 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-TP: A Grounded, Step-Level Dataset with Chain-of-Thought Reasoning for LLM-Guided Tensor Program Optimization
May 25, 2026Despite the strong reasoning capabilities of large language models (LLMs), optimizing the execution efficiency of tensor programs remains challenging due to the need for precise, composable transformation decisions. Recent LLM-guided approaches frame tensor program optimization as an iterative decision process, but existing datasets provide only end-to-end optimized program pairs using token-inefficient representations, lacking verifiable step-level supervision and interpretability. As a result, LLMs struggle to make reliable single-step decisions in large combinatorial optimization spaces. We introduce Step-TP, a post-training dataset for tensor program optimization that provides grounded, atomic, step-level supervision with structured chain-of-thought (CoT) reasoning. Step-TP forms a closed reasoning loop over intermediate program states, enabling reliable multi-step optimization rather than outcome imitation. Its design is guided by four principles: (i) a token-efficient, verifiable intermediate representation (IR) that deterministically lowers to TVM TIR; (ii) atomic and composable optimization strategies that decompose complex trajectories into interpretable single-step decisions; (iii) structured CoT supervision coupled with explicit IR-to-IR state transitions; and (iv) strategy filtering to balance coverage while preventing shortcut exploitation. The dataset and implementation are available at a GitHub link, https://github.com/LIUMENGFAN-gif/StepTP.
GeomHerd: A Forward-looking Herding Quantification via Ricci Flow Geometry on Agent Interactive Simulations
May 12, 2026Herding -- where agents align their behaviors and act collectively -- is a central driver of market fragility and systemic risk. Existing approaches to quantify herding rely on price-correlation statistics, which inherently lag because they only detect coordination after it has already moved realised returns. We propose GeomHerd, a forward-looking geometric framework that bypasses this observability lag by quantifying coordination directly on upstream agent-interaction graphs. To generate these graphs, we treat a heterogeneous LLM-driven multi-agent simulator -- each financial trader instantiated by a persona-conditioned LLM call -- as a forecastable world, and evaluate the geometric pipeline on the Cividino--Sornette continuous-spin agent-based substrate as our headline financial testbed. By tracking the discrete Ollivier--Ricci curvature of these action graphs, GeomHerd captures the structural topology of emerging coordination. Theoretically, we establish a mean-field bridge mapping our graph-theoretic metric to CSAD, the classical macroscopic herding statistic, linking GeomHerd to downstream price-dispersion measurement. Empirically, GeomHerd anticipates herding long before aggregate market baselines: on the continuous-spin substrate, our primary detector fires a median of 272 steps before order-parameter onset; a contagion detector ($β_{-}$) recalls 65% of critical trajectories 318 steps early; and on co-firing trajectories the agent-graph signal precedes price-correlation-graph baselines by 40 steps. As a complementary indicator, the effective vocabulary of agent actions contracts during cascades. The geometric signature transfers out-of-domain to the Vicsek self-driven-particle model, and a curvature-conditioned forecasting head reduces cascade-window log-return MAE over detector-conditioned and price-only baselines.
GAC: Stabilizing Asynchronous RL Training for LLMs via Gradient Alignment Control
Mar 02, 2026Asynchronous execution is essential for scaling reinforcement learning (RL) to modern large model workloads, including large language models and AI agents, but it can fundamentally alter RL optimization behavior. While prior work on asynchronous RL focuses on training throughput and distributional correction, we show that naively applying asynchrony to policy-gradient updates can induce qualitatively different training dynamics and lead to severe training instability. Through systematic empirical and theoretical analysis, we identify a key signature of this instability: asynchronous training exhibits persistently high cosine similarity between consecutive policy gradients, in contrast to the near-orthogonal updates observed under synchronized training. This stale-aligned gradient effect amplifies correlated updates and increases the risk of overshooting and divergence. Motivated by this observation, we propose GRADIENT ALIGNMENT CONTROL(GAC), a simple dynamics-aware stabilization method that regulates asynchronous RL progress along stale-aligned directions via gradient projection. We establish convergence guarantees under bounded staleness and demonstrate empirically that GAC recovers stable, on-policy training dynamics and matches synchronized baselines even at high staleness.
