 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiMixQA: A Multimodal Benchmark for Question Answering over Tables and Charts
Jun 18, 2025Documents are fundamental to preserving and disseminating information, often incorporating complex layouts, tables, and charts that pose significant challenges for automatic document understanding (DU). While vision-language large models (VLLMs) have demonstrated improvements across various tasks, their effectiveness in processing long-context vision inputs remains unclear. This paper introduces WikiMixQA, a benchmark comprising 1,000 multiple-choice questions (MCQs) designed to evaluate cross-modal reasoning over tables and charts extracted from 4,000 Wikipedia pages spanning seven distinct topics. Unlike existing benchmarks, WikiMixQA emphasizes complex reasoning by requiring models to synthesize information from multiple modalities. We evaluate 12 state-of-the-art vision-language models, revealing that while proprietary models achieve ~70% accuracy when provided with direct context, their performance deteriorates significantly when retrieval from long documents is required. Among these, GPT-4-o is the only model exceeding 50% accuracy in this setting, whereas open-source models perform considerably worse, with a maximum accuracy of 27%. These findings underscore the challenges of long-context, multi-modal reasoning and establish WikiMixQA as a crucial benchmark for advancing document understanding research.
TableRAG: Million-Token Table Understanding with Language Models
Oct 07, 2024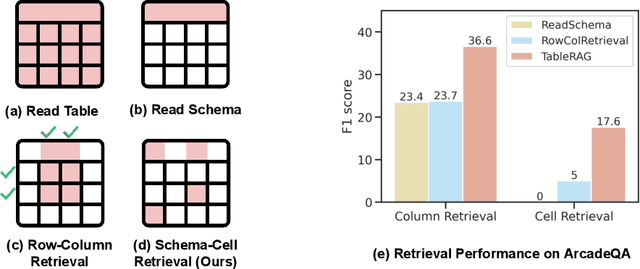
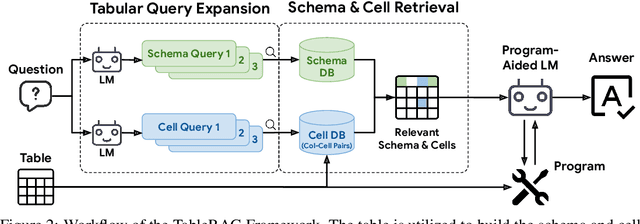
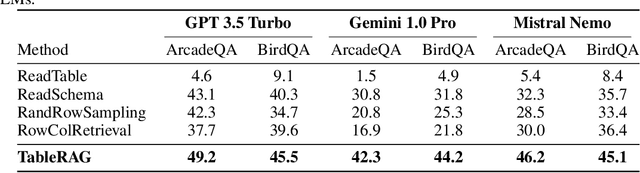
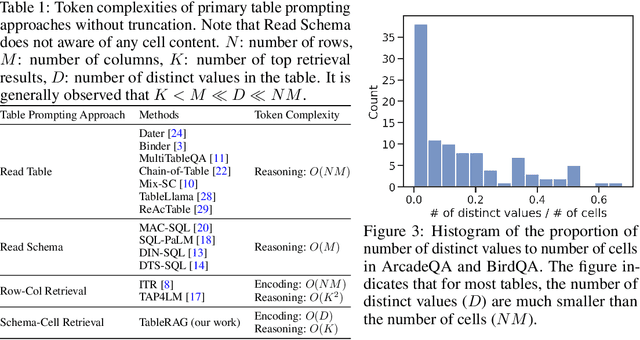
Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables. However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints. In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding. TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs. This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss. We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale. Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
Selectively Answering Visual Questions
Jun 03, 2024



Recently, large multi-modal models (LMMs) have emerged with the capacity to perform vision tasks such as captioning and visual question answering (VQA) with unprecedented accuracy. Applications such as helping the blind or visually impaired have a critical need for precise answers. It is specially important for models to be well calibrated and be able to quantify their uncertainty in order to selectively decide when to answer and when to abstain or ask for clarifications. We perform the first in-depth analysis of calibration methods and metrics for VQA with in-context learning LMMs. Studying VQA on two answerability benchmarks, we show that the likelihood score of visually grounded models is better calibrated than in their text-only counterparts for in-context learning, where sampling based methods are generally superior, but no clear winner arises. We propose Avg BLEU, a calibration score combining the benefits of both sampling and likelihood methods across modalities.
