 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Natural Language Agentic Approach to Study Affective Polarization
Mar 03, 2026Affective polarization has been central to political and social studies, with growing focus on social media, where partisan divisions are often exacerbated. Real-world studies tend to have limited scope, while simulated studies suffer from insufficient high-quality training data, as manually labeling posts is labor-intensive and prone to subjective biases. The lack of adequate tools to formalize different definitions of affective polarization across studies complicates result comparison and hinders interoperable frameworks. We present a multi-agent model providing a comprehensive approach to studying affective polarization in social media. To operationalize our framework, we develop a platform leveraging large language models (LLMs) to construct virtual communities where agents engage in discussions. We showcase the potential of our platform by (1) analyzing questions related to affective polarization, as explored in social science literature, providing a fresh perspective on this phenomenon, and (2) introducing scenarios that allow observation and measurement of polarization at different levels of granularity and abstraction. Experiments show that our platform is a flexible tool for computational studies of complex social dynamics such as affective polarization. It leverages advanced agent models to simulate rich, context-sensitive interactions and systematically explore research questions traditionally addressed through human-subject studies.
* Accepted at ICAART 2026 (18th International Conference on Agents and Artificial Intelligence). The final published version is available in the conference proceedings (SCITEPRESS)
How Do People Revise Inconsistent Beliefs? Examining Belief Revision in Humans with User Studies
Jun 11, 2025Understanding how humans revise their beliefs in light of new information is crucial for developing AI systems which can effectively model, and thus align with, human reasoning. While theoretical belief revision frameworks rely on a set of principles that establish how these operations are performed, empirical evidence from cognitive psychology suggests that people may follow different patterns when presented with conflicting information. In this paper, we present three comprehensive user studies showing that people consistently prefer explanation-based revisions, i.e., those which are guided by explanations, that result in changes to their belief systems that are not necessarily captured by classical belief change theory. Our experiments systematically investigate how people revise their beliefs with explanations for inconsistencies, whether they are provided with them or left to formulate them themselves, demonstrating a robust preference for what may seem non-minimal revisions across different types of scenarios. These findings have implications for AI systems designed to model human reasoning or interact with humans, suggesting that such systems should accommodate explanation-based, potentially non-minimal belief revision operators to better align with human cognitive processes.
Do Large Language Models Show Biases in Causal Learning?
Dec 13, 2024



Causal learning is the cognitive process of developing the capability of making causal inferences based on available information, often guided by normative principles. This process is prone to errors and biases, such as the illusion of causality, in which people perceive a causal relationship between two variables despite lacking supporting evidence. This cognitive bias has been proposed to underlie many societal problems, including social prejudice, stereotype formation, misinformation, and superstitious thinking. In this research, we investigate whether large language models (LLMs) develop causal illusions, both in real-world and controlled laboratory contexts of causal learning and inference. To this end, we built a dataset of over 2K samples including purely correlational cases, situations with null contingency, and cases where temporal information excludes the possibility of causality by placing the potential effect before the cause. We then prompted the models to make statements or answer causal questions to evaluate their tendencies to infer causation erroneously in these structured settings. Our findings show a strong presence of causal illusion bias in LLMs. Specifically, in open-ended generation tasks involving spurious correlations, the models displayed bias at levels comparable to, or even lower than, those observed in similar studies on human subjects. However, when faced with null-contingency scenarios or temporal cues that negate causal relationships, where it was required to respond on a 0-100 scale, the models exhibited significantly higher bias. These findings suggest that the models have not uniformly, consistently, or reliably internalized the normative principles essential for accurate causal learning.
