 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Agents Contain World Models, even under Partial Observability and Stochasticity
Feb 03, 2026Deciding whether an agent possesses a model of its surrounding world is a fundamental step toward understanding its capabilities and limitations. In [10], it was shown that, within a particular framework, every almost optimal and general agent necessarily contains sufficient knowledge of its environment to allow an approximate reconstruction of it by querying the agent as a black box. This result relied on the assumptions that the agent is deterministic and that the environment is fully observable. In this work, we remove both assumptions by extending the theorem to stochastic agents operating in partially observable environments. Fundamentally, this shows that stochastic agents cannot avoid learning their environment through the usage of randomization. We also strengthen the result by weakening the notion of generality, proving that less powerful agents already contain a model of the world in which they operate.
Feature Relevancy, Necessity and Usefulness: Complexity and Algorithms
May 06, 2025Given a classification model and a prediction for some input, there are heuristic strategies for ranking features according to their importance in regard to the prediction. One common approach to this task is rooted in propositional logic and the notion of \textit{sufficient reason}. Through this concept, the categories of relevant and necessary features were proposed in order to identify the crucial aspects of the input. This paper improves the existing techniques and algorithms for deciding which are the relevant and/or necessary features, showing in particular that necessity can be detected efficiently in complex models such as neural networks. We also generalize the notion of relevancy and study associated problems. Moreover, we present a new global notion (i.e. that intends to explain whether a feature is important for the behavior of the model in general, not depending on a particular input) of \textit{usefulness} and prove that it is related to relevancy and necessity. Furthermore, we develop efficient algorithms for detecting it in decision trees and other more complex models, and experiment on three datasets to analyze its practical utility.
Computational Complexity of Preferred Subset Repairs on Data-Graphs
Feb 14, 2024The problem of repairing inconsistent knowledge bases has a long history within the communities of database theory and knowledge representation and reasoning, especially from the perspective of structured data. However, as the data available in real-world domains becomes more complex and interconnected, the need naturally arises for developing new types of repositories, representation languages, and semantics, to allow for more suitable ways to query and reason about it. Graph databases provide an effective way to represent relationships among semi-structured data, and allow processing and querying these connections efficiently. In this work, we focus on the problem of computing prioritized repairs over graph databases with data values, using a notion of consistency based on Reg-GXPath expressions as integrity constraints. We present several preference criteria based on the standard subset repair semantics, incorporating weights, multisets, and set-based priority levels. We study the most common repairing tasks, showing that it is possible to maintain the same computational complexity as in the case where no preference criterion is available for exploitation. To complete the picture, we explore the complexity of consistent query answering in this setting and obtain tight lower and upper bounds for all the preference criteria introduced.
The Distributional Uncertainty of the SHAP score in Explainable Machine Learning
Jan 23, 2024



Attribution scores reflect how important the feature values in an input entity are for the output of a machine learning model. One of the most popular attribution scores is the SHAP score, which is an instantiation of the general Shapley value used in coalition game theory. The definition of this score relies on a probability distribution on the entity population. Since the exact distribution is generally unknown, it needs to be assigned subjectively or be estimated from data, which may lead to misleading feature scores. In this paper, we propose a principled framework for reasoning on SHAP scores under unknown entity population distributions. In our framework, we consider an uncertainty region that contains the potential distributions, and the SHAP score of a feature becomes a function defined over this region. We study the basic problems of finding maxima and minima of this function, which allows us to determine tight ranges for the SHAP scores of all features. In particular, we pinpoint the complexity of these problems, and other related ones, showing them to be NP-complete. Finally, we present experiments on a real-world dataset, showing that our framework may contribute to a more robust feature scoring.
On the complexity of finding set repairs for data-graphs
Jun 15, 2022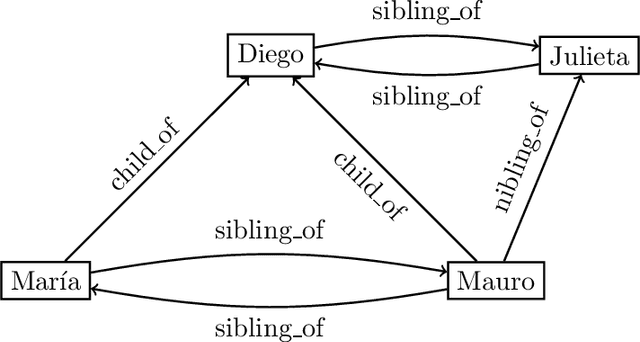
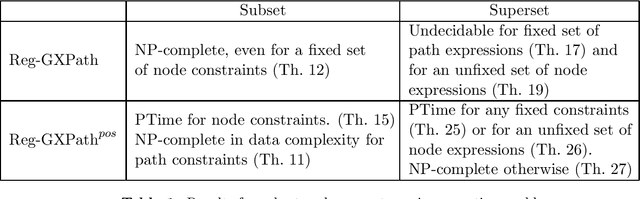
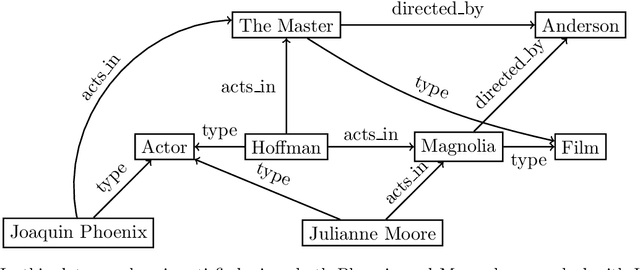
In the deeply interconnected world we live in, pieces of information link domains all around us. As graph databases embrace effectively relationships among data and allow processing and querying these connections efficiently, they are rapidly becoming a popular platform for storage that supports a wide range of domains and applications. As in the relational case, it is expected that data preserves a set of integrity constraints that define the semantic structure of the world it represents. When a database does not satisfy its integrity constraints, a possible approach is to search for a 'similar' database that does satisfy the constraints, also known as a repair. In this work, we study the problem of computing subset and superset repairs for graph databases with data values using a notion of consistency based on a set of Reg-GXPath expressions as integrity constraints. We show that for positive fragments of Reg-GXPath these problems admit a polynomial-time algorithm, while the full expressive power of the language renders them intractable.
