 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Automated Decision-Making on Networks with LLMs through Knowledge-Guided Evolution
Jun 17, 2025Effective decision-making on networks often relies on learning from graph-structured data, where Graph Neural Networks (GNNs) play a central role, but they take efforts to configure and tune. In this demo, we propose LLMNet, showing how to design GNN automated through Large Language Models. Our system develops a set of agents that construct graph-related knowlege bases and then leverages Retrieval-Augmented Generation (RAG) to support automated configuration and refinement of GNN models through a knowledge-guided evolution process. These agents, equipped with specialized knowledge bases, extract insights into tasks and graph structures by interacting with the knowledge bases. Empirical results show LLMNet excels in twelve datasets across three graph learning tasks, validating its effectiveness of GNN model designing.
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Jun 12, 2025Large Language Model (LLM) agents have shown great potential in addressing real-world data science problems. LLM-driven data science agents promise to automate the entire machine learning pipeline, yet their real-world effectiveness remains limited. Existing frameworks depend on rigid, pre-defined workflows and inflexible coding strategies; consequently, they excel only on relatively simple, classical problems and fail to capture the empirical expertise that human practitioners bring to complex, innovative tasks. In this work, we introduce AutoMind, an adaptive, knowledgeable LLM-agent framework that overcomes these deficiencies through three key advances: (1) a curated expert knowledge base that grounds the agent in domain expert knowledge, (2) an agentic knowledgeable tree search algorithm that strategically explores possible solutions, and (3) a self-adaptive coding strategy that dynamically tailors code generation to task complexity. Evaluations on two automated data science benchmarks demonstrate that AutoMind delivers superior performance versus state-of-the-art baselines. Additional analyses confirm favorable effectiveness, efficiency, and qualitative solution quality, highlighting AutoMind as an efficient and robust step toward fully automated data science.
Knowledge Augmented Complex Problem Solving with Large Language Models: A Survey
May 06, 2025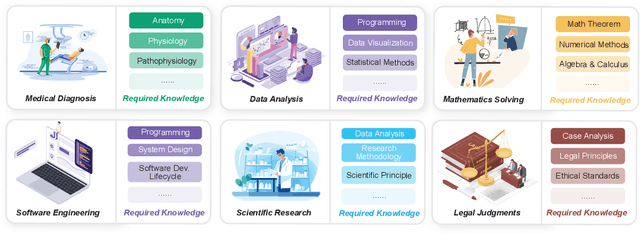
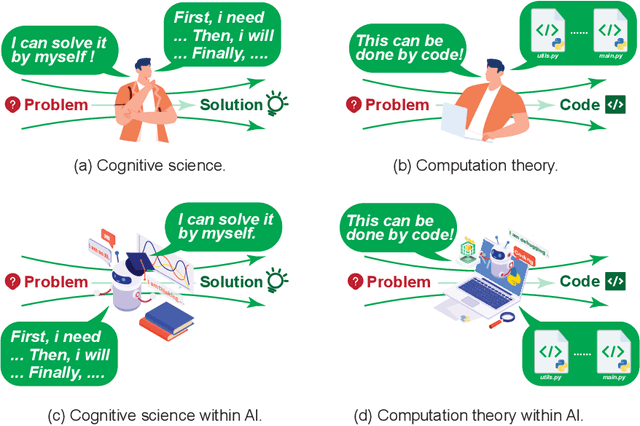
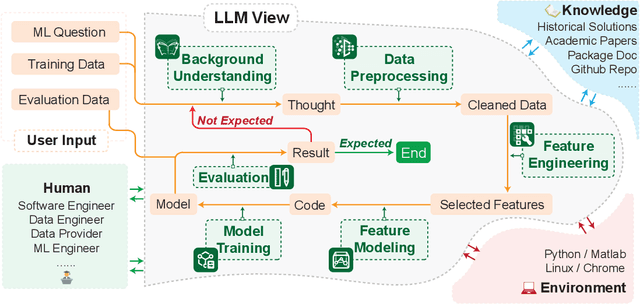
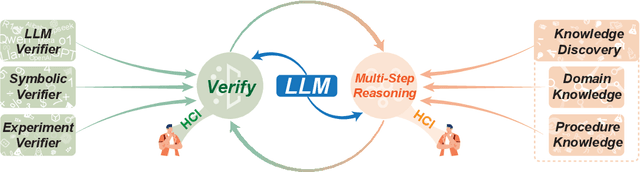
Problem-solving has been a fundamental driver of human progress in numerous domains. With advancements in artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of tackling complex problems across diverse domains. Unlike traditional computational systems, LLMs combine raw computational power with an approximation of human reasoning, allowing them to generate solutions, make inferences, and even leverage external computational tools. However, applying LLMs to real-world problem-solving presents significant challenges, including multi-step reasoning, domain knowledge integration, and result verification. This survey explores the capabilities and limitations of LLMs in complex problem-solving, examining techniques including Chain-of-Thought (CoT) reasoning, knowledge augmentation, and various LLM-based and tool-based verification techniques. Additionally, we highlight domain-specific challenges in various domains, such as software engineering, mathematical reasoning and proving, data analysis and modeling, and scientific research. The paper further discusses the fundamental limitations of the current LLM solutions and the future directions of LLM-based complex problems solving from the perspective of multi-step reasoning, domain knowledge integration and result verification.
OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
Dec 28, 2024


We introduce OneKE, a dockerized schema-guided knowledge extraction system, which can extract knowledge from the Web and raw PDF Books, and support various domains (science, news, etc.). Specifically, we design OneKE with multiple agents and a configure knowledge base. Different agents perform their respective roles, enabling support for various extraction scenarios. The configure knowledge base facilitates schema configuration, error case debugging and correction, further improving the performance. Empirical evaluations on benchmark datasets demonstrate OneKE's efficacy, while case studies further elucidate its adaptability to diverse tasks across multiple domains, highlighting its potential for broad applications. We have open-sourced the Code at https://github.com/zjunlp/OneKE and released a Video at http://oneke.openkg.cn/demo.mp4.
Heuristic Learning with Graph Neural Networks: A Unified Framework for Link Prediction
Jun 12, 2024Link prediction is a fundamental task in graph learning, inherently shaped by the topology of the graph. While traditional heuristics are grounded in graph topology, they encounter challenges in generalizing across diverse graphs. Recent research efforts have aimed to leverage the potential of heuristics, yet a unified formulation accommodating both local and global heuristics remains undiscovered. Drawing insights from the fact that both local and global heuristics can be represented by adjacency matrix multiplications, we propose a unified matrix formulation to accommodate and generalize various heuristics. We further propose the Heuristic Learning Graph Neural Network (HL-GNN) to efficiently implement the formulation. HL-GNN adopts intra-layer propagation and inter-layer connections, allowing it to reach a depth of around 20 layers with lower time complexity than GCN. HL-GNN is proven to be more expressive than heuristics and conventional GNNs, and it can adaptively trade-off between node features and topological information. Extensive experiments on the Planetoid, Amazon, and OGB datasets underscore the effectiveness and efficiency of HL-GNN. It outperforms existing methods by a large margin in prediction performance. Additionally, HL-GNN is several orders of magnitude faster than heuristic-inspired methods while requiring only a few trainable parameters. The case study further demonstrates that the generalized heuristics and learned weights are highly interpretable.
Towards Versatile Graph Learning Approach: from the Perspective of Large Language Models
Feb 23, 2024Graph-structured data are the commonly used and have wide application scenarios in the real world. For these diverse applications, the vast variety of learning tasks, graph domains, and complex graph learning procedures present challenges for human experts when designing versatile graph learning approaches. Facing these challenges, large language models (LLMs) offer a potential solution due to the extensive knowledge and the human-like intelligence. This paper proposes a novel conceptual prototype for designing versatile graph learning methods with LLMs, with a particular focus on the "where" and "how" perspectives. From the "where" perspective, we summarize four key graph learning procedures, including task definition, graph data feature engineering, model selection and optimization, deployment and serving. We then explore the application scenarios of LLMs in these procedures across a wider spectrum. In the "how" perspective, we align the abilities of LLMs with the requirements of each procedure. Finally, we point out the promising directions that could better leverage the strength of LLMs towards versatile graph learning methods.