Faithful Chart Summarization with ChaTS-Pi
May 29, 2024



Chart-to-summary generation can help explore data, communicate insights, and help the visually impaired people. Multi-modal generative models have been used to produce fluent summaries, but they can suffer from factual and perceptual errors. In this work we present CHATS-CRITIC, a reference-free chart summarization metric for scoring faithfulness. CHATS-CRITIC is composed of an image-to-text model to recover the table from a chart, and a tabular entailment model applied to score the summary sentence by sentence. We find that CHATS-CRITIC evaluates the summary quality according to human ratings better than reference-based metrics, either learned or n-gram based, and can be further used to fix candidate summaries by removing not supported sentences. We then introduce CHATS-PI, a chart-to-summary pipeline that leverages CHATS-CRITIC during inference to fix and rank sampled candidates from any chart-summarization model. We evaluate CHATS-PI and CHATS-CRITIC using human raters, establishing state-of-the-art results on two popular chart-to-summary datasets.
TANQ: An open domain dataset of table answered questions
May 13, 2024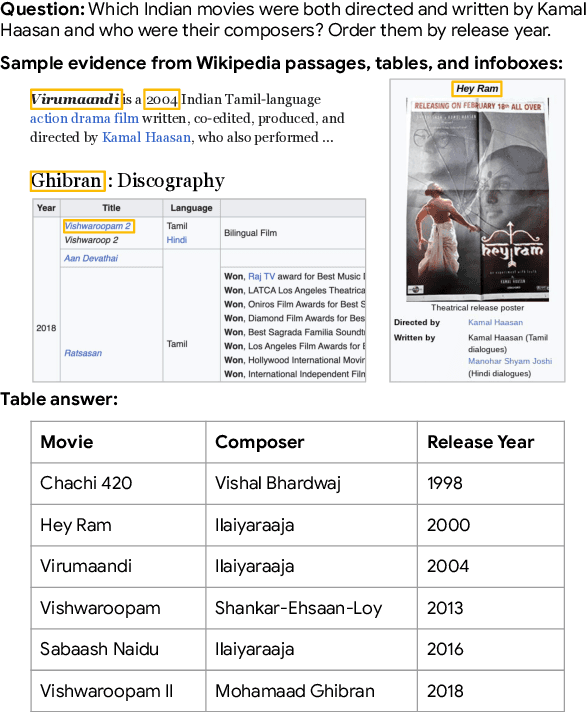
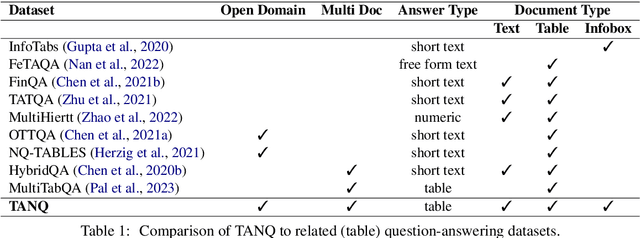
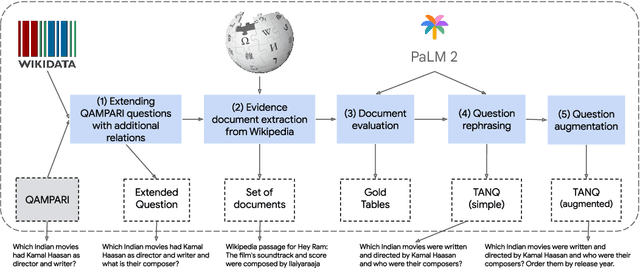
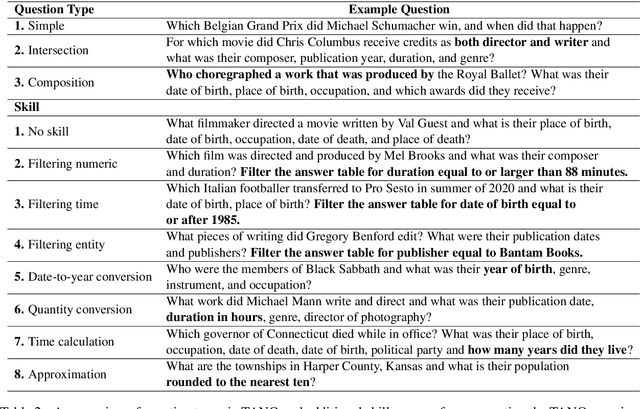
Language models, potentially augmented with tool usage such as retrieval are becoming the go-to means of answering questions. Understanding and answering questions in real-world settings often requires retrieving information from different sources, processing and aggregating data to extract insights, and presenting complex findings in form of structured artifacts such as novel tables, charts, or infographics. In this paper, we introduce TANQ, the first open domain question answering dataset where the answers require building tables from information across multiple sources. We release the full source attribution for every cell in the resulting table and benchmark state-of-the-art language models in open, oracle, and closed book setups. Our best-performing baseline, GPT4 reaches an overall F1 score of 29.1, lagging behind human performance by 19.7 points. We analyse baselines' performance across different dataset attributes such as different skills required for this task, including multi-hop reasoning, math operations, and unit conversions. We further discuss common failures in model-generated answers, suggesting that TANQ is a complex task with many challenges ahead.
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding
Jan 19, 2024Table-based reasoning with large language models (LLMs) is a promising direction to tackle many table understanding tasks, such as table-based question answering and fact verification. Compared with generic reasoning, table-based reasoning requires the extraction of underlying semantics from both free-form questions and semi-structured tabular data. Chain-of-Thought and its similar approaches incorporate the reasoning chain in the form of textual context, but it is still an open question how to effectively leverage tabular data in the reasoning chain. We propose the Chain-of-Table framework, where tabular data is explicitly used in the reasoning chain