 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards culturally-appropriate conversational AI for health in the majority world: An exploratory study with citizens and professionals in Latin America
Jul 02, 2025There is justifiable interest in leveraging conversational AI (CAI) for health across the majority world, but to be effective, CAI must respond appropriately within culturally and linguistically diverse contexts. Therefore, we need ways to address the fact that current LLMs exclude many lived experiences globally. Various advances are underway which focus on top-down approaches and increasing training data. In this paper, we aim to complement these with a bottom-up locally-grounded approach based on qualitative data collected during participatory workshops in Latin America. Our goal is to construct a rich and human-centred understanding of: a) potential areas of cultural misalignment in digital health; b) regional perspectives on chatbots for health and c)strategies for creating culturally-appropriate CAI; with a focus on the understudied Latin American context. Our findings show that academic boundaries on notions of culture lose meaning at the ground level and technologies will need to engage with a broader framework; one that encapsulates the way economics, politics, geography and local logistics are entangled in cultural experience. To this end, we introduce a framework for 'Pluriversal Conversational AI for Health' which allows for the possibility that more relationality and tolerance, rather than just more data, may be called for.
Low-resource domain adaptation while minimizing energy and hardware resource consumption
Jun 11, 2025Training Large Language Models (LLMs) is costly in terms of energy, hardware, and annotated data, often resulting in a positionality rooted in predominant cultures and values (Santy et al., 2023). Domain adaptation has emerged as a promising strategy to better align models with diverse cultural and value contexts (Hershcovich et al., 2022), but its computational cost remains a significant barrier, particularly for research groups lacking access to large-scale infrastructure. In this paper, we evaluate how the use of different numerical precision formats and data parallelization strategies impacts both training speed (as a proxy to energy and hardware consumption) and model accuracy, with the goal of facilitating domain adaptation in low-resource environments. Our findings are relevant to any setting where energy efficiency, accessibility, or limited hardware availability are key concerns.
HESEIA: A community-based dataset for evaluating social biases in large language models, co-designed in real school settings in Latin America
May 30, 2025Most resources for evaluating social biases in Large Language Models are developed without co-design from the communities affected by these biases, and rarely involve participatory approaches. We introduce HESEIA, a dataset of 46,499 sentences created in a professional development course. The course involved 370 high-school teachers and 5,370 students from 189 Latin-American schools. Unlike existing benchmarks, HESEIA captures intersectional biases across multiple demographic axes and school subjects. It reflects local contexts through the lived experience and pedagogical expertise of educators. Teachers used minimal pairs to create sentences that express stereotypes relevant to their school subjects and communities. We show the dataset diversity in term of demographic axes represented and also in terms of the knowledge areas included. We demonstrate that the dataset contains more stereotypes unrecognized by current LLMs than previous datasets. HESEIA is available to support bias assessments grounded in educational communities.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Selectively Answering Visual Questions
Jun 03, 2024



Recently, large multi-modal models (LMMs) have emerged with the capacity to perform vision tasks such as captioning and visual question answering (VQA) with unprecedented accuracy. Applications such as helping the blind or visually impaired have a critical need for precise answers. It is specially important for models to be well calibrated and be able to quantify their uncertainty in order to selectively decide when to answer and when to abstain or ask for clarifications. We perform the first in-depth analysis of calibration methods and metrics for VQA with in-context learning LMMs. Studying VQA on two answerability benchmarks, we show that the likelihood score of visually grounded models is better calibrated than in their text-only counterparts for in-context learning, where sampling based methods are generally superior, but no clear winner arises. We propose Avg BLEU, a calibration score combining the benefits of both sampling and likelihood methods across modalities.
A tool to overcome technical barriers for bias assessment in human language technologies
Jul 14, 2022
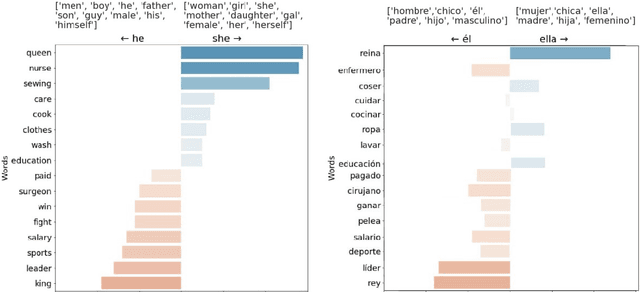

Automatic processing of language is becoming pervasive in our lives, often taking central roles in our decision making, like choosing the wording for our messages and mails, translating our readings, or even having full conversations with us. Word embeddings are a key component of modern natural language processing systems. They provide a representation of words that has boosted the performance of many applications, working as a semblance of meaning. Word embeddings seem to capture a semblance of the meaning of words from raw text, but, at the same time, they also distill stereotypes and societal biases which are subsequently relayed to the final applications. Such biases can be discriminatory. It is very important to detect and mitigate those biases, to prevent discriminatory behaviors of automated processes, which can be much more harmful than in the case of humans because their of their scale. There are currently many tools and techniques to detect and mitigate biases in word embeddings, but they present many barriers for the engagement of people without technical skills. As it happens, most of the experts in bias, either social scientists or people with deep knowledge of the context where bias is harmful, do not have such skills, and they cannot engage in the processes of bias detection because of the technical barriers. We have studied the barriers in existing tools and have explored their possibilities and limitations with different kinds of users. With this exploration, we propose to develop a tool that is specially aimed to lower the technical barriers and provide the exploration power to address the requirements of experts, scientists and people in general who are willing to audit these technologies.
A recipe for annotating grounded clarifications
Apr 18, 2021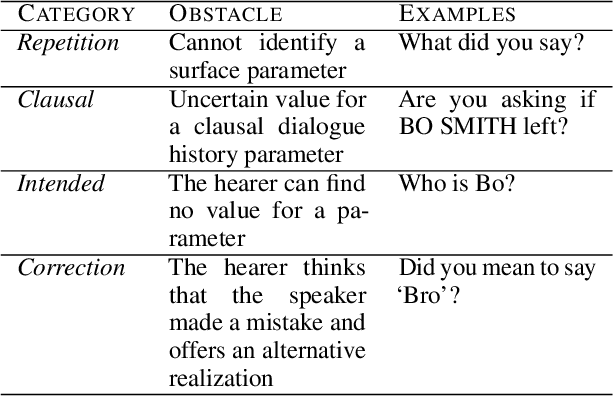



In order to interpret the communicative intents of an utterance, it needs to be grounded in something that is outside of language; that is, grounded in world modalities. In this paper, we argue that dialogue clarification mechanisms make explicit the process of interpreting the communicative intents of the speaker's utterances by grounding them in the various modalities in which the dialogue is situated. This paper frames dialogue clarification mechanisms as an understudied research problem and a key missing piece in the giant jigsaw puzzle of natural language understanding. We discuss both the theoretical background and practical challenges posed by this problem and propose a recipe for obtaining grounding annotations. We conclude by highlighting ethical issues that need to be addressed in future work.