rankings among models on a leaderboard. By evaluating nine commonly-used open- and closed-source VLMs on two visually prompted tasks, we demonstrate how details in benchmark setup, including visual marker design and dataset size, have a significant influence on model performance and leaderboard rankings. These effects can even be exploited to lift weaker models above stronger ones; for instance, slightly increasing the size of the visual marker results in open-source InternVL3-8B ranking alongside or better than much larger proprietary models like Gemini 2.5 Pro. We further show that low-level inference choices that are often ignored in benchmarking, such as JPEG compression levels in API calls, can also cause model lineup changes. These details have substantially larger impacts on visually prompted benchmarks than on conventional semantic VLM evaluations. To mitigate this instability, we curate existing datasets to create VPBench, a larger visually prompted benchmark with 16 visual marker variants. VPBench and additional analysis tools are released at https://lisadunlap.github.io/vpbench/.
UnSAMv2: Self-Supervised Learning Enables Segment Anything at Any Granularity
Nov 17, 2025The Segment Anything Model (SAM) family has become a widely adopted vision foundation model, but its ability to control segmentation granularity remains limited. Users often need to refine results manually - by adding more prompts or selecting from pre-generated masks - to achieve the desired level of detail. This process can be ambiguous, as the same prompt may correspond to several plausible masks, and collecting dense annotations across all granularities is prohibitively expensive, making supervised solutions infeasible. To address this limitation, we introduce UnSAMv2, which enables segment anything at any granularity without human annotations. UnSAMv2 extends the divide-and-conquer strategy of UnSAM by discovering abundant mask-granularity pairs and introducing a novel granularity control embedding that enables precise, continuous control over segmentation scale. Remarkably, with only $6$K unlabeled images and $0.02\%$ additional parameters, UnSAMv2 substantially enhances SAM-2, achieving segment anything at any granularity across interactive, whole-image, and video segmentation tasks. Evaluated on over $11$ benchmarks, UnSAMv2 improves $\text{NoC}_{90}$ (5.69 $\rightarrow$ 4.75), 1-IoU (58.0 $\rightarrow$ 73.1), and $\text{AR}_{1000}$ (49.6 $\rightarrow$ 68.3), showing that small amounts of unlabeled data with a granularity-aware self-supervised learning method can unlock the potential of vision foundation models.
Reconstruction Alignment Improves Unified Multimodal Models
Sep 08, 2025Unified multimodal models (UMMs) unify visual understanding and generation within a single architecture. However, conventional training relies on image-text pairs (or sequences) whose captions are typically sparse and miss fine-grained visual details--even when they use hundreds of words to describe a simple image. We introduce Reconstruction Alignment (RecA), a resource-efficient post-training method that leverages visual understanding encoder embeddings as dense "text prompts," providing rich supervision without captions. Concretely, RecA conditions a UMM on its own visual understanding embeddings and optimizes it to reconstruct the input image with a self-supervised reconstruction loss, thereby realigning understanding and generation. Despite its simplicity, RecA is broadly applicable: across autoregressive, masked-autoregressive, and diffusion-based UMMs, it consistently improves generation and editing fidelity. With only 27 GPU-hours, post-training with RecA substantially improves image generation performance on GenEval (0.73$\rightarrow$0.90) and DPGBench (80.93$\rightarrow$88.15), while also boosting editing benchmarks (ImgEdit 3.38$\rightarrow$3.75, GEdit 6.94$\rightarrow$7.25). Notably, RecA surpasses much larger open-source models and applies broadly across diverse UMM architectures, establishing it as an efficient and general post-training alignment strategy for UMMs
TULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025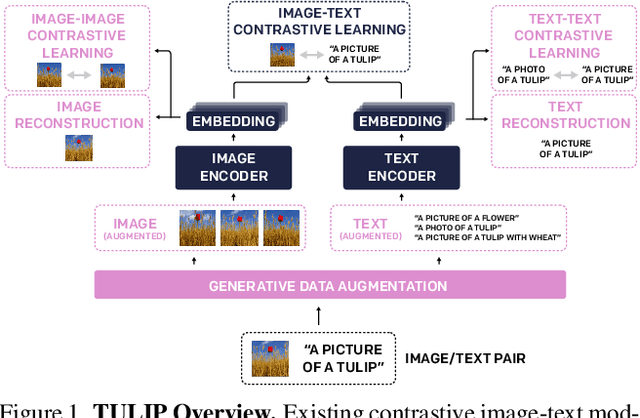
