 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025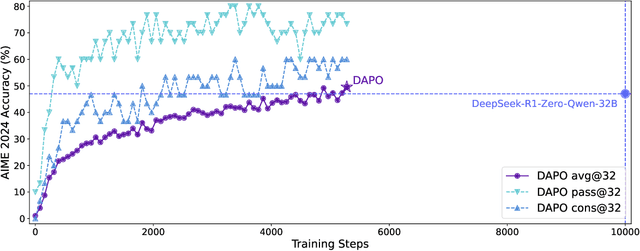

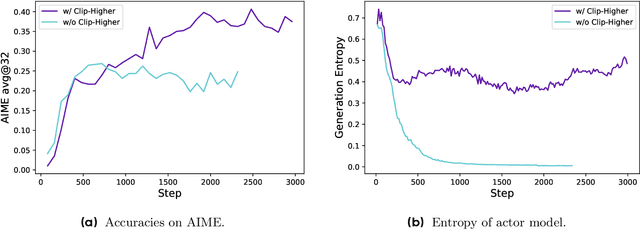

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
HybridFlow: A Flexible and Efficient RLHF Framework
Sep 28, 2024



Reinforcement Learning from Human Feedback (RLHF) is widely used in Large Language Model (LLM) alignment. Traditional RL can be modeled as a dataflow, where each node represents computation of a neural network (NN) and each edge denotes data dependencies between the NNs. RLHF complicates the dataflow by expanding each node into a distributed LLM training or generation program, and each edge into a many-to-many multicast. Traditional RL frameworks execute the dataflow using a single controller to instruct both intra-node computation and inter-node communication, which can be inefficient in RLHF due to large control dispatch overhead for distributed intra-node computation. Existing RLHF systems adopt a multi-controller paradigm, which can be inflexible due to nesting distributed computation and data communication. We propose HybridFlow, which combines single-controller and multi-controller paradigms in a hybrid manner to enable flexible representation and efficient execution of the RLHF dataflow. We carefully design a set of hierarchical APIs that decouple and encapsulate computation and data dependencies in the complex RLHF dataflow, allowing efficient operation orchestration to implement RLHF algorithms and flexible mapping of the computation onto various devices. We further design a 3D-HybridEngine for efficient actor model resharding between training and generation phases, with zero memory redundancy and significantly reduced communication overhead. Our experimental results demonstrate 1.53$\times$~20.57$\times$ throughput improvement when running various RLHF algorithms using HybridFlow, as compared with state-of-the-art baselines. HybridFlow source code is available at https://github.com/volcengine/verl.
MSPipe: Efficient Temporal GNN Training via Staleness-aware Pipeline
Feb 23, 2024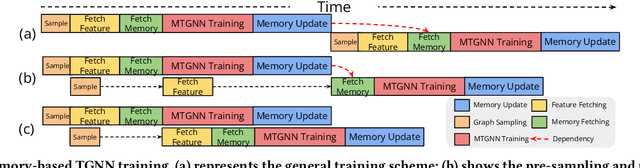
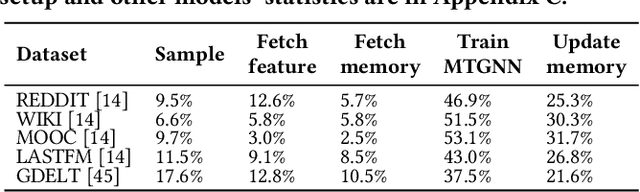
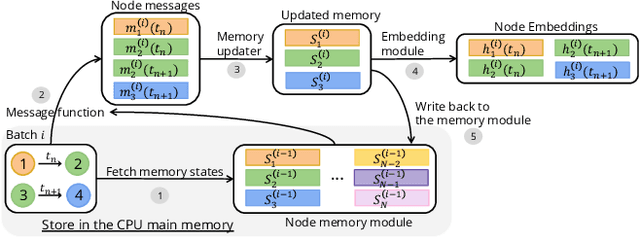
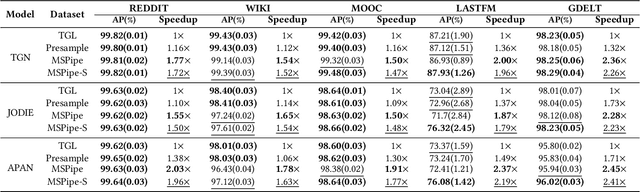
Memory-based Temporal Graph Neural Networks (MTGNNs) are a class of temporal graph neural networks that utilize a node memory module to capture and retain long-term temporal dependencies, leading to superior performance compared to memory-less counterparts. However, the iterative reading and updating process of the memory module in MTGNNs to obtain up-to-date information needs to follow the temporal dependencies. This introduces significant overhead and limits training throughput. Existing optimizations for static GNNs are not directly applicable to MTGNNs due to differences in training paradigm, model architecture, and the absence of a memory module. Moreover, they do not effectively address the challenges posed by temporal dependencies, making them ineffective for MTGNN training. In this paper, we propose MSPipe, a general and efficient framework for MTGNNs that maximizes training throughput while maintaining model accuracy. Our design addresses the unique challenges associated with fetching and updating node memory states in MTGNNs by integrating staleness into the memory module. However, simply introducing a predefined staleness bound in the memory module to break temporal dependencies may lead to suboptimal performance and lack of generalizability across different models and datasets. To solve this, we introduce an online pipeline scheduling algorithm in MSPipe that strategically breaks temporal dependencies with minimal staleness and delays memory fetching to obtain fresher memory states. Moreover, we design a staleness mitigation mechanism to enhance training convergence and model accuracy. We provide convergence analysis and prove that MSPipe maintains the same convergence rate as vanilla sample-based GNN training. Experimental results show that MSPipe achieves up to 2.45x speed-up without sacrificing accuracy, making it a promising solution for efficient MTGNN training.
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023



Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.