 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption
TANQ: An open domain dataset of table answered questions
May 13, 2024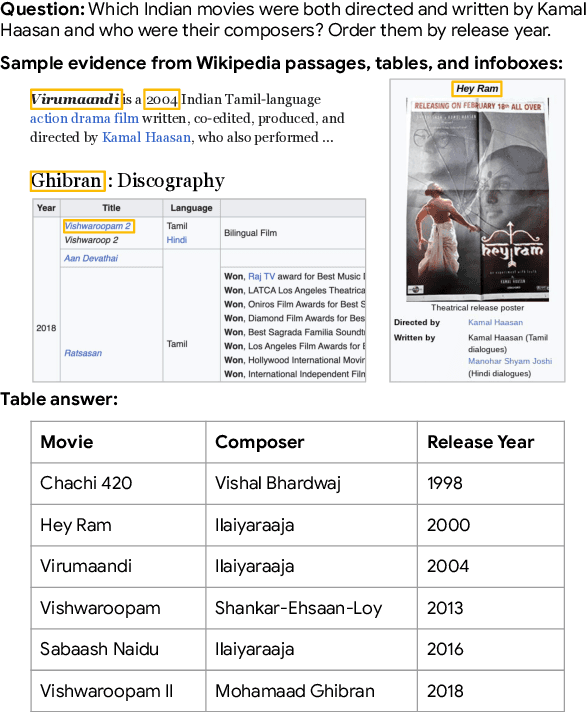
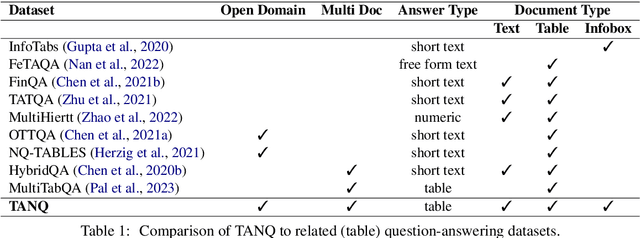
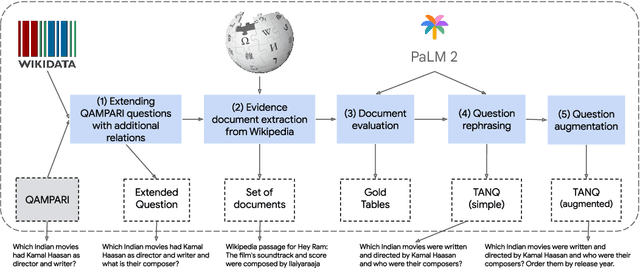
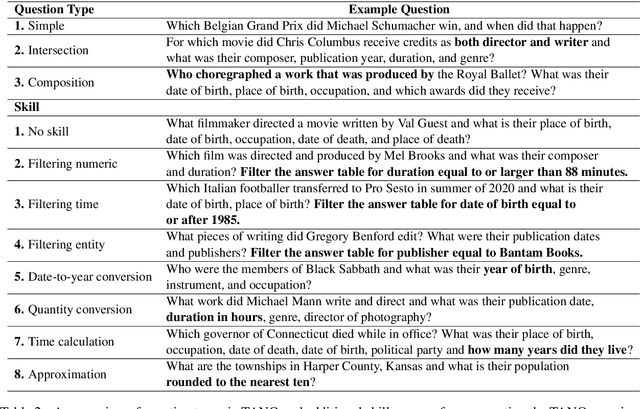
Language models, potentially augmented with tool usage such as retrieval are becoming the go-to means of answering questions. Understanding and answering questions in real-world settings often requires retrieving information from different sources, processing and aggregating data to extract insights, and presenting complex findings in form of structured artifacts such as novel tables, charts, or infographics. In this paper, we introduce TANQ, the first open domain question answering dataset where the answers require building tables from information across multiple sources. We release the full source attribution for every cell in the resulting table and benchmark state-of-the-art language models in open, oracle, and closed book setups. Our best-performing baseline, GPT4 reaches an overall F1 score of 29.1, lagging behind human performance by 19.7 points. We analyse baselines' performance across different dataset attributes such as different skills required for this task, including multi-hop reasoning, math operations, and unit conversions. We further discuss common failures in model-generated answers, suggesting that TANQ is a complex task with many challenges ahead.
Structsum Generation for Faster Text Comprehension
Jan 12, 2024



We consider the task of generating structured representations of text using large language models (LLMs). We focus on tables and mind maps as representative modalities. Tables are more organized way of representing data, while mind maps provide a visually dynamic and flexible approach, particularly suitable for sparse content. Despite the effectiveness of LLMs on different tasks, we show that current models struggle with generating structured outputs. In response, we present effective prompting strategies for both of these tasks. We introduce a taxonomy of problems around factuality, global and local structure, common to both modalities and propose a set of critiques to tackle these issues resulting in an absolute improvement in accuracy of +37pp (79%) for mind maps and +15pp (78%) for tables. To evaluate semantic coverage of generated structured representations we propose Auto-QA, and we verify the adequacy of Auto-QA using SQuAD dataset. We further evaluate the usefulness of structured representations via a text comprehension user study. The results show a significant reduction in comprehension time compared to text when using table (42.9%) and mind map (31.9%), without loss in accuracy.