Advancing Interactive Explainable AI via Belief Change Theory
Aug 14, 2024As AI models become ever more complex and intertwined in humans' daily lives, greater levels of interactivity of explainable AI (XAI) methods are needed. In this paper, we propose the use of belief change theory as a formal foundation for operators that model the incorporation of new information, i.e. user feedback in interactive XAI, to logical representations of data-driven classifiers. We argue that this type of formalisation provides a framework and a methodology to develop interactive explanations in a principled manner, providing warranted behaviour and favouring transparency and accountability of such interactions. Concretely, we first define a novel, logic-based formalism to represent explanatory information shared between humans and machines. We then consider real world scenarios for interactive XAI, with different prioritisations of new and existing knowledge, where our formalism may be instantiated. Finally, we analyse a core set of belief change postulates, discussing their suitability for our real world settings and pointing to particular challenges that may require the relaxation or reinterpretation of some of the theoretical assumptions underlying existing operators.
Computational Complexity of Preferred Subset Repairs on Data-Graphs
Feb 14, 2024The problem of repairing inconsistent knowledge bases has a long history within the communities of database theory and knowledge representation and reasoning, especially from the perspective of structured data. However, as the data available in real-world domains becomes more complex and interconnected, the need naturally arises for developing new types of repositories, representation languages, and semantics, to allow for more suitable ways to query and reason about it. Graph databases provide an effective way to represent relationships among semi-structured data, and allow processing and querying these connections efficiently. In this work, we focus on the problem of computing prioritized repairs over graph databases with data values, using a notion of consistency based on Reg-GXPath expressions as integrity constraints. We present several preference criteria based on the standard subset repair semantics, incorporating weights, multisets, and set-based priority levels. We study the most common repairing tasks, showing that it is possible to maintain the same computational complexity as in the case where no preference criterion is available for exploitation. To complete the picture, we explore the complexity of consistent query answering in this setting and obtain tight lower and upper bounds for all the preference criteria introduced.
The Distributional Uncertainty of the SHAP score in Explainable Machine Learning
Jan 23, 2024



Attribution scores reflect how important the feature values in an input entity are for the output of a machine learning model. One of the most popular attribution scores is the SHAP score, which is an instantiation of the general Shapley value used in coalition game theory. The definition of this score relies on a probability distribution on the entity population. Since the exact distribution is generally unknown, it needs to be assigned subjectively or be estimated from data, which may lead to misleading feature scores. In this paper, we propose a principled framework for reasoning on SHAP scores under unknown entity population distributions. In our framework, we consider an uncertainty region that contains the potential distributions, and the SHAP score of a feature becomes a function defined over this region. We study the basic problems of finding maxima and minima of this function, which allows us to determine tight ranges for the SHAP scores of all features. In particular, we pinpoint the complexity of these problems, and other related ones, showing them to be NP-complete. Finally, we present experiments on a real-world dataset, showing that our framework may contribute to a more robust feature scoring.
Parsimonious Argument Annotations for Hate Speech Counter-narratives
Aug 01, 2022


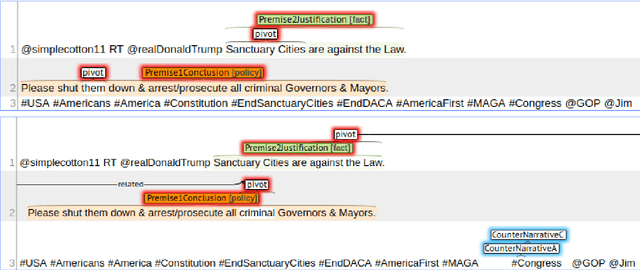
We present an enrichment of the Hateval corpus of hate speech tweets (Basile et. al 2019) aimed to facilitate automated counter-narrative generation. Comparably to previous work (Chung et. al. 2019), manually written counter-narratives are associated to tweets. However, this information alone seems insufficient to obtain satisfactory language models for counter-narrative generation. That is why we have also annotated tweets with argumentative information based on Wagemanns (2016), that we believe can help in building convincing and effective counter-narratives for hate speech against particular groups. We discuss adequacies and difficulties of this annotation process and present several baselines for automatic detection of the annotated elements. Preliminary results show that automatic annotators perform close to human annotators to detect some aspects of argumentation, while others only reach low or moderate level of inter-annotator agreement.
