 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the complexity of finding set repairs for data-graphs
Jun 15, 2022
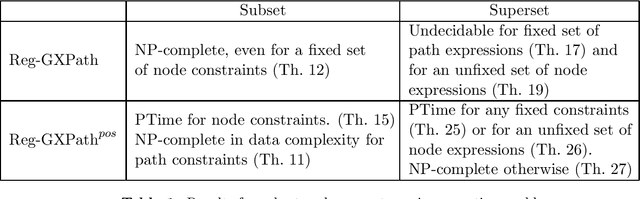
In the deeply interconnected world we live in, pieces of information link domains all around us. As graph databases embrace effectively relationships among data and allow processing and querying these connections efficiently, they are rapidly becoming a popular platform for storage that supports a wide range of domains and applications. As in the relational case, it is expected that data preserves a set of integrity constraints that define the semantic structure of the world it represents. When a database does not satisfy its integrity constraints, a possible approach is to search for a 'similar' database that does satisfy the constraints, also known as a repair. In this work, we study the problem of computing subset and superset repairs for graph databases with data values using a notion of consistency based on a set of Reg-GXPath expressions as integrity constraints. We show that for positive fragments of Reg-GXPath these problems admit a polynomial-time algorithm, while the full expressive power of the language renders them intractable.
An epistemic approach to model uncertainty in data-graphs
Sep 29, 2021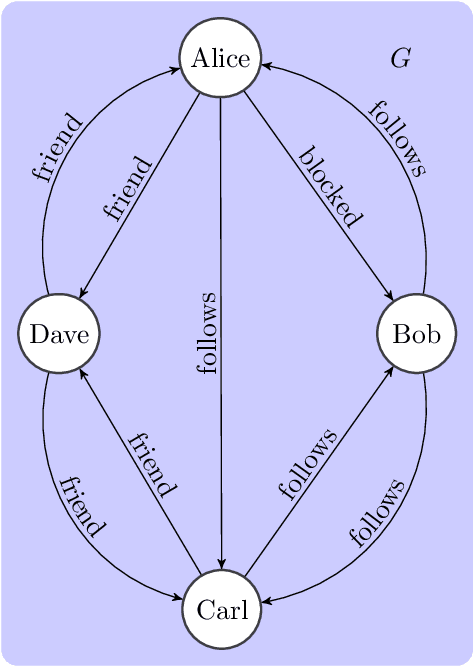
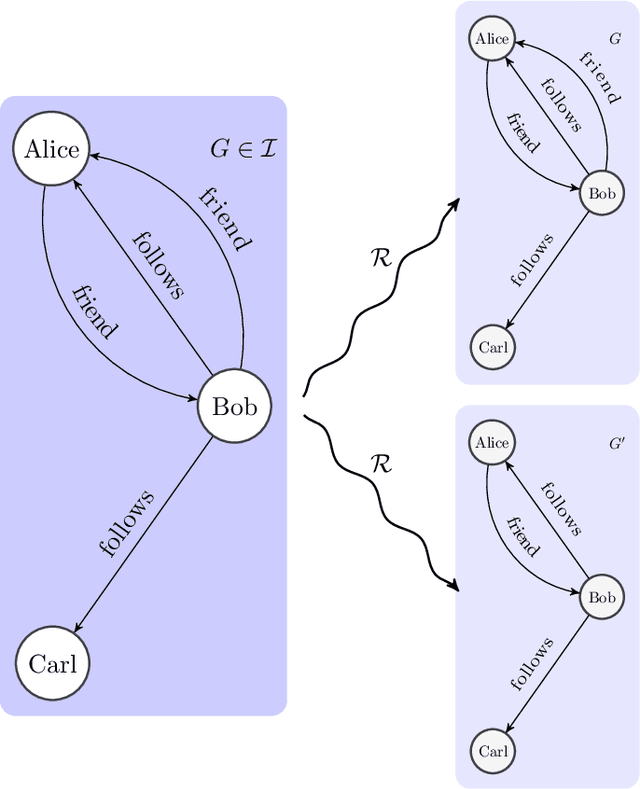
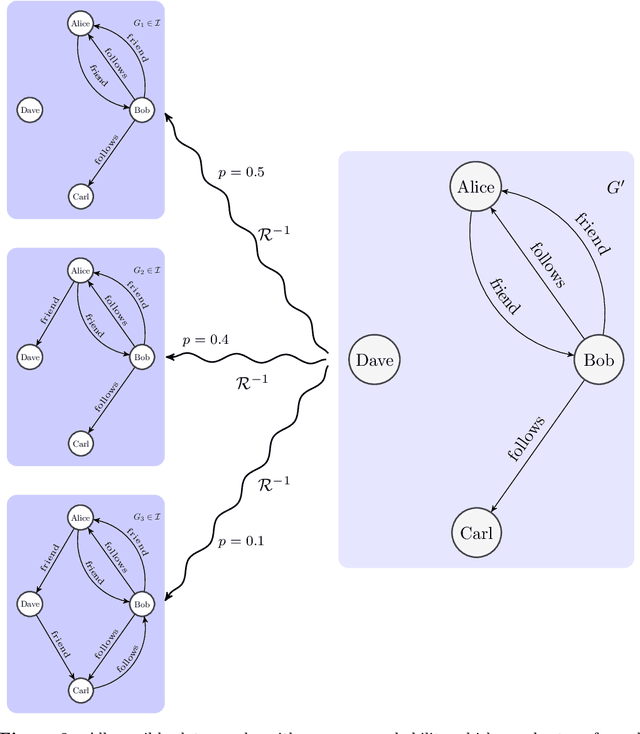
Graph databases are becoming widely successful as data models that allow to effectively represent and process complex relationships among various types of data. As with any other type of data repository, graph databases may suffer from errors and discrepancies with respect to the real-world data they intend to represent. In this work we explore the notion of probabilistic unclean graph databases, previously proposed for relational databases, in order to capture the idea that the observed (unclean) graph database is actually the noisy version of a clean one that correctly models the world but that we know partially. As the factors that may be involved in the observation can be many, e.g, all different types of clerical errors or unintended transformations of the data, we assume a probabilistic model that describes the distribution over all possible ways in which the clean (uncertain) database could have been polluted. Based on this model we define two computational problems: data cleaning and probabilistic query answering and study for both of them their corresponding complexity when considering that the transformation of the database can be caused by either removing (subset) or adding (superset) nodes and edges.