 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Apr 01, 2025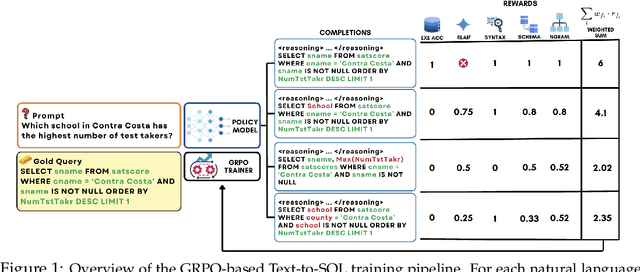
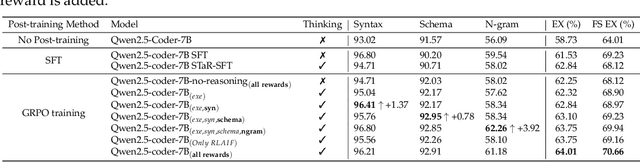
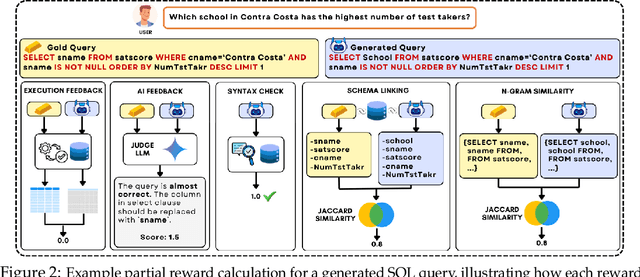
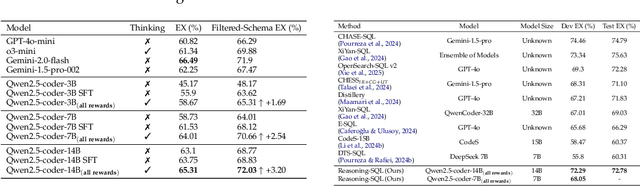
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
RLCAD: Reinforcement Learning Training Gym for Revolution Involved CAD Command Sequence Generation
Mar 24, 2025A CAD command sequence is a typical parametric design paradigm in 3D CAD systems where a model is constructed by overlaying 2D sketches with operations such as extrusion, revolution, and Boolean operations. Although there is growing academic interest in the automatic generation of command sequences, existing methods and datasets only support operations such as 2D sketching, extrusion,and Boolean operations. This limitation makes it challenging to represent more complex geometries. In this paper, we present a reinforcement learning (RL) training environment (gym) built on a CAD geometric engine. Given an input boundary representation (B-Rep) geometry, the policy network in the RL algorithm generates an action. This action, along with previously generated actions, is processed within the gym to produce the corresponding CAD geometry, which is then fed back into the policy network. The rewards, determined by the difference between the generated and target geometries within the gym, are used to update the RL network. Our method supports operations beyond sketches, Boolean, and extrusion, including revolution operations. With this training gym, we achieve state-of-the-art (SOTA) quality in generating command sequences from B-Rep geometries. In addition, our method can significantly improve the efficiency of command sequence generation by a factor of 39X compared with the previous training gym.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging
Aug 22, 2024



Text-to-SQL systems, which convert natural language queries into SQL commands, have seen significant progress primarily for the SQLite dialect. However, adapting these systems to other SQL dialects like BigQuery and PostgreSQL remains a challenge due to the diversity in SQL syntax and functions. We introduce SQL-GEN, a framework for generating high-quality dialect-specific synthetic data guided by dialect-specific tutorials, and demonstrate its effectiveness in creating training datasets for multiple dialects. Our approach significantly improves performance, by up to 20\%, over previous methods and reduces the gap with large-scale human-annotated datasets. Moreover, combining our synthetic data with human-annotated data provides additional performance boosts of 3.3\% to 5.6\%. We also introduce a novel Mixture of Experts (MoE) initialization method that integrates dialect-specific models into a unified system by merging self-attention layers and initializing the gates with dialect-specific keywords, further enhancing performance across different SQL dialects.
RadCLIP: Enhancing Radiologic Image Analysis through Contrastive Language-Image Pre-training
Mar 15, 2024