Scalable Query Answering under Uncertainty to Neuroscientific Ontological Knowledge: The NeuroLang Approach
Feb 23, 2022
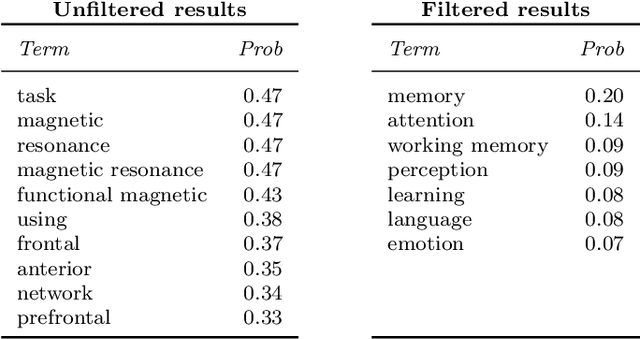
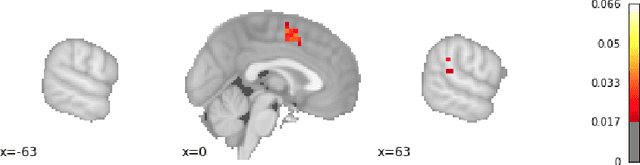
Researchers in neuroscience have a growing number of datasets available to study the brain, which is made possible by recent technological advances. Given the extent to which the brain has been studied, there is also available ontological knowledge encoding the current state of the art regarding its different areas, activation patterns, key words associated with studies, etc. Furthermore, there is an inherent uncertainty associated with brain scans arising from the mapping between voxels -- 3D pixels -- and actual points in different individual brains. Unfortunately, there is currently no unifying framework for accessing such collections of rich heterogeneous data under uncertainty, making it necessary for researchers to rely on ad hoc tools. In particular, one major weakness of current tools that attempt to address this kind of task is that only very limited propositional query languages have been developed. In this paper, we present NeuroLang, an ontology language with existential rules, probabilistic uncertainty, and built-in mechanisms to guarantee tractable query answering over very large datasets. After presenting the language and its general query answering architecture, we discuss real-world use cases showing how NeuroLang can be applied to practical scenarios for which current tools are inadequate.
On the Importance of Domain-specific Explanations in AI-based Cybersecurity Systems (Technical Report)
Aug 02, 2021
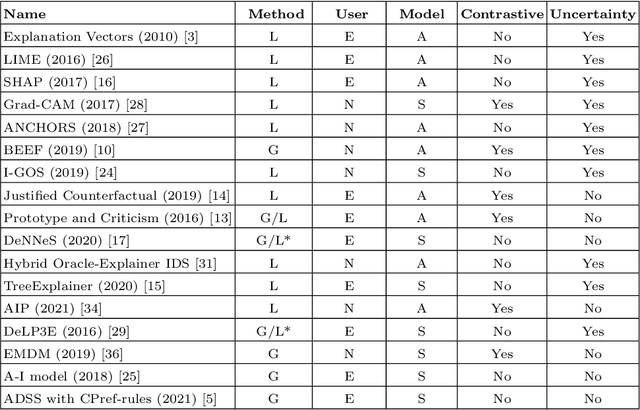
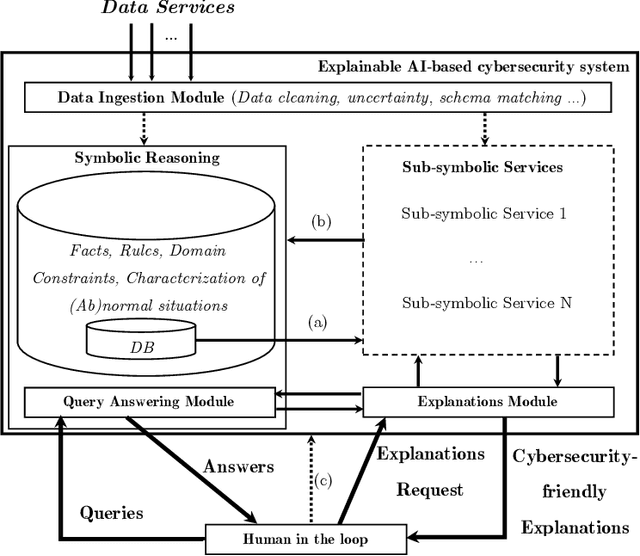
With the availability of large datasets and ever-increasing computing power, there has been a growing use of data-driven artificial intelligence systems, which have shown their potential for successful application in diverse areas. However, many of these systems are not able to provide information about the rationale behind their decisions