Unleashing the Power of Graph Learning through LLM-based Autonomous Agents
Sep 08, 2023Graph structured data are widely existed and applied in the real-world applications, while it is a challenge to handling these diverse data and learning tasks on graph in an efficient manner. When facing the complicated graph learning tasks, experts have designed diverse Graph Neural Networks (GNNs) in recent years. They have also implemented AutoML in Graph, also known as AutoGraph, to automatically generate data-specific solutions. Despite their success, they encounter limitations in (1) managing diverse learning tasks at various levels, (2) dealing with different procedures in graph learning beyond architecture design, and (3) the huge requirements on the prior knowledge when using AutoGraph. In this paper, we propose to use Large Language Models (LLMs) as autonomous agents to simplify the learning process on diverse real-world graphs. Specifically, in response to a user request which may contain varying data and learning targets at the node, edge, or graph levels, the complex graph learning task is decomposed into three components following the agent planning, namely, detecting the learning intent, configuring solutions based on AutoGraph, and generating a response. The AutoGraph agents manage crucial procedures in automated graph learning, including data-processing, AutoML configuration, searching architectures, and hyper-parameter fine-tuning. With these agents, those components are processed by decomposing and completing step by step, thereby generating a solution for the given data automatically, regardless of the learning task on node or graph. The proposed method is dubbed Auto$^2$Graph, and the comparable performance on different datasets and learning tasks. Its effectiveness is demonstrated by its comparable performance on different datasets and learning tasks, as well as the human-like decisions made by the agents.
Search to Capture Long-range Dependency with Stacking GNNs for Graph Classification
Feb 17, 2023In recent years, Graph Neural Networks (GNNs) have been popular in the graph classification task. Currently, shallow GNNs are more common due to the well-known over-smoothing problem facing deeper GNNs. However, they are sub-optimal without utilizing the information from distant nodes, i.e., the long-range dependencies. The mainstream methods in the graph classification task can extract the long-range dependencies either by designing the pooling operations or incorporating the higher-order neighbors, while they have evident drawbacks by modifying the original graph structure, which may result in information loss in graph structure learning. In this paper, by justifying the smaller influence of the over-smoothing problem in the graph classification task, we evoke the importance of stacking-based GNNs and then employ them to capture the long-range dependencies without modifying the original graph structure. To achieve this, two design needs are given for stacking-based GNNs, i.e., sufficient model depth and adaptive skip-connection schemes. By transforming the two design needs into designing data-specific inter-layer connections, we propose a novel approach with the help of neural architecture search (NAS), which is dubbed LRGNN (Long-Range Graph Neural Networks). Extensive experiments on five datasets show that the proposed LRGNN can achieve the best performance, and obtained data-specific GNNs with different depth and skip-connection schemes, which can better capture the long-range dependencies.
Enhancing Intra-class Information Extraction for Heterophilous Graphs: One Neural Architecture Search Approach
Nov 20, 2022



In recent years, Graph Neural Networks (GNNs) have been popular in graph representation learning which assumes the homophily property, i.e., the connected nodes have the same label or have similar features. However, they may fail to generalize into the heterophilous graphs which in the low/medium level of homophily. Existing methods tend to address this problem by enhancing the intra-class information extraction, i.e., either by designing better GNNs to improve the model effectiveness, or re-designing the graph structures to incorporate more potential intra-class nodes from distant hops. Despite the success, we observe two aspects that can be further improved: (a) enhancing the ego feature information extraction from node itself which is more reliable in extracting the intra-class information; (b) designing node-wise GNNs can better adapt to the nodes with different homophily ratios. In this paper, we propose a novel method IIE-GNN (Intra-class Information Enhanced Graph Neural Networks) to achieve two improvements. A unified framework is proposed based on the literature, in which the intra-class information from the node itself and neighbors can be extracted based on seven carefully designed blocks. With the help of neural architecture search (NAS), we propose a novel search space based on the framework, and then provide an architecture predictor to design GNNs for each node. We further conduct experiments to show that IIE-GNN can improve the model performance by designing node-wise GNNs to enhance intra-class information extraction.