 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliveryBench: Can Agents Earn Profit in Real World?
Dec 22, 2025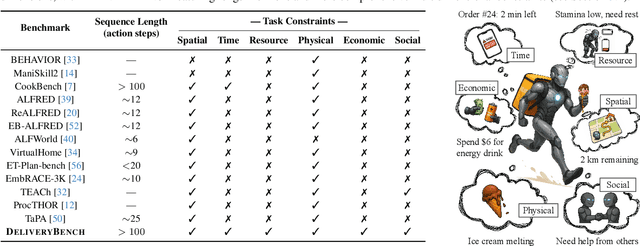
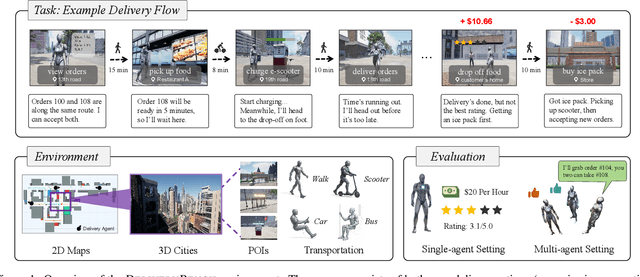
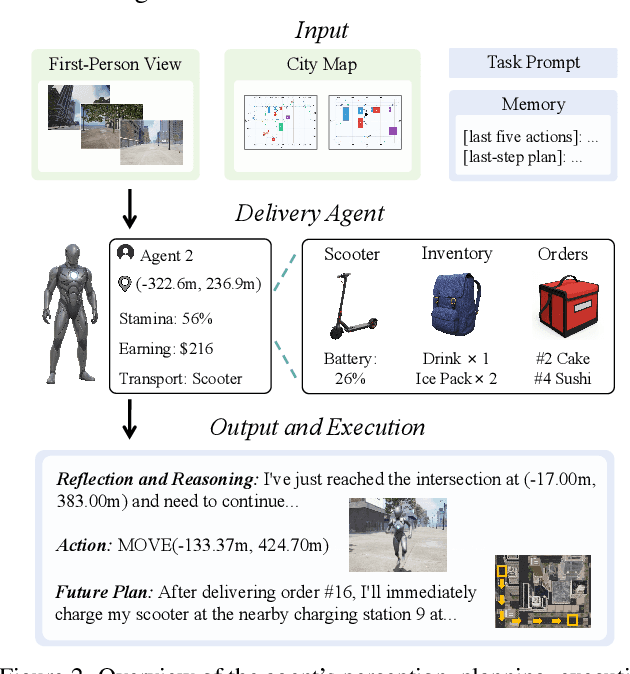
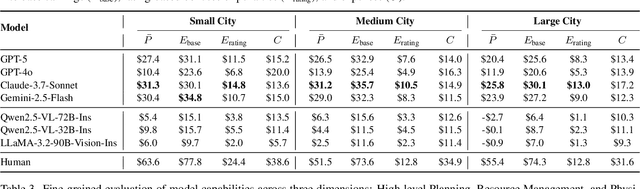
LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadline, transportation expense, vehicle battery, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning. We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments. Our code, data, and benchmark are available at https://deliverybench.github.io.
Evaluating Model Perception of Color Illusions in Photorealistic Scenes
Dec 09, 2024



We study the perception of color illusions by vision-language models. Color illusion, where a person's visual system perceives color differently from actual color, is well-studied in human vision. However, it remains underexplored whether vision-language models (VLMs), trained on large-scale human data, exhibit similar perceptual biases when confronted with such color illusions. We propose an automated framework for generating color illusion images, resulting in RCID (Realistic Color Illusion Dataset), a dataset of 19,000 realistic illusion images. Our experiments show that all studied VLMs exhibit perceptual biases similar human vision. Finally, we train a model to distinguish both human perception and actual pixel differences.
