 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Coordinate-Based Meta-Analysis with Probabilistic Programming
Paper and Code

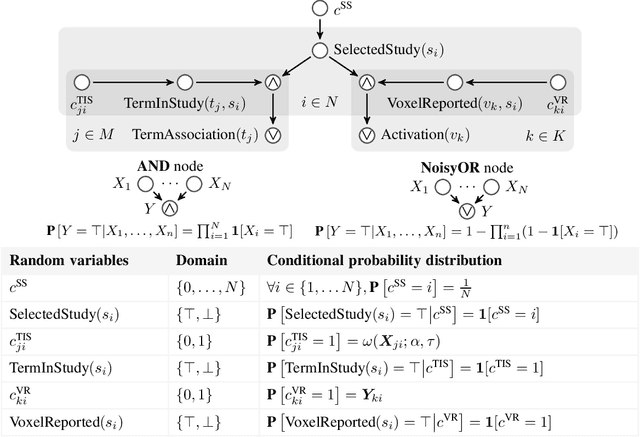
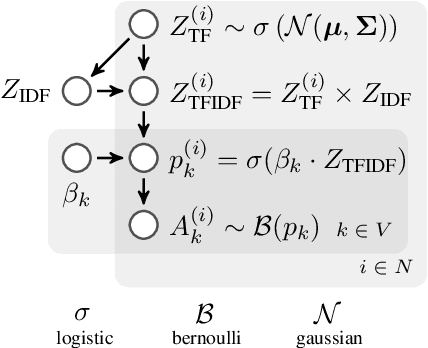

With the growing number of published functional magnetic resonance imaging (fMRI) studies, meta-analysis databases and models have become an integral part of brain mapping research. Coordinate-based meta-analysis (CBMA) databases are built by automatically extracting both coordinates of reported peak activations and term associations using natural language processing (NLP) techniques. Solving term-based queries on these databases make it possible to obtain statistical maps of the brain related to specific cognitive processes. However, with tools like Neurosynth, only singleterm queries lead to statistically reliable results. When solving richer queries, too few studies from the database contribute to the statistical estimations. We design a probabilistic domain-specific language (DSL) standing on Datalog and one of its probabilistic extensions, CP-Logic, for expressing and solving rich logic-based queries. We encode a CBMA database into a probabilistic program. Using the joint distribution of its Bayesian network translation, we show that solutions of queries on this program compute the right probability distributions of voxel activations. We explain how recent lifted query processing algorithms make it possible to scale to the size of large neuroimaging data, where state of the art knowledge compilation (KC) techniques fail to solve queries fast enough for practical applications. Finally, we introduce a method for relating studies to terms probabilistically, leading to better solutions for conjunctive queries on smaller databases. We demonstrate results for two-term conjunctive queries, both on simulated meta-analysis databases and on the widely-used Neurosynth database.