When Do Multi-Agent Systems Outperform? Analysing the Learning Efficiency of Agentic Systems
Feb 09, 2026Reinforcement Learning (RL) has emerged as a crucial method for training or fine-tuning large language models (LLMs), enabling adaptive, task-specific optimizations through interactive feedback. Multi-Agent Reinforcement Learning (MARL), in particular, offers a promising avenue by decomposing complex tasks into specialized subtasks learned by distinct interacting agents, potentially enhancing the ability and efficiency of LLM systems. However, theoretical insights regarding when and why MARL outperforms Single-Agent RL (SARL) remain limited, creating uncertainty in selecting the appropriate RL framework. In this paper, we address this critical gap by rigorously analyzing the comparative sample efficiency of MARL and SARL within the context of LLM. Leveraging the Probably Approximately Correct (PAC) framework, we formally define SARL and MARL setups for LLMs, derive explicit sample complexity bounds, and systematically characterize how task decomposition and alignment influence learning efficiency. Our results demonstrate that MARL improves sample complexity when tasks naturally decompose into independent subtasks, whereas dependent subtasks diminish MARL's comparative advantage. Additionally, we introduce and analyze the concept of task alignment, quantifying the trade-offs when enforcing independent task decomposition despite potential misalignments. These theoretical insights clarify empirical inconsistencies and provide practical criteria for deploying MARL strategies effectively in complex LLM scenarios.
ToolSelf: Unifying Task Execution and Self-Reconfiguration via Tool-Driven Intrinsic Adaptation
Feb 08, 2026Agentic systems powered by Large Language Models (LLMs) have demonstrated remarkable potential in tackling complex, long-horizon tasks. However, their efficacy is fundamentally constrained by static configurations governing agent behaviors, which are fixed prior to execution and fail to adapt to evolving task dynamics. Existing approaches, relying on manual orchestration or heuristic-based patches, often struggle with poor generalization and fragmented optimization. To transcend these limitations, we propose ToolSelf, a novel paradigm enabling tool-driven runtime self-reconfiguration. By abstracting configuration updates as a callable tool, ToolSelf unifies task execution and self-adjustment into a single action space, achieving a phase transition from external rules to intrinsic parameters. Agents can thereby autonomously update their sub-goals and context based on task progression, and correspondingly adapt their strategy and toolbox, transforming from passive executors into dual managers of both task and self. We further devise Configuration-Aware Two-stage Training (CAT), combining rejection sampling fine-tuning with trajectory-level reinforcement learning to internalize this meta-capability. Extensive experiments across diverse benchmarks demonstrate that ToolSelf rivals specialized workflows while generalizing to novel tasks, achieving a 24.1% average performance gain and illuminating a path toward truly self-adaptive agents.
Full-Graph vs. Mini-Batch Training: Comprehensive Analysis from a Batch Size and Fan-Out Size Perspective
Jan 30, 2026Full-graph and mini-batch Graph Neural Network (GNN) training approaches have distinct system design demands, making it crucial to choose the appropriate approach to develop. A core challenge in comparing these two GNN training approaches lies in characterizing their model performance (i.e., convergence and generalization) and computational efficiency. While a batch size has been an effective lens in analyzing such behaviors in deep neural networks (DNNs), GNNs extend this lens by introducing a fan-out size, as full-graph training can be viewed as mini-batch training with the largest possible batch size and fan-out size. However, the impact of the batch and fan-out size for GNNs remains insufficiently explored. To this end, this paper systematically compares full-graph vs. mini-batch training of GNNs through empirical and theoretical analyses from the view points of the batch size and fan-out size. Our key contributions include: 1) We provide a novel generalization analysis using the Wasserstein distance to study the impact of the graph structure, especially the fan-out size. 2) We uncover the non-isotropic effects of the batch size and the fan-out size in GNN convergence and generalization, providing practical guidance for tuning these hyperparameters under resource constraints. Finally, full-graph training does not always yield better model performance or computational efficiency than well-tuned smaller mini-batch settings. The implementation can be found in the github link: https://github.com/LIUMENGFAN-gif/GNN_fullgraph_minibatch_training.