as a proxy for intermediate thoughts. Specifically, we guide LLMs using in-context learning to iteratively generate operations and update the table to represent a tabular reasoning chain. LLMs can therefore dynamically plan the next operation based on the results of the previous ones. This continuous evolution of the table forms a chain, showing the reasoning process for a given tabular problem. The chain carries structured information of the intermediate results, enabling more accurate and reliable predictions. Chain-of-Table achieves new state-of-the-art performance on WikiTQ, FeTaQA, and TabFact benchmarks across multiple LLM choices.
Selectively Answering Ambiguous Questions
May 24, 2023Trustworthy language models should abstain from answering questions when they do not know the answer. However, the answer to a question can be unknown for a variety of reasons. Prior research has focused on the case in which the question is clear and the answer is unambiguous but possibly unknown. However, the answer to a question can also be unclear due to uncertainty of the questioner's intent or context. We investigate question answering from this perspective, focusing on answering a subset of questions with a high degree of accuracy, from a set of questions in which many are inherently ambiguous. In this setting, we find that the most reliable approach to calibration involves quantifying repetition within a set of sampled model outputs, rather than the model's likelihood or self-verification as used in prior work. % We find this to be the case across different types of uncertainty, varying model scales and both with or without instruction tuning. Our results suggest that sampling-based confidence scores help calibrate answers to relatively unambiguous questions, with more dramatic improvements on ambiguous questions.
Universal Self-adaptive Prompting
May 24, 2023



A hallmark of modern large language models (LLMs) is their impressive general zero-shot and few-shot abilities, often elicited through prompt-based and/or in-context learning. However, while highly coveted and being the most general, zero-shot performances in LLMs are still typically weaker due to the lack of guidance and the difficulty of applying existing automatic prompt design methods in general tasks when ground-truth labels are unavailable. In this study, we address this by presenting Universal Self-adaptive Prompting (USP), an automatic prompt design approach specifically tailored for zero-shot learning (while compatible with few-shot). Requiring only a small amount of unlabeled data & an inference-only LLM, USP is highly versatile: to achieve universal prompting, USP categorizes a possible NLP task into one of the three possible task types, and then uses a corresponding selector to select the most suitable queries & zero-shot model-generated responses as pseudo-demonstrations, thereby generalizing ICL to the zero-shot setup in a fully automated way. We evaluate zero-shot USP with two PaLM models, and demonstrate performances that are considerably stronger than standard zero-shot baselines and are comparable to or even superior than few-shot baselines across more than 20 natural language understanding (NLU) and natural language generation (NLG) tasks.