An epistemic approach to model uncertainty in data-graphs
Sep 29, 2021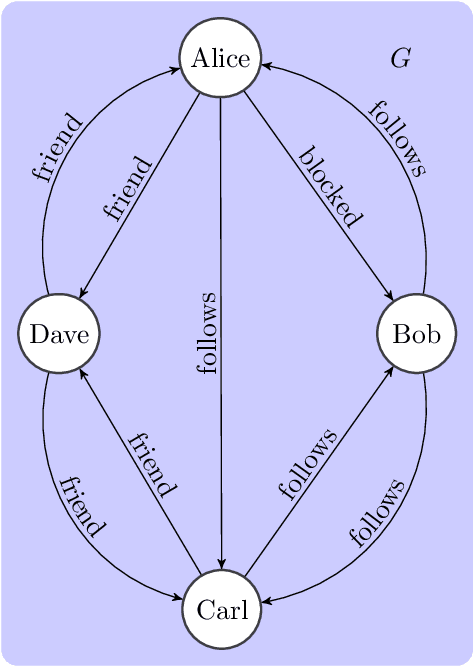
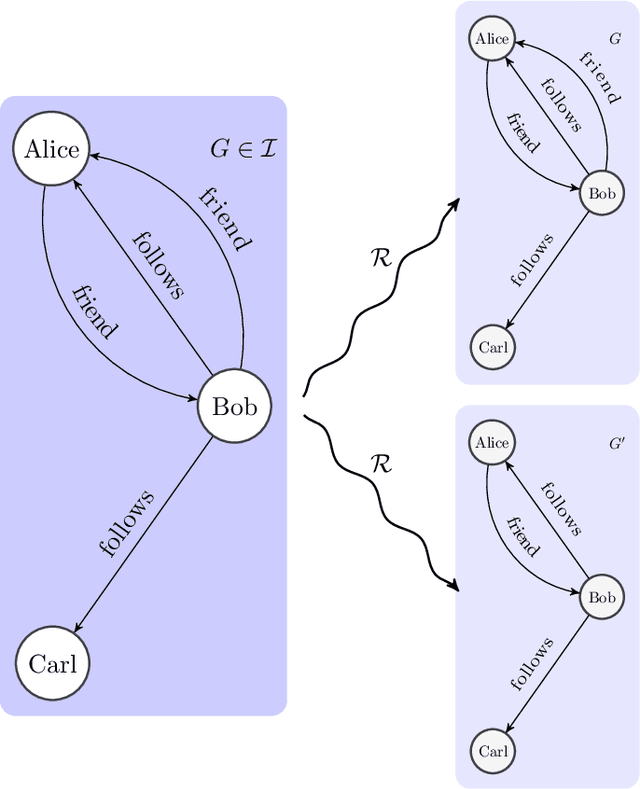
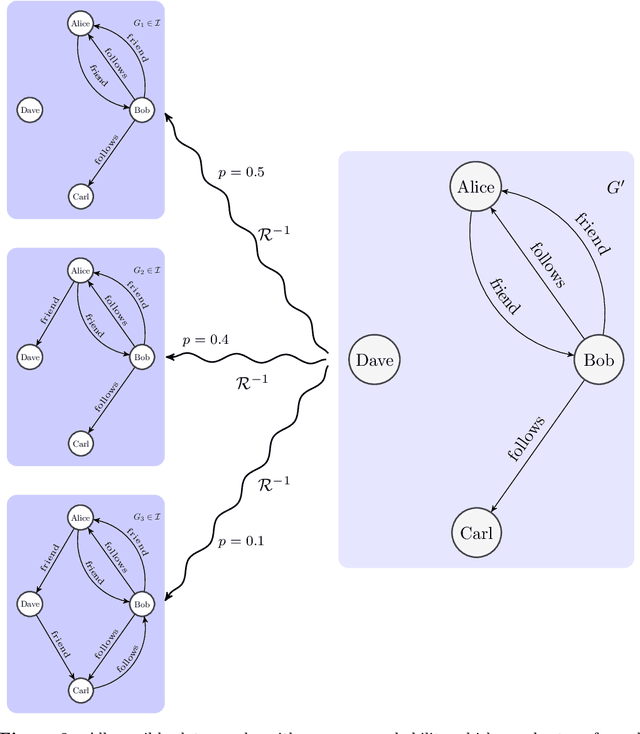
Graph databases are becoming widely successful as data models that allow to effectively represent and process complex relationships among various types of data. As with any other type of data repository, graph databases may suffer from errors and discrepancies with respect to the real-world data they intend to represent. In this work we explore the notion of probabilistic unclean graph databases, previously proposed for relational databases, in order to capture the idea that the observed (unclean) graph database is actually the noisy version of a clean one that correctly models the world but that we know partially. As the factors that may be involved in the observation can be many, e.g, all different types of clerical errors or unintended transformations of the data, we assume a probabilistic model that describes the distribution over all possible ways in which the clean (uncertain) database could have been polluted. Based on this model we define two computational problems: data cleaning and probabilistic query answering and study for both of them their corresponding complexity when considering that the transformation of the database can be caused by either removing (subset) or adding (superset) nodes and edges.