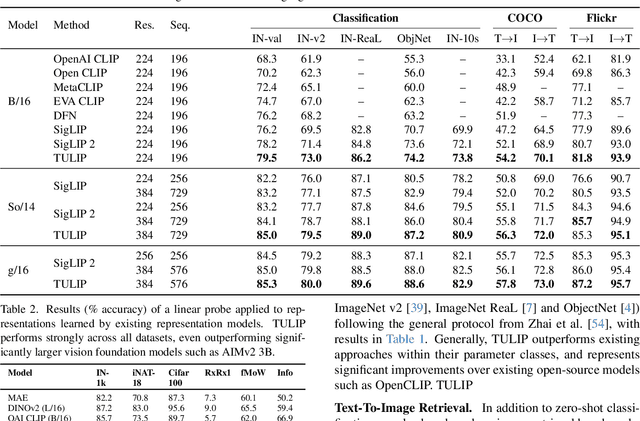
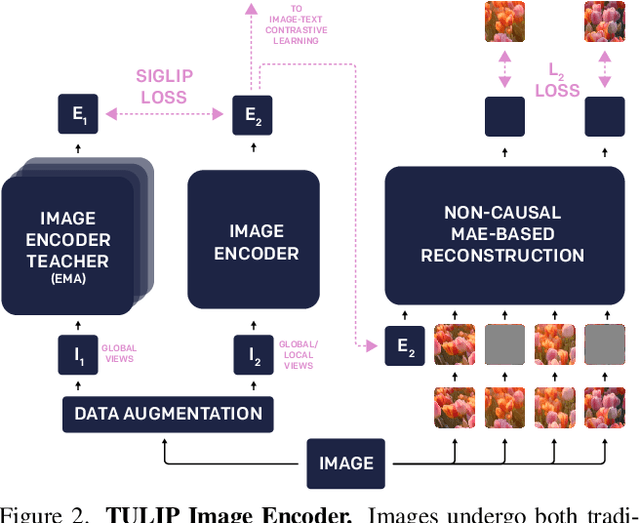
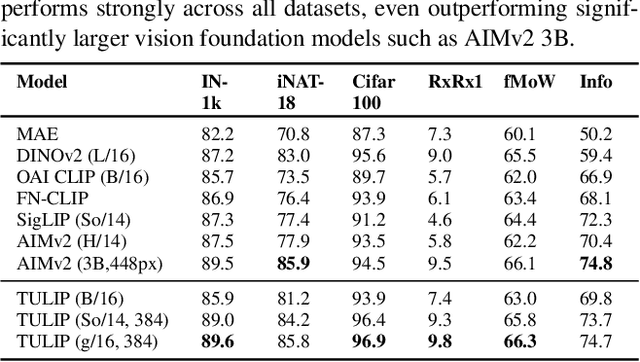
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
Visual Lexicon: Rich Image Features in Language Space
Dec 09, 2024
We present Visual Lexicon, a novel visual language that encodes rich image information into the text space of vocabulary tokens while retaining intricate visual details that are often challenging to convey in natural language. Unlike traditional methods that prioritize either high-level semantics (e.g., CLIP) or pixel-level reconstruction (e.g., VAE), ViLex simultaneously captures rich semantic content and fine visual details, enabling high-quality image generation and comprehensive visual scene understanding. Through a self-supervised learning pipeline, ViLex generates tokens optimized for reconstructing input images using a frozen text-to-image (T2I) diffusion model, preserving the detailed information necessary for high-fidelity semantic-level reconstruction. As an image embedding in the language space, ViLex tokens leverage the compositionality of natural languages, allowing them to be used independently as "text tokens" or combined with natural language tokens to prompt pretrained T2I models with both visual and textual inputs, mirroring how we interact with vision-language models (VLMs). Experiments demonstrate that ViLex achieves higher fidelity in image reconstruction compared to text embeddings--even with a single ViLex token. Moreover, ViLex successfully performs various DreamBooth tasks in a zero-shot, unsupervised manner without fine-tuning T2I models. Additionally, ViLex serves as a powerful vision encoder, consistently improving vision-language model performance across 15 benchmarks relative to a strong SigLIP baseline.
SegLLM: Multi-round Reasoning Segmentation
Oct 24, 2024



We present SegLLM, a novel multi-round interactive reasoning segmentation model that enhances LLM-based segmentation by exploiting conversational memory of both visual and textual outputs. By leveraging a mask-aware multimodal LLM, SegLLM re-integrates previous segmentation results into its input stream, enabling it to reason about complex user intentions and segment objects in relation to previously identified entities, including positional, interactional, and hierarchical relationships, across multiple interactions. This capability allows SegLLM to respond to visual and text queries in a chat-like manner. Evaluated on the newly curated MRSeg benchmark, SegLLM outperforms existing methods in multi-round interactive reasoning segmentation by over 20%. Additionally, we observed that training on multi-round reasoning segmentation data enhances performance on standard single-round referring segmentation and localization tasks, resulting in a 5.5% increase in cIoU for referring expression segmentation and a 4.5% improvement in Acc@0.5 for referring expression localization.
Segment Anything without Supervision
Jun 28, 2024The Segmentation Anything Model (SAM) requires labor-intensive data labeling. We present Unsupervised SAM (UnSAM) for promptable and automatic whole-image segmentation that does not require human annotations. UnSAM utilizes a divide-and-conquer strategy to "discover" the hierarchical structure of visual scenes. We first leverage top-down clustering methods to partition an unlabeled image into instance/semantic level segments. For all pixels within a segment, a bottom-up clustering method is employed to iteratively merge them into larger groups, thereby forming a hierarchical structure. These unsupervised multi-granular masks are then utilized to supervise model training. Evaluated across seven popular datasets, UnSAM achieves competitive results with the supervised counterpart SAM, and surpasses the previous state-of-the-art in unsupervised segmentation by 11% in terms of AR. Moreover, we show that supervised SAM can also benefit from our self-supervised labels. By integrating our unsupervised pseudo masks into SA-1B's ground-truth masks and training UnSAM with only 1% of SA-1B, a lightly semi-supervised UnSAM can often segment entities overlooked by supervised SAM, exceeding SAM's AR by over 6.7% and AP by 3.9% on SA-1B.