 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide&Seek: Remove Image Watermarks with Negligible Cost via Pixel-wise Reconstruction
Mar 01, 2026Watermarking has emerged as a key defense against the misuse of machine-generated images (MGIs). Yet the robustness of these protections remains underexplored. To reveal the limits of SOTA proactive image watermarking defenses, we propose HIDE&SEEK (HS), a suite of versatile and cost-effective attacks that reliably remove embedded watermarks while preserving high visual fidelity.
Turning Black Box into White Box: Dataset Distillation Leaks
Mar 01, 2026Dataset distillation compresses a large real dataset into a small synthetic one, enabling models trained on the synthetic data to achieve performance comparable to those trained on the real data. Although synthetic datasets are assumed to be privacy-preserving, we show that existing distillation methods can cause severe privacy leakage because synthetic datasets implicitly encode the weight trajectories of the distilled model, they become over-informative and exploitable by adversaries. To expose this risk, we introduce the Information Revelation Attack (IRA) against state-of-the-art distillation techniques. Experiments show that IRA accurately predicts both the distillation algorithm and model architecture, and can successfully infer membership and recover sensitive samples from the real dataset.
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023



Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.
dPRO: A Generic Profiling and Optimization System for Expediting Distributed DNN Training
May 18, 2022



Distributed training using multiple devices (e.g., GPUs) has been widely adopted for learning DNN models over large datasets. However, the performance of large-scale distributed training tends to be far from linear speed-up in practice. Given the complexity of distributed systems, it is challenging to identify the root cause(s) of inefficiency and exercise effective performance optimizations when unexpected low training speed occurs. To date, there exists no software tool which diagnoses performance issues and helps expedite distributed DNN training, while the training can be run using different deep learning frameworks. This paper proposes dPRO, a toolkit that includes: (1) an efficient profiler that collects runtime traces of distributed DNN training across multiple frameworks, especially fine-grained communication traces, and constructs global data flow graphs including detailed communication operations for accurate replay; (2) an optimizer that effectively identifies performance bottlenecks and explores optimization strategies (from computation, communication, and memory aspects) for training acceleration. We implement dPRO on multiple deep learning frameworks (TensorFlow, MXNet) and representative communication schemes (AllReduce and Parameter Server). Extensive experiments show that dPRO predicts the performance of distributed training in various settings with < 5% errors in most cases and finds optimization strategies with up to 3.48x speed-up over the baselines.
Compressed Communication for Distributed Training: Adaptive Methods and System
May 17, 2021


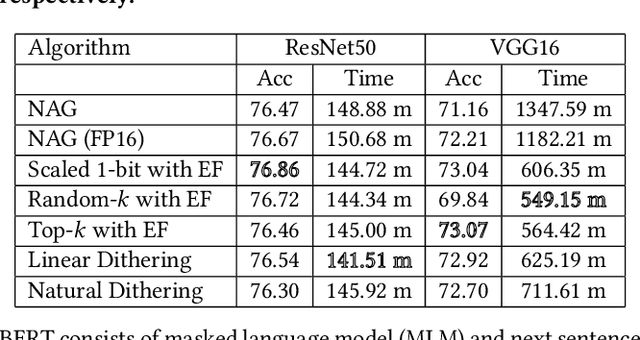
Communication overhead severely hinders the scalability of distributed machine learning systems. Recently, there has been a growing interest in using gradient compression to reduce the communication overhead of the distributed training. However, there is little understanding of applying gradient compression to adaptive gradient methods. Moreover, its performance benefits are often limited by the non-negligible compression overhead. In this paper, we first introduce a novel adaptive gradient method with gradient compression. We show that the proposed method has a convergence rate of $\mathcal{O}(1/\sqrt{T})$ for non-convex problems. In addition, we develop a scalable system called BytePS-Compress for two-way compression, where the gradients are compressed in both directions between workers and parameter servers. BytePS-Compress pipelines the compression and decompression on CPUs and achieves a high degree of parallelism. Empirical evaluations show that we improve the training time of ResNet50, VGG16, and BERT-base by 5.0%, 58.1%, 23.3%, respectively, without any accuracy loss with 25 Gb/s networking. Furthermore, for training the BERT models, we achieve a compression rate of 333x compared to the mixed-precision training.
Thin Structure Estimation with Curvature Regularization
Sep 16, 2015



Many applications in vision require estimation of thin structures such as boundary edges, surfaces, roads, blood vessels, neurons, etc. Unlike most previous approaches, we simultaneously detect and delineate thin structures with sub-pixel localization and real-valued orientation estimation. This is an ill-posed problem that requires regularization. We propose an objective function combining detection likelihoods with a prior minimizing curvature of the center-lines or surfaces. Unlike simple block-coordinate descent, we develop a novel algorithm that is able to perform joint optimization of location and detection variables more effectively. Our lower bound optimization algorithm applies to quadratic or absolute curvature. The proposed early vision framework is sufficiently general and it can be used in many higher-level applications. We illustrate the advantage of our approach on a range of 2D and 3D examples.
* D. Marin, Y. Zhong, M. Drangova, Y. Boykov. Thin Structure Estimation with Curvature Regularization. International Conference on Computer Vision (ICCV), Santiago, Chili, December 2015, to appear