 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Query Answering under Uncertainty to Neuroscientific Ontological Knowledge: The NeuroLang Approach
Feb 23, 2022
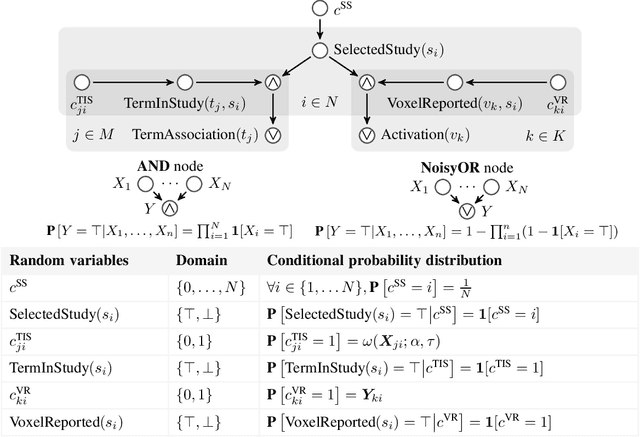
Researchers in neuroscience have a growing number of datasets available to study the brain, which is made possible by recent technological advances. Given the extent to which the brain has been studied, there is also available ontological knowledge encoding the current state of the art regarding its different areas, activation patterns, key words associated with studies, etc. Furthermore, there is an inherent uncertainty associated with brain scans arising from the mapping between voxels -- 3D pixels -- and actual points in different individual brains. Unfortunately, there is currently no unifying framework for accessing such collections of rich heterogeneous data under uncertainty, making it necessary for researchers to rely on ad hoc tools. In particular, one major weakness of current tools that attempt to address this kind of task is that only very limited propositional query languages have been developed. In this paper, we present NeuroLang, an ontology language with existential rules, probabilistic uncertainty, and built-in mechanisms to guarantee tractable query answering over very large datasets. After presenting the language and its general query answering architecture, we discuss real-world use cases showing how NeuroLang can be applied to practical scenarios for which current tools are inadequate.
Complex Coordinate-Based Meta-Analysis with Probabilistic Programming
Dec 02, 2020
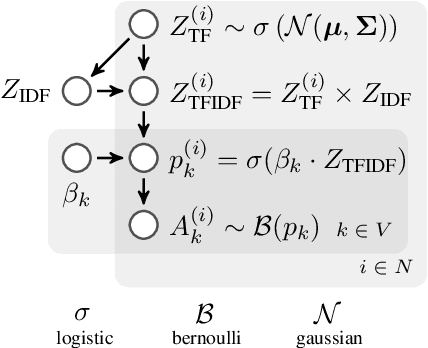

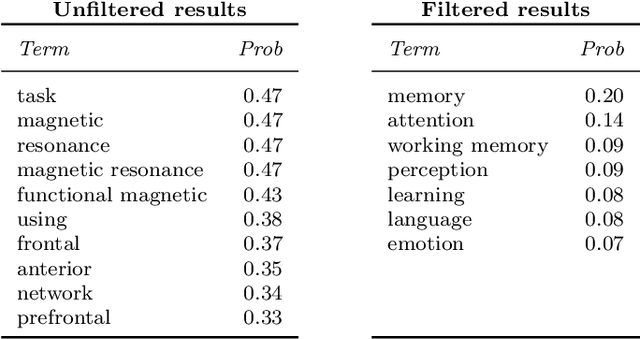
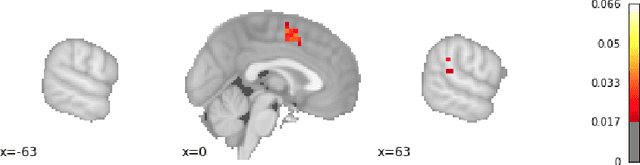
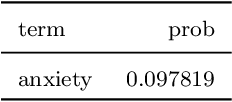
With the growing number of published functional magnetic resonance imaging (fMRI) studies, meta-analysis databases and models have become an integral part of brain mapping research. Coordinate-based meta-analysis (CBMA) databases are built by automatically extracting both coordinates of reported peak activations and term associations using natural language processing (NLP) techniques. Solving term-based queries on these databases make it possible to obtain statistical maps of the brain related to specific cognitive processes. However, with tools like Neurosynth, only singleterm queries lead to statistically reliable results. When solving richer queries, too few studies from the database contribute to the statistical estimations. We design a probabilistic domain-specific language (DSL) standing on Datalog and one of its probabilistic extensions, CP-Logic, for expressing and solving rich logic-based queries. We encode a CBMA database into a probabilistic program. Using the joint distribution of its Bayesian network translation, we show that solutions of queries on this program compute the right probability distributions of voxel activations. We explain how recent lifted query processing algorithms make it possible to scale to the size of large neuroimaging data, where state of the art knowledge compilation (KC) techniques fail to solve queries fast enough for practical applications. Finally, we introduce a method for relating studies to terms probabilistically, leading to better solutions for conjunctive queries on smaller databases. We demonstrate results for two-term conjunctive queries, both on simulated meta-analysis databases and on the widely-used Neurosynth database.