 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Coordination Across a Diverse Set of Input Modalities
Jan 29, 2024Cross-modal retrieval is the task of retrieving samples of a given modality by using queries of a different one. Due to the wide range of practical applications, the problem has been mainly focused on the vision and language case, e.g. text to image retrieval, where models like CLIP have proven effective in solving such tasks. The dominant approach to learning such coordinated representations consists of projecting them onto a common space where matching views stay close and those from non-matching pairs are pushed away from each other. Although this cross-modal coordination has been applied also to other pairwise combinations, extending it to an arbitrary number of diverse modalities is a problem that has not been fully explored in the literature. In this paper, we propose two different approaches to the problem. The first is based on an extension of the CLIP contrastive objective to an arbitrary number of input modalities, while the second departs from the contrastive formulation and tackles the coordination problem by regressing the cross-modal similarities towards a target that reflects two simple and intuitive constraints of the cross-modal retrieval task. We run experiments on two different datasets, over different combinations of input modalities and show that the approach is not only simple and effective but also allows for tackling the retrieval problem in novel ways. Besides capturing a more diverse set of pair-wise interactions, we show that we can use the learned representations to improve retrieval performance by combining the embeddings from two or more such modalities.
A tool to overcome technical barriers for bias assessment in human language technologies
Jul 14, 2022
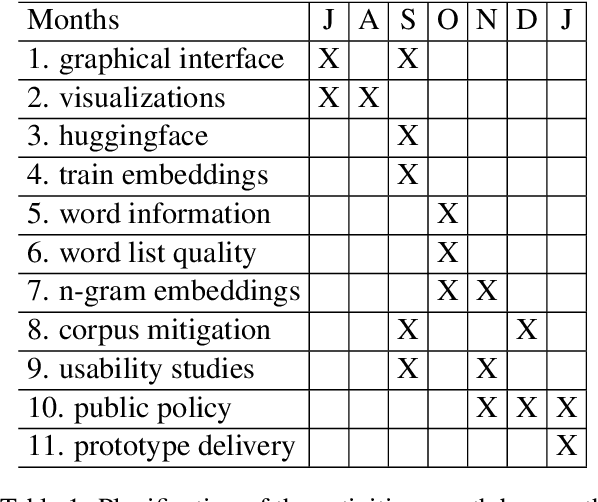
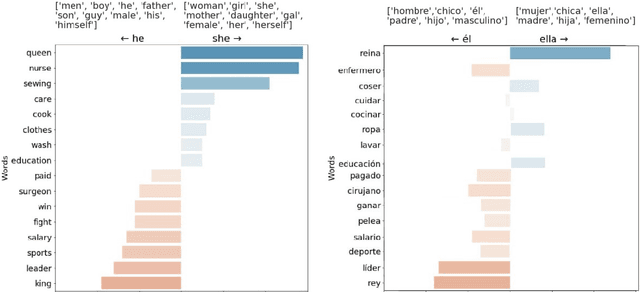

Automatic processing of language is becoming pervasive in our lives, often taking central roles in our decision making, like choosing the wording for our messages and mails, translating our readings, or even having full conversations with us. Word embeddings are a key component of modern natural language processing systems. They provide a representation of words that has boosted the performance of many applications, working as a semblance of meaning. Word embeddings seem to capture a semblance of the meaning of words from raw text, but, at the same time, they also distill stereotypes and societal biases which are subsequently relayed to the final applications. Such biases can be discriminatory. It is very important to detect and mitigate those biases, to prevent discriminatory behaviors of automated processes, which can be much more harmful than in the case of humans because their of their scale. There are currently many tools and techniques to detect and mitigate biases in word embeddings, but they present many barriers for the engagement of people without technical skills. As it happens, most of the experts in bias, either social scientists or people with deep knowledge of the context where bias is harmful, do not have such skills, and they cannot engage in the processes of bias detection because of the technical barriers. We have studied the barriers in existing tools and have explored their possibilities and limitations with different kinds of users. With this exploration, we propose to develop a tool that is specially aimed to lower the technical barriers and provide the exploration power to address the requirements of experts, scientists and people in general who are willing to audit these technologies.