The integration of artificial intelligence (AI) with radiology has marked a transformative era in medical diagnostics. Vision foundation models have been adopted to enhance radiologic imaging analysis. However, the distinct complexities of radiological imaging, including the interpretation of 2D and 3D radiological data, pose unique challenges that existing models, trained on general non-medical images, fail to address adequately. To bridge this gap and capitalize on the diagnostic precision required in medical imaging, we introduce RadCLIP: a pioneering cross-modal foundational model that harnesses Contrastive Language-Image Pre-training (CLIP) to refine radiologic image analysis. RadCLIP incorporates a novel 3D slice pooling mechanism tailored for volumetric image analysis and is trained using a comprehensive and diverse dataset of radiologic image-text pairs. Our evaluations demonstrate that RadCLIP effectively aligns radiological images with their corresponding textual annotations, and in the meantime, offers a robust vision backbone for radiologic imagery with significant promise.
Joint Self-Supervised and Supervised Contrastive Learning for Multimodal MRI Data: Towards Predicting Abnormal Neurodevelopment
Dec 22, 2023



The integration of different imaging modalities, such as structural, diffusion tensor, and functional magnetic resonance imaging, with deep learning models has yielded promising outcomes in discerning phenotypic characteristics and enhancing disease diagnosis. The development of such a technique hinges on the efficient fusion of heterogeneous multimodal features, which initially reside within distinct representation spaces. Naively fusing the multimodal features does not adequately capture the complementary information and could even produce redundancy. In this work, we present a novel joint self-supervised and supervised contrastive learning method to learn the robust latent feature representation from multimodal MRI data, allowing the projection of heterogeneous features into a shared common space, and thereby amalgamating both complementary and analogous information across various modalities and among similar subjects. We performed a comparative analysis between our proposed method and alternative deep multimodal learning approaches. Through extensive experiments on two independent datasets, the results demonstrated that our method is significantly superior to several other deep multimodal learning methods in predicting abnormal neurodevelopment. Our method has the capability to facilitate computer-aided diagnosis within clinical practice, harnessing the power of multimodal data.
Self-supervised Multi-view Clustering in Computer Vision: A Survey
Sep 18, 2023



Multi-view clustering (MVC) has had significant implications in cross-modal representation learning and data-driven decision-making in recent years. It accomplishes this by leveraging the consistency and complementary information among multiple views to cluster samples into distinct groups. However, as contrastive learning continues to evolve within the field of computer vision, self-supervised learning has also made substantial research progress and is progressively becoming dominant in MVC methods. It guides the clustering process by designing proxy tasks to mine the representation of image and video data itself as supervisory information. Despite the rapid development of self-supervised MVC, there has yet to be a comprehensive survey to analyze and summarize the current state of research progress. Therefore, this paper explores the reasons and advantages of the emergence of self-supervised MVC and discusses the internal connections and classifications of common datasets, data issues, representation learning methods, and self-supervised learning methods. This paper does not only introduce the mechanisms for each category of methods but also gives a few examples of how these techniques are used. In the end, some open problems are pointed out for further investigation and development.
A Novel Collaborative Self-Supervised Learning Method for Radiomic Data
Feb 20, 2023



The computer-aided disease diagnosis from radiomic data is important in many medical applications. However, developing such a technique relies on annotating radiological images, which is a time-consuming, labor-intensive, and expensive process. In this work, we present the first novel collaborative self-supervised learning method to solve the challenge of insufficient labeled radiomic data, whose characteristics are different from text and image data. To achieve this, we present two collaborative pretext tasks that explore the latent pathological or biological relationships between regions of interest and the similarity and dissimilarity information between subjects. Our method collaboratively learns the robust latent feature representations from radiomic data in a self-supervised manner to reduce human annotation efforts, which benefits the disease diagnosis. We compared our proposed method with other state-of-the-art self-supervised learning methods on a simulation study and two independent datasets. Extensive experimental results demonstrated that our method outperforms other self-supervised learning methods on both classification and regression tasks. With further refinement, our method shows the potential advantage in automatic disease diagnosis with large-scale unlabeled data available.
A Novel Ontology-guided Attribute Partitioning Ensemble Learning Model for Early Prediction of Cognitive Deficits using Quantitative Structural MRI in Very Preterm Infants
Feb 08, 2022

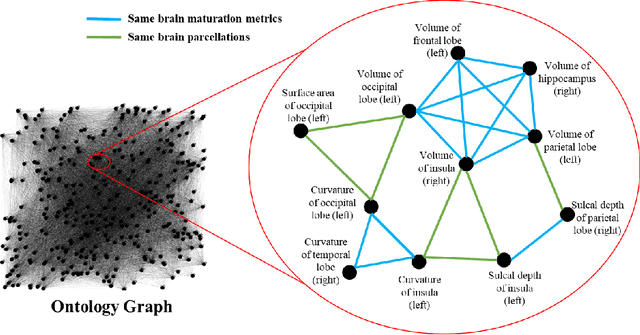
