 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Large Language Models for Hate Speech Detection in Rioplatense Spanish
Oct 16, 2024Hate speech detection deals with many language variants, slang, slurs, expression modalities, and cultural nuances. This outlines the importance of working with specific corpora, when addressing hate speech within the scope of Natural Language Processing, recently revolutionized by the irruption of Large Language Models. This work presents a brief analysis of the performance of large language models in the detection of Hate Speech for Rioplatense Spanish. We performed classification experiments leveraging chain-of-thought reasoning with ChatGPT 3.5, Mixtral, and Aya, comparing their results with those of a state-of-the-art BERT classifier. These experiments outline that, even if large language models show a lower precision compared to the fine-tuned BERT classifier and, in some cases, they find hard-to-get slurs or colloquialisms, they still are sensitive to highly nuanced cases (particularly, homophobic/transphobic hate speech). We make our code and models publicly available for future research.
Assessing the impact of contextual information in hate speech detection
Oct 05, 2022
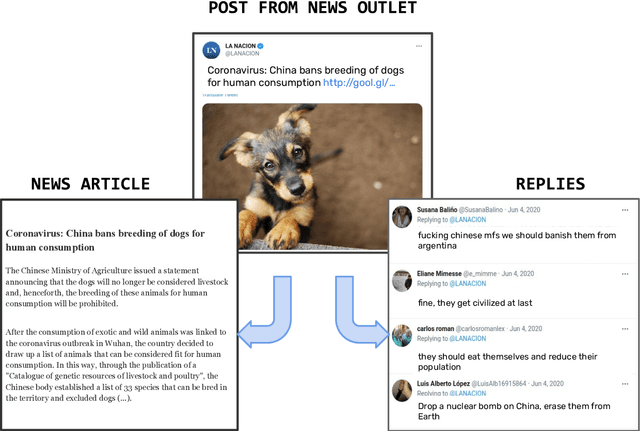
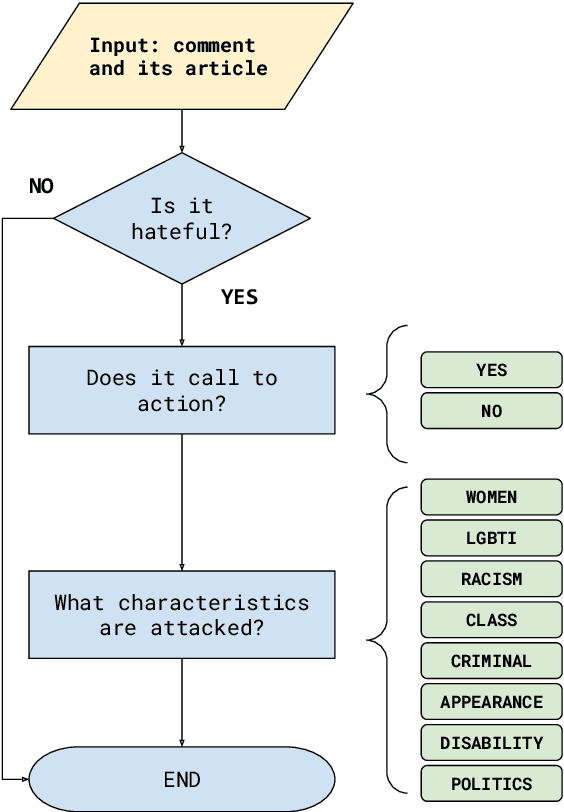
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.