Comparison of propagation models and forward calculation methods on cellular, tissue and organ scale atrial electrophysiology
Mar 15, 2022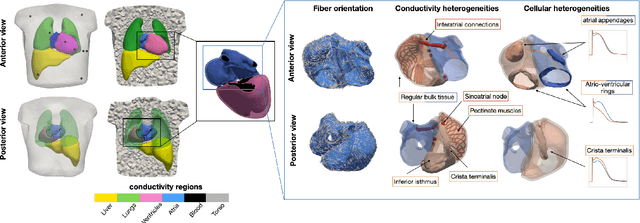
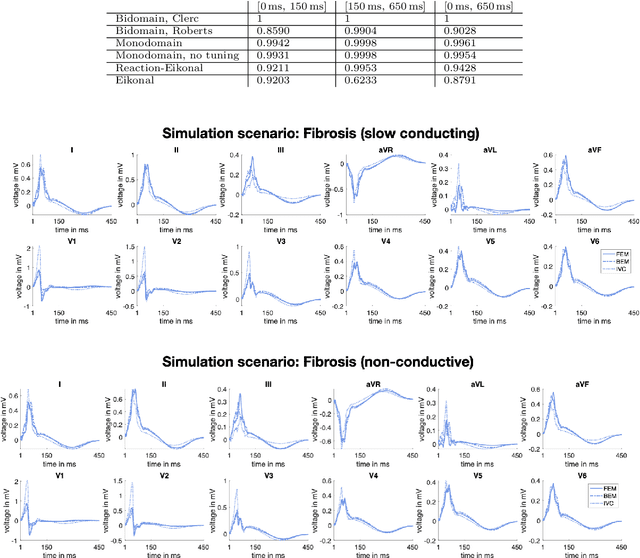

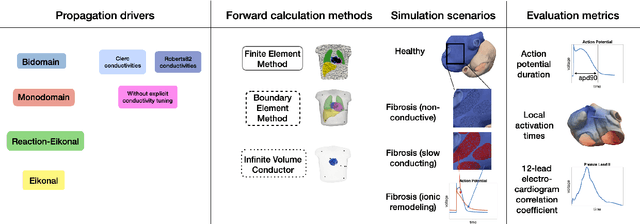
Objective: The bidomain model and the finite element method are an established standard to mathematically describe cardiac electrophysiology, but are both suboptimal choices for fast and large-scale simulations due to high computational costs. We investigate to what extent simplified approaches for propagation models (monodomain, reaction-eikonal and eikonal) and forward calculation (boundary element and infinite volume conductor) deliver markedly accelerated, yet physiologically accurate simulation results in atrial electrophysiology. Methods: We compared action potential durations, local activation times (LATs), and electrocardiograms (ECGs) for sinus rhythm simulations on healthy and fibrotically infiltrated atrial models. Results: All simplified model solutions yielded LATs and P waves in accurate accordance with the bidomain results. Only for the eikonal model with pre-computed action potential templates shifted in time to derive transmembrane voltages, repolarization behavior notably deviated from the bidomain results. ECGs calculated with the boundary element method were characterized by correlation coefficients >0.9 compared to the finite element method. The infinite volume conductor method led to lower correlation coefficients caused predominantly by systematic overestimations of P wave amplitudes in the precordial leads. Conclusion: Our results demonstrate that the eikonal model yields accurate LATs and combined with the boundary element method precise ECGs compared to markedly more expensive full bidomain simulations. However, for an accurate representation of atrial repolarization dynamics, diffusion terms must be accounted for in simplified models. Significance: Simulations of atrial LATs and ECGs can be notably accelerated to clinically feasible time frames at high accuracy by resorting to the eikonal and boundary element methods.
Performance Variability in Zero-Shot Classification
Mar 01, 2021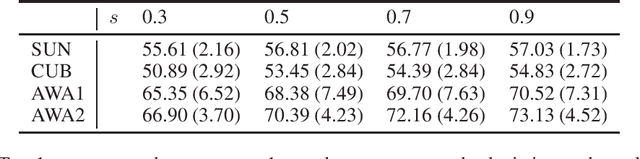
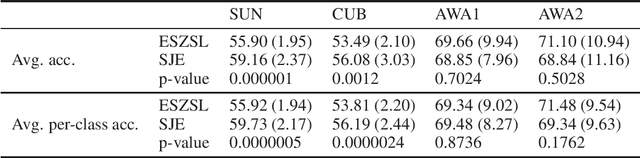
Zero-shot classification (ZSC) is the task of learning predictors for classes not seen during training. Although the different methods in the literature are evaluated using the same class splits, little is known about their stability under different class partitions. In this work we show experimentally that ZSC performance exhibits strong variability under changing training setups. We propose the use ensemble learning as an attempt to mitigate this phenomena.