SBGD: Improving Graph Diffusion Generative Model via Stochastic Block Diffusion
Aug 20, 2025

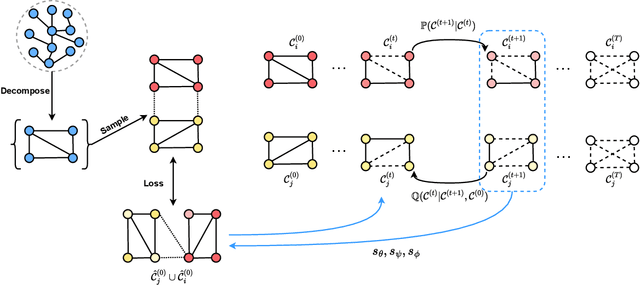

Graph diffusion generative models (GDGMs) have emerged as powerful tools for generating high-quality graphs. However, their broader adoption faces challenges in \emph{scalability and size generalization}. GDGMs struggle to scale to large graphs due to their high memory requirements, as they typically operate in the full graph space, requiring the entire graph to be stored in memory during training and inference. This constraint limits their feasibility for large-scale real-world graphs. GDGMs also exhibit poor size generalization, with limited ability to generate graphs of sizes different from those in the training data, restricting their adaptability across diverse applications. To address these challenges, we propose the stochastic block graph diffusion (SBGD) model, which refines graph representations into a block graph space. This space incorporates structural priors based on real-world graph patterns, significantly reducing memory complexity and enabling scalability to large graphs. The block representation also improves size generalization by capturing fundamental graph structures. Empirical results show that SBGD achieves significant memory improvements (up to 6$\times$) while maintaining comparable or even superior graph generation performance relative to state-of-the-art methods. Furthermore, experiments demonstrate that SBGD better generalizes to unseen graph sizes. The significance of SBGD extends beyond being a scalable and effective GDGM; it also exemplifies the principle of modularization in generative modeling, offering a new avenue for exploring generative models by decomposing complex tasks into more manageable components.
A Non-Asymptotic Convergent Analysis for Scored-Based Graph Generative Model via a System of Stochastic Differential Equations
Aug 20, 2025Score-based graph generative models (SGGMs) have proven effective in critical applications such as drug discovery and protein synthesis. However, their theoretical behavior, particularly regarding convergence, remains underexplored. Unlike common score-based generative models (SGMs), which are governed by a single stochastic differential equation (SDE), SGGMs involve a system of coupled SDEs. In SGGMs, the graph structure and node features are governed by separate but interdependent SDEs. This distinction makes existing convergence analyses from SGMs inapplicable for SGGMs. In this work, we present the first non-asymptotic convergence analysis for SGGMs, focusing on the convergence bound (the risk of generative error) across three key graph generation paradigms: (1) feature generation with a fixed graph structure, (2) graph structure generation with fixed node features, and (3) joint generation of both graph structure and node features. Our analysis reveals several unique factors specific to SGGMs (e.g., the topological properties of the graph structure) which affect the convergence bound. Additionally, we offer theoretical insights into the selection of hyperparameters (e.g., sampling steps and diffusion length) and advocate for techniques like normalization to improve convergence. To validate our theoretical findings, we conduct a controlled empirical study using synthetic graph models, and the results align with our theoretical predictions. This work deepens the theoretical understanding of SGGMs, demonstrates their applicability in critical domains, and provides practical guidance for designing effective models.