Grounding Language in Multi-Perspective Referential Communication
Oct 04, 2024
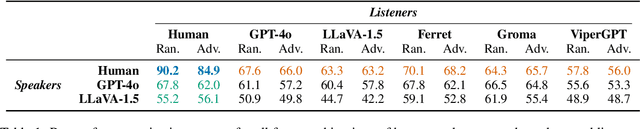
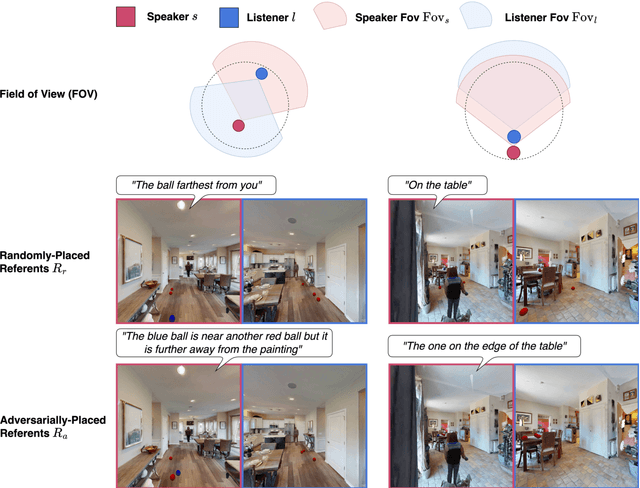
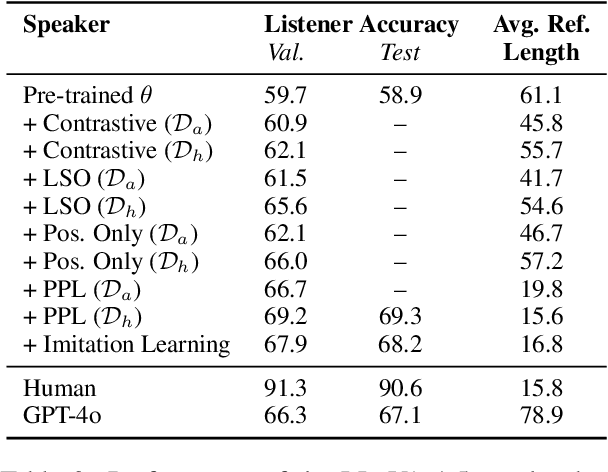
We introduce a task and dataset for referring expression generation and comprehension in multi-agent embodied environments. In this task, two agents in a shared scene must take into account one another's visual perspective, which may be different from their own, to both produce and understand references to objects in a scene and the spatial relations between them. We collect a dataset of 2,970 human-written referring expressions, each paired with human comprehension judgments, and evaluate the performance of automated models as speakers and listeners paired with human partners, finding that model performance in both reference generation and comprehension lags behind that of pairs of human agents. Finally, we experiment training an open-weight speaker model with evidence of communicative success when paired with a listener, resulting in an improvement from 58.9 to 69.3% in communicative success and even outperforming the strongest proprietary model.
AMONGAGENTS: Evaluating Large Language Models in the Interactive Text-Based Social Deduction Game
Jul 24, 2024

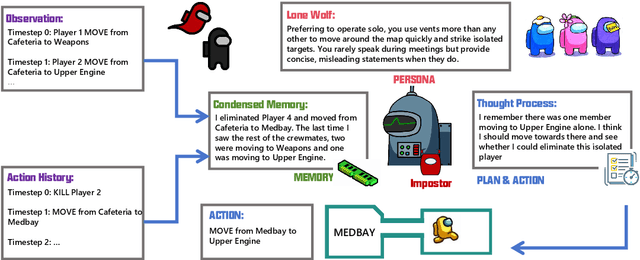

Strategic social deduction games serve as valuable testbeds for evaluating the understanding and inference skills of language models, offering crucial insights into social science, artificial intelligence, and strategic gaming. This paper focuses on creating proxies of human behavior in simulated environments, with Among Us utilized as a tool for studying simulated human behavior. The study introduces a text-based game environment, named AmongAgents, that mirrors the dynamics of Among Us. Players act as crew members aboard a spaceship, tasked with identifying impostors who are sabotaging the ship and eliminating the crew. Within this environment, the behavior of simulated language agents is analyzed. The experiments involve diverse game sequences featuring different configurations of Crewmates and Impostor personality archetypes. Our work demonstrates that state-of-the-art large language models (LLMs) can effectively grasp the game rules and make decisions based on the current context. This work aims to promote further exploration of LLMs in goal-oriented games with incomplete information and complex action spaces, as these settings offer valuable opportunities to assess language model performance in socially driven scenarios.
Biomedical Visual Instruction Tuning with Clinician Preference Alignment
Jun 19, 2024



Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets. While existing works have explored curating such datasets automatically, the resultant datasets are not explicitly aligned with domain expertise. In this work, we propose a data-centric framework, Biomedical Visual Instruction Tuning with Clinician Preference Alignment (BioMed-VITAL), that incorporates clinician preferences into both stages of generating and selecting instruction data for tuning biomedical multimodal foundation models. First, during the generation stage, we prompt the GPT-4V generator with a diverse set of clinician-selected demonstrations for preference-aligned data candidate generation. Then, during the selection phase, we train a separate selection model, which explicitly distills clinician and policy-guided model preferences into a rating function to select high-quality data for medical instruction tuning. Results show that the model tuned with the instruction-following data from our method demonstrates a significant improvement in open visual chat (18.5% relatively) and medical VQA (win rate up to 81.73%). Our instruction-following data and models are available at BioMed-VITAL.github.io.
