 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-k Query Answering in Datalog+/- Ontologies under Subjective Reports
Paper and Code
Nov 29, 2013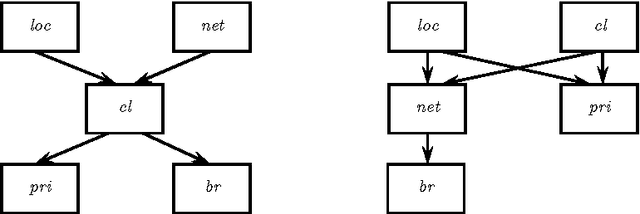

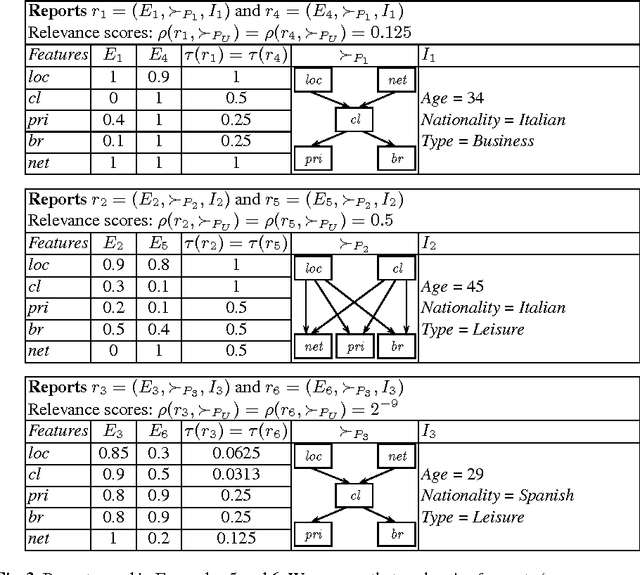

The use of preferences in query answering, both in traditional databases and in ontology-based data access, has recently received much attention, due to its many real-world applications. In this paper, we tackle the problem of top-k query answering in Datalog+/- ontologies subject to the querying user's preferences and a collection of (subjective) reports of other users. Here, each report consists of scores for a list of features, its author's preferences among the features, as well as other information. Theses pieces of information of every report are then combined, along with the querying user's preferences and his/her trust into each report, to rank the query results. We present two alternative such rankings, along with algorithms for top-k (atomic) query answering under these rankings. We also show that, under suitable assumptions, these algorithms run in polynomial time in the data complexity. We finally present more general reports, which are associated with sets of atoms rather than single atoms.