DIFFQG: Generating Questions to Summarize Factual Changes
Mar 01, 2023
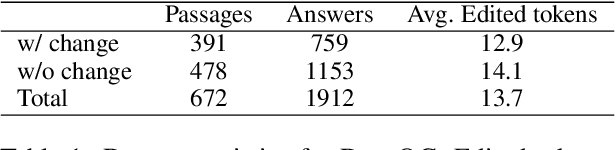
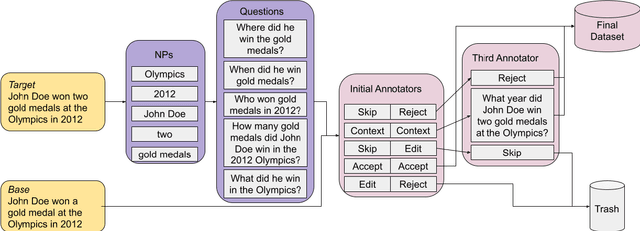
Identifying the difference between two versions of the same article is useful to update knowledge bases and to understand how articles evolve. Paired texts occur naturally in diverse situations: reporters write similar news stories and maintainers of authoritative websites must keep their information up to date. We propose representing factual changes between paired documents as question-answer pairs, where the answer to the same question differs between two versions. We find that question-answer pairs can flexibly and concisely capture the updated contents. Provided with paired documents, annotators identify questions that are answered by one passage but answered differently or cannot be answered by the other. We release DIFFQG which consists of 759 QA pairs and 1153 examples of paired passages with no factual change. These questions are intended to be both unambiguous and information-seeking and involve complex edits, pushing beyond the capabilities of current question generation and factual change detection systems. Our dataset summarizes the changes between two versions of the document as questions and answers, studying automatic update summarization in a novel way.
DePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022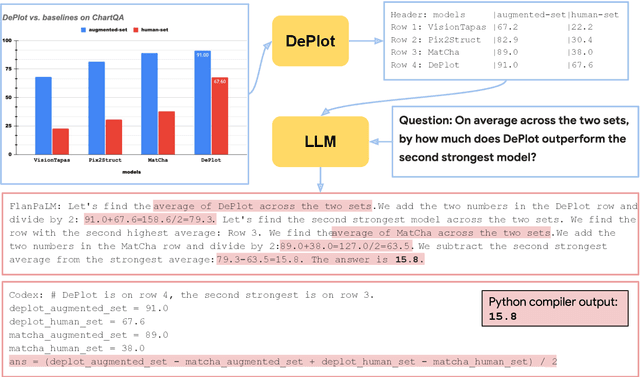
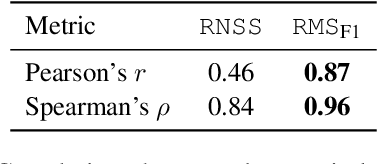
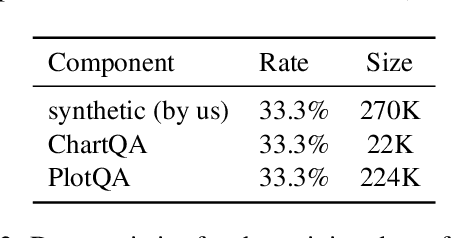
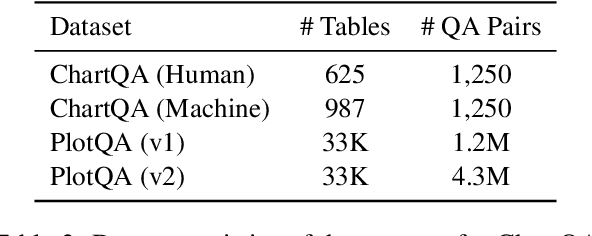
Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.