On the Interplay between Graph Structure and Learning Algorithms in Graph Neural Networks
Aug 20, 2025This paper studies the interplay between learning algorithms and graph structure for graph neural networks (GNNs). Existing theoretical studies on the learning dynamics of GNNs primarily focus on the convergence rates of learning algorithms under the interpolation regime (noise-free) and offer only a crude connection between these dynamics and the actual graph structure (e.g., maximum degree). This paper aims to bridge this gap by investigating the excessive risk (generalization performance) of learning algorithms in GNNs within the generalization regime (with noise). Specifically, we extend the conventional settings from the learning theory literature to the context of GNNs and examine how graph structure influences the performance of learning algorithms such as stochastic gradient descent (SGD) and Ridge regression. Our study makes several key contributions toward understanding the interplay between graph structure and learning in GNNs. First, we derive the excess risk profiles of SGD and Ridge regression in GNNs and connect these profiles to the graph structure through spectral graph theory. With this established framework, we further explore how different graph structures (regular vs. power-law) impact the performance of these algorithms through comparative analysis. Additionally, we extend our analysis to multi-layer linear GNNs, revealing an increasing non-isotropic effect on the excess risk profile, thereby offering new insights into the over-smoothing issue in GNNs from the perspective of learning algorithms. Our empirical results align with our theoretical predictions, \emph{collectively showcasing a coupling relation among graph structure, GNNs and learning algorithms, and providing insights on GNN algorithm design and selection in practice.}
Knowledge Augmented Complex Problem Solving with Large Language Models: A Survey
May 06, 2025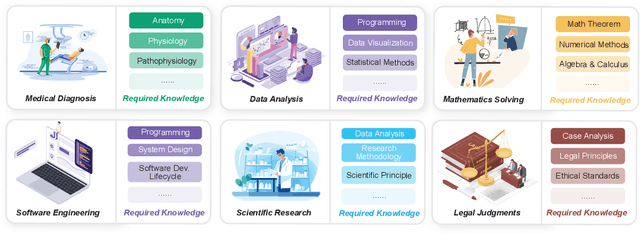
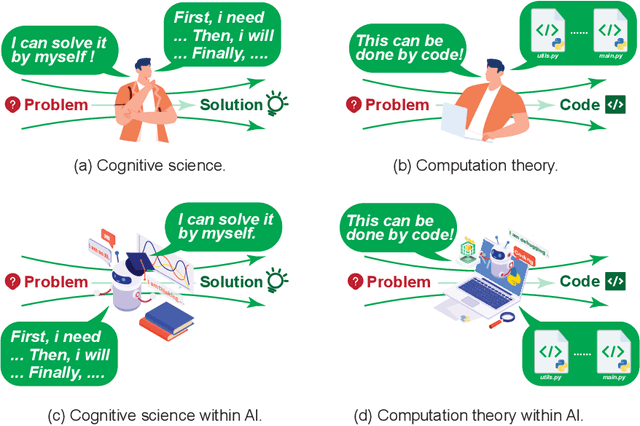
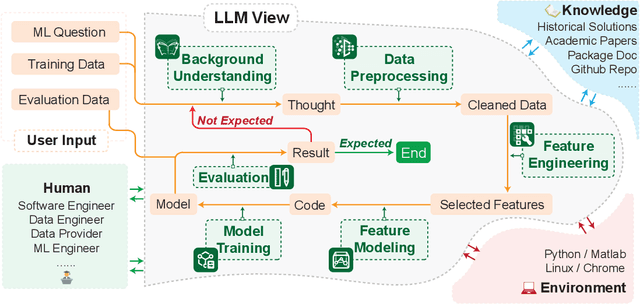
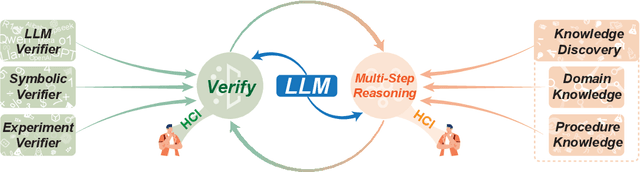
Problem-solving has been a fundamental driver of human progress in numerous domains. With advancements in artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of tackling complex problems across diverse domains. Unlike traditional computational systems, LLMs combine raw computational power with an approximation of human reasoning, allowing them to generate solutions, make inferences, and even leverage external computational tools. However, applying LLMs to real-world problem-solving presents significant challenges, including multi-step reasoning, domain knowledge integration, and result verification. This survey explores the capabilities and limitations of LLMs in complex problem-solving, examining techniques including Chain-of-Thought (CoT) reasoning, knowledge augmentation, and various LLM-based and tool-based verification techniques. Additionally, we highlight domain-specific challenges in various domains, such as software engineering, mathematical reasoning and proving, data analysis and modeling, and scientific research. The paper further discusses the fundamental limitations of the current LLM solutions and the future directions of LLM-based complex problems solving from the perspective of multi-step reasoning, domain knowledge integration and result verification.