 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Which Argumentative Aspects of Hate Speech in Social Media can be reliably identified?
Jun 05, 2023With the increasing diversity of use cases of large language models, a more informative treatment of texts seems necessary. An argumentative analysis could foster a more reasoned usage of chatbots, text completion mechanisms or other applications. However, it is unclear which aspects of argumentation can be reliably identified and integrated in language models. In this paper, we present an empirical assessment of the reliability with which different argumentative aspects can be automatically identified in hate speech in social media. We have enriched the Hateval corpus (Basile et al. 2019) with a manual annotation of some argumentative components, adapted from Wagemans (2016)'s Periodic Table of Arguments. We show that some components can be identified with reasonable reliability. For those that present a high error ratio, we analyze the patterns of disagreement between expert annotators and errors in automatic procedures, and we propose adaptations of those categories that can be more reliably reproduced.
Parsimonious Argument Annotations for Hate Speech Counter-narratives
Aug 01, 2022


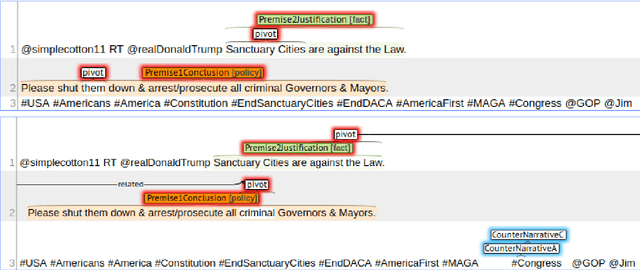
We present an enrichment of the Hateval corpus of hate speech tweets (Basile et. al 2019) aimed to facilitate automated counter-narrative generation. Comparably to previous work (Chung et. al. 2019), manually written counter-narratives are associated to tweets. However, this information alone seems insufficient to obtain satisfactory language models for counter-narrative generation. That is why we have also annotated tweets with argumentative information based on Wagemanns (2016), that we believe can help in building convincing and effective counter-narratives for hate speech against particular groups. We discuss adequacies and difficulties of this annotation process and present several baselines for automatic detection of the annotated elements. Preliminary results show that automatic annotators perform close to human annotators to detect some aspects of argumentation, while others only reach low or moderate level of inter-annotator agreement.
A tool to overcome technical barriers for bias assessment in human language technologies
Jul 14, 2022
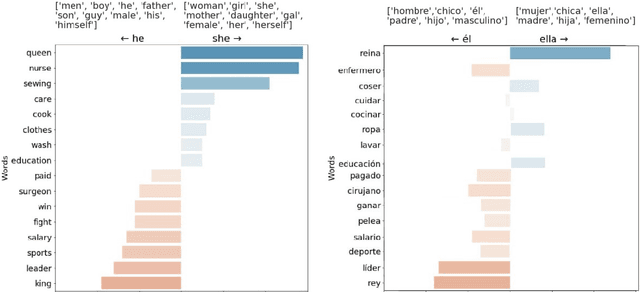

Automatic processing of language is becoming pervasive in our lives, often taking central roles in our decision making, like choosing the wording for our messages and mails, translating our readings, or even having full conversations with us. Word embeddings are a key component of modern natural language processing systems. They provide a representation of words that has boosted the performance of many applications, working as a semblance of meaning. Word embeddings seem to capture a semblance of the meaning of words from raw text, but, at the same time, they also distill stereotypes and societal biases which are subsequently relayed to the final applications. Such biases can be discriminatory. It is very important to detect and mitigate those biases, to prevent discriminatory behaviors of automated processes, which can be much more harmful than in the case of humans because their of their scale. There are currently many tools and techniques to detect and mitigate biases in word embeddings, but they present many barriers for the engagement of people without technical skills. As it happens, most of the experts in bias, either social scientists or people with deep knowledge of the context where bias is harmful, do not have such skills, and they cannot engage in the processes of bias detection because of the technical barriers. We have studied the barriers in existing tools and have explored their possibilities and limitations with different kinds of users. With this exploration, we propose to develop a tool that is specially aimed to lower the technical barriers and provide the exploration power to address the requirements of experts, scientists and people in general who are willing to audit these technologies.
RoBERTuito: a pre-trained language model for social media text in Spanish
Nov 18, 2021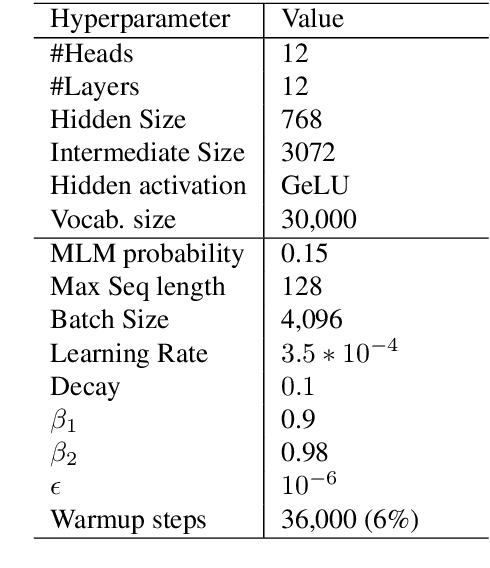
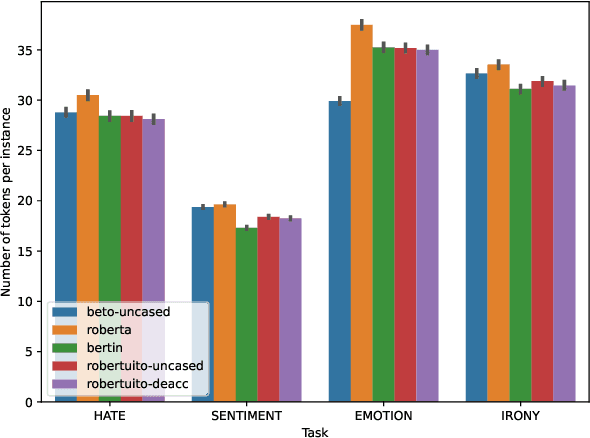


Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for Natural Language Understanding tasks. Recently, some works geared towards pre-training, specially-crafted models for particular domains, such as scientific papers, medical documents, and others. In this work, we present RoBERTuito, a pre-trained language model for user-generated content in Spanish. We trained RoBERTuito on 500 million tweets in Spanish. Experiments on a benchmark of 4 tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models for Spanish. In order to help further research, we make RoBERTuito publicly available at the HuggingFace model hub.