to their users. Lack of understanding of such decisions can be a major drawback, especially in critical domains such as those related to cybersecurity. In light of this problem, in this paper we make three contributions: (i) proposal and discussion of desiderata for the explanation of outputs generated by AI-based cybersecurity systems; (ii) a comparative analysis of approaches in the literature on Explainable Artificial Intelligence (XAI) under the lens of both our desiderata and further dimensions that are typically used for examining XAI approaches; and (iii) a general architecture that can serve as a roadmap for guiding research efforts towards the development of explainable AI-based cybersecurity systems -- at its core, this roadmap proposes combinations of several research lines in a novel way towards tackling the unique challenges that arise in this context.
Top-k Query Answering in Datalog+/- Ontologies under Subjective Reports
Nov 29, 2013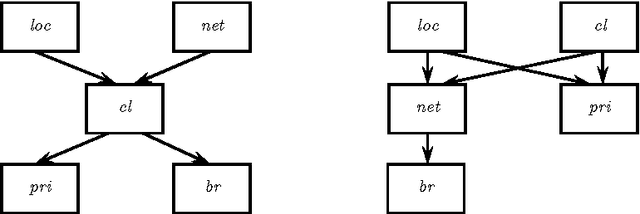

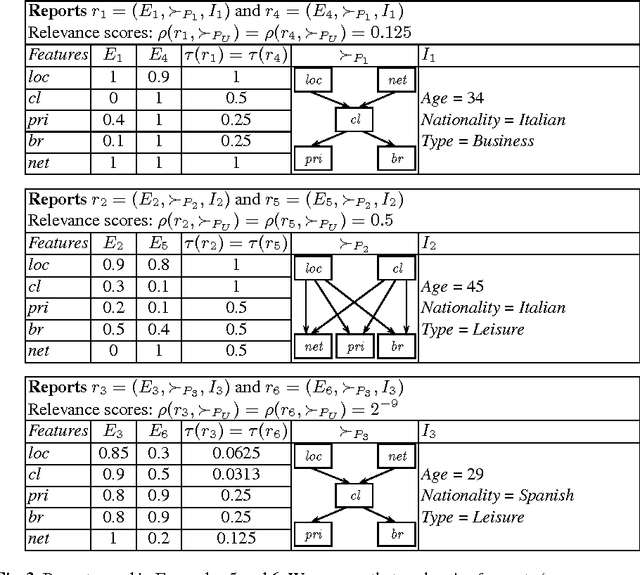

The use of preferences in query answering, both in traditional databases and in ontology-based data access, has recently received much attention, due to its many real-world applications. In this paper, we tackle the problem of top-k query answering in Datalog+/- ontologies subject to the querying user's preferences and a collection of (subjective) reports of other users. Here, each report consists of scores for a list of features, its author's preferences among the features, as well as other information. Theses pieces of information of every report are then combined, along with the querying user's preferences and his/her trust into each report, to rank the query results. We present two alternative such rankings, along with algorithms for top-k (atomic) query answering under these rankings. We also show that, under suitable assumptions, these algorithms run in polynomial time in the data complexity. We finally present more general reports, which are associated with sets of atoms rather than single atoms.