 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the impact of contextual information in hate speech detection
Oct 05, 2022
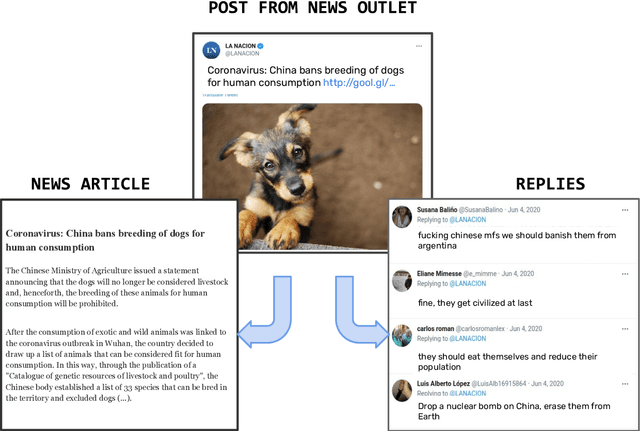
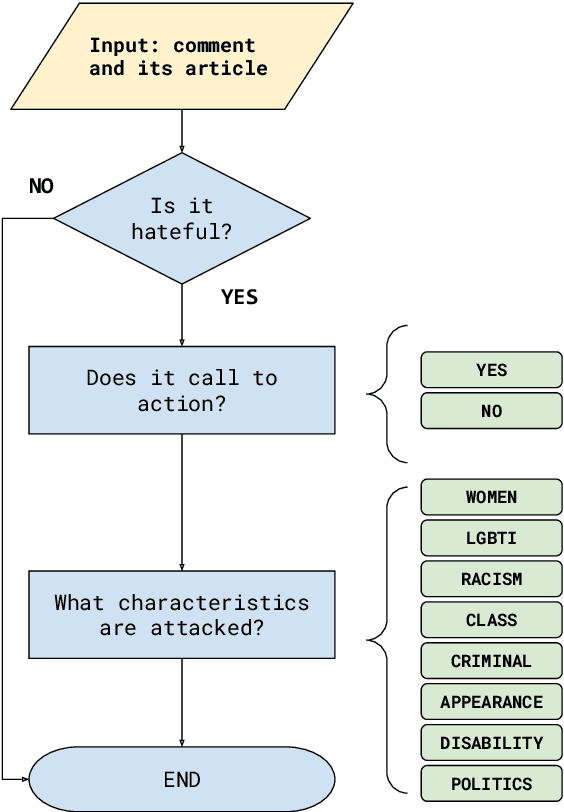
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.
RoBERTuito: a pre-trained language model for social media text in Spanish
Nov 18, 2021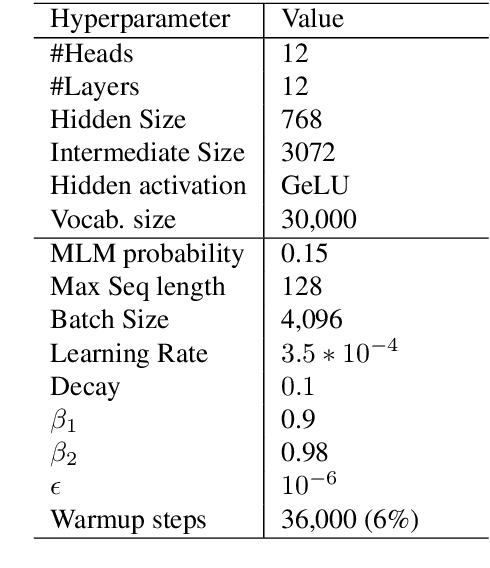
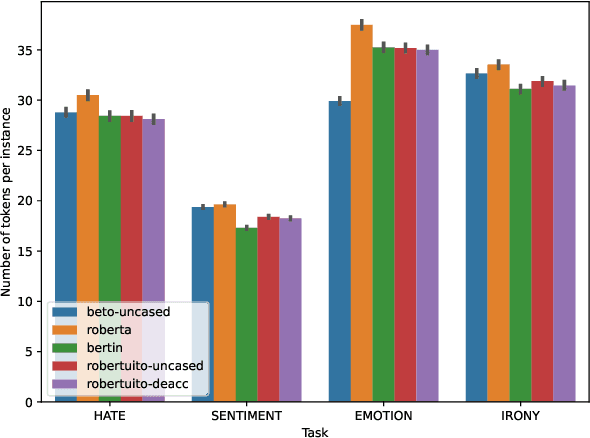


Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for Natural Language Understanding tasks. Recently, some works geared towards pre-training, specially-crafted models for particular domains, such as scientific papers, medical documents, and others. In this work, we present RoBERTuito, a pre-trained language model for user-generated content in Spanish. We trained RoBERTuito on 500 million tweets in Spanish. Experiments on a benchmark of 4 tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models for Spanish. In order to help further research, we make RoBERTuito publicly available at the HuggingFace model hub.
pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks
Jun 17, 2021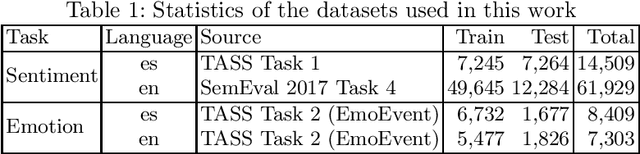
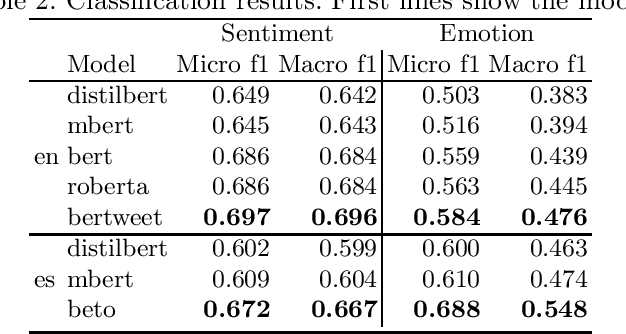
Extracting opinions from texts has gathered a lot of interest in the last years, as we are experiencing an unprecedented volume of user-generated content in social networks and other places. A problem that social researchers find in using opinion mining tools is that they are usually behind commercial APIs and unavailable for other languages than English. To address these issues, we present pysentimiento, a multilingual Python toolkit for Sentiment Analysis and other Social NLP tasks. This open-source library brings state-of-the-art models for Spanish and English in a black-box fashion, allowing researchers to easily access these techniques.
ANDES at SemEval-2020 Task 12: A jointly-trained BERT multilingual model for offensive language detection
Aug 13, 2020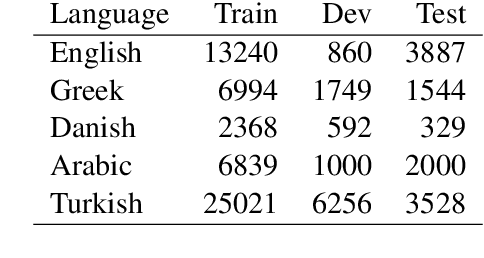
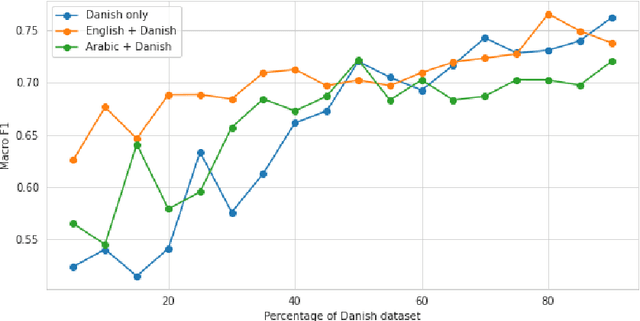
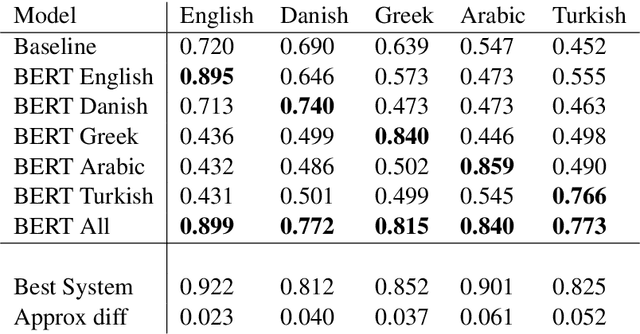
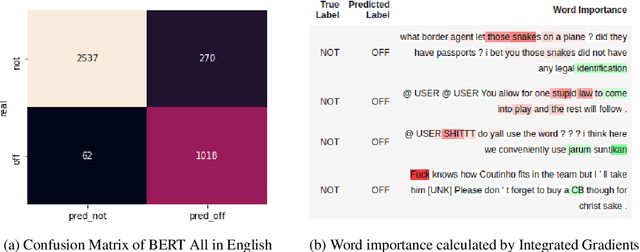
This paper describes our participation in SemEval-2020 Task 12: Multilingual Offensive Language Detection. We jointly-trained a single model by fine-tuning Multilingual BERT to tackle the task across all the proposed languages: English, Danish, Turkish, Greek and Arabic. Our single model had competitive results, with a performance close to top-performing systems in spite of sharing the same parameters across all languages. Zero-shot and few-shot experiments were also conducted to analyze the transference performance among these languages. We make our code public for further research