BG-HGNN: Toward Scalable and Efficient Heterogeneous Graph Neural Network
Mar 13, 2024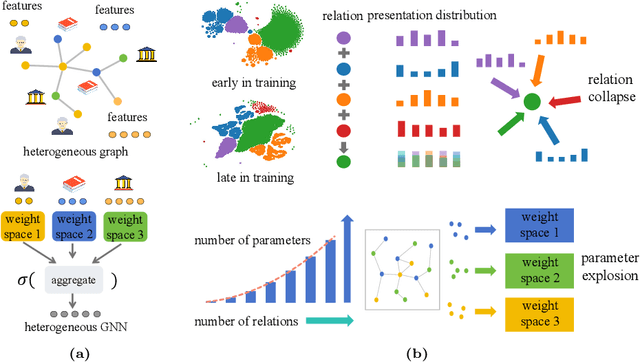
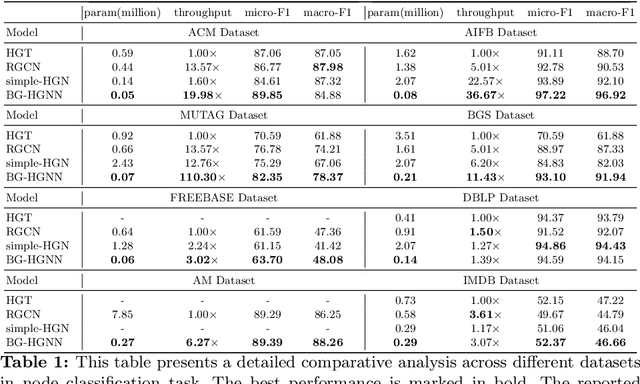
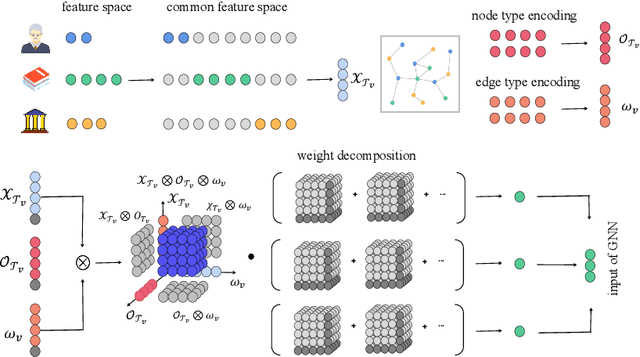
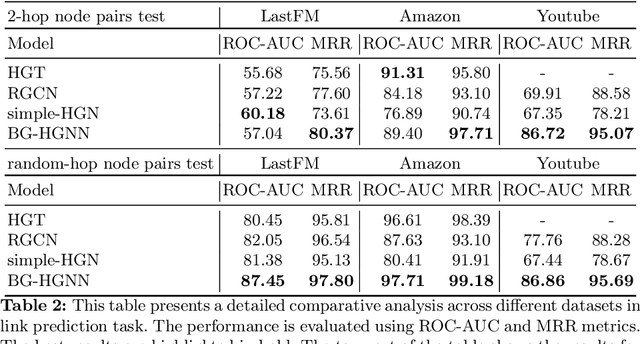
Many computer vision and machine learning problems are modelled as learning tasks on heterogeneous graphs, featuring a wide array of relations from diverse types of nodes and edges. Heterogeneous graph neural networks (HGNNs) stand out as a promising neural model class designed for heterogeneous graphs. Built on traditional GNNs, existing HGNNs employ different parameter spaces to model the varied relationships. However, the practical effectiveness of existing HGNNs is often limited to simple heterogeneous graphs with few relation types. This paper first highlights and demonstrates that the standard approach employed by existing HGNNs inevitably leads to parameter explosion and relation collapse, making HGNNs less effective or impractical for complex heterogeneous graphs with numerous relation types. To overcome this issue, we introduce a novel framework, Blend&Grind-HGNN (BG-HGNN), which effectively tackles the challenges by carefully integrating different relations into a unified feature space manageable by a single set of parameters. This results in a refined HGNN method that is more efficient and effective in learning from heterogeneous graphs, especially when the number of relations grows. Our empirical studies illustrate that BG-HGNN significantly surpasses existing HGNNs in terms of parameter efficiency (up to 28.96 $\times$), training throughput (up to 8.12 $\times$), and accuracy (up to 1.07 $\times$).
AI Agent as Urban Planner: Steering Stakeholder Dynamics in Urban Planning via Consensus-based Multi-Agent Reinforcement Learning
Oct 25, 2023In urban planning, land use readjustment plays a pivotal role in aligning land use configurations with the current demands for sustainable urban development. However, present-day urban planning practices face two main issues. Firstly, land use decisions are predominantly dependent on human experts. Besides, while resident engagement in urban planning can promote urban sustainability and livability, it is challenging to reconcile the diverse interests of stakeholders. To address these challenges, we introduce a Consensus-based Multi-Agent Reinforcement Learning framework for real-world land use readjustment. This framework serves participatory urban planning, allowing diverse intelligent agents as stakeholder representatives to vote for preferred land use types. Within this framework, we propose a novel consensus mechanism in reward design to optimize land utilization through collective decision making. To abstract the structure of the complex urban system, the geographic information of cities is transformed into a spatial graph structure and then processed by graph neural networks. Comprehensive experiments on both traditional top-down planning and participatory planning methods from real-world communities indicate that our computational framework enhances global benefits and accommodates diverse interests, leading to improved satisfaction across different demographic groups. By integrating Multi-Agent Reinforcement Learning, our framework ensures that participatory urban planning decisions are more dynamic and adaptive to evolving community needs and provides a robust platform for automating complex real-world urban planning processes.