 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Accuracy for Private Continual Cardinality Estimation in Fully Dynamic Streams via Matrix Factorization
Jan 05, 2026We study differentially-private statistics in the fully dynamic continual observation model, where many updates can arrive at each time step and updates to a stream can involve both insertions and deletions of an item. Earlier work (e.g., Jain et al., NeurIPS 2023 for counting distinct elements; Raskhodnikova & Steiner, PODS 2025 for triangle counting with edge updates) reduced the respective cardinality estimation problem to continual counting on the difference stream associated with the true function values on the input stream. In such reductions, a change in the original stream can cause many changes in the difference stream, this poses a challenge for applying private continual counting algorithms to obtain optimal error bounds. We improve the accuracy of several such reductions by studying the associated $\ell_p$-sensitivity vectors of the resulting difference streams and isolating their properties. We demonstrate that our framework gives improved bounds for counting distinct elements, estimating degree histograms, and estimating triangle counts (under a slightly relaxed privacy model), thus offering a general approach to private continual cardinality estimation in streaming settings. Our improved accuracy stems from tight analysis of known factorization mechanisms for the counting matrix in this setting; the key technical challenge is arguing that one can use state-of-the-art factorizations for sensitivity vector sets with the properties we isolate. Empirically and analytically, we demonstrate that our improved error bounds offer a substantial improvement in accuracy for cardinality estimation problems over a large range of parameters.
An Empirical Study of Causal Relation Extraction Transfer: Design and Data
Mar 08, 2025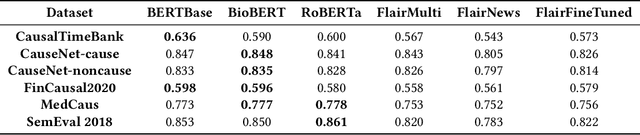
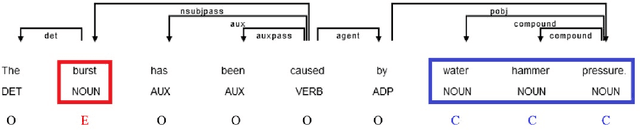

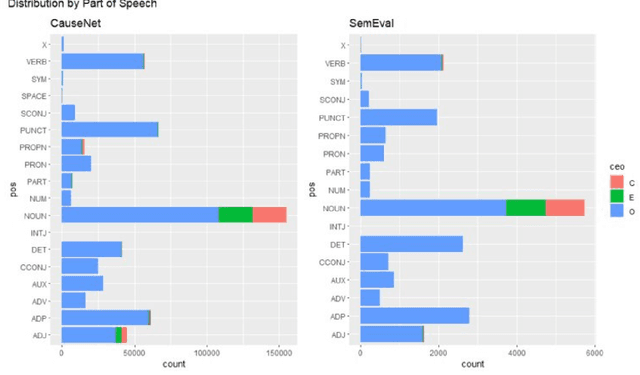
We conduct an empirical analysis of neural network architectures and data transfer strategies for causal relation extraction. By conducting experiments with various contextual embedding layers and architectural components, we show that a relatively straightforward BioBERT-BiGRU relation extraction model generalizes better than other architectures across varying web-based sources and annotation strategies. Furthermore, we introduce a metric for evaluating transfer performance, $F1_{phrase}$ that emphasizes noun phrase localization rather than directly matching target tags. Using this metric, we can conduct data transfer experiments, ultimately revealing that augmentation with data with varying domains and annotation styles can improve performance. Data augmentation is especially beneficial when an adequate proportion of implicitly and explicitly causal sentences are included.
From RAG to RICHES: Retrieval Interlaced with Sequence Generation
Jun 29, 2024We present RICHES, a novel approach that interleaves retrieval with sequence generation tasks. RICHES offers an alternative to conventional RAG systems by eliminating the need for separate retriever and generator. It retrieves documents by directly decoding their contents, constrained on the corpus. Unifying retrieval with generation allows us to adapt to diverse new tasks via prompting alone. RICHES can work with any Instruction-tuned model, without additional training. It provides attributed evidence, supports multi-hop retrievals and interleaves thoughts to plan on what to retrieve next, all within a single decoding pass of the LLM. We demonstrate the strong performance of RICHES across ODQA tasks including attributed and multi-hop QA.
1-PAGER: One Pass Answer Generation and Evidence Retrieval
Oct 25, 2023We present 1-Pager the first system that answers a question and retrieves evidence using a single Transformer-based model and decoding process. 1-Pager incrementally partitions the retrieval corpus using constrained decoding to select a document and answer string, and we show that this is competitive with comparable retrieve-and-read alternatives according to both retrieval and answer accuracy metrics. 1-Pager also outperforms the equivalent closed-book question answering model, by grounding predictions in an evidence corpus. While 1-Pager is not yet on-par with more expensive systems that read many more documents before generating an answer, we argue that it provides an important step toward attributed generation by folding retrieval into the sequence-to-sequence paradigm that is currently dominant in NLP. We also show that the search paths used to partition the corpus are easy to read and understand, paving a way forward for interpretable neural retrieval.
DIFFQG: Generating Questions to Summarize Factual Changes
Mar 01, 2023
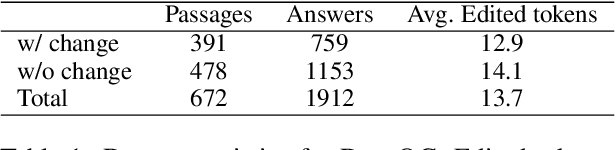
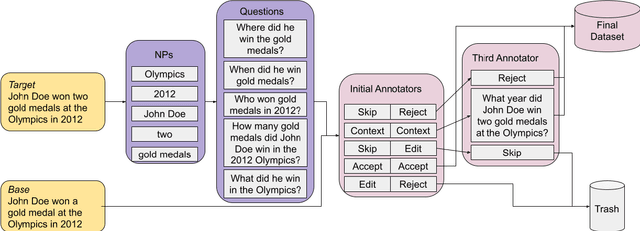
Identifying the difference between two versions of the same article is useful to update knowledge bases and to understand how articles evolve. Paired texts occur naturally in diverse situations: reporters write similar news stories and maintainers of authoritative websites must keep their information up to date. We propose representing factual changes between paired documents as question-answer pairs, where the answer to the same question differs between two versions. We find that question-answer pairs can flexibly and concisely capture the updated contents. Provided with paired documents, annotators identify questions that are answered by one passage but answered differently or cannot be answered by the other. We release DIFFQG which consists of 759 QA pairs and 1153 examples of paired passages with no factual change. These questions are intended to be both unambiguous and information-seeking and involve complex edits, pushing beyond the capabilities of current question generation and factual change detection systems. Our dataset summarizes the changes between two versions of the document as questions and answers, studying automatic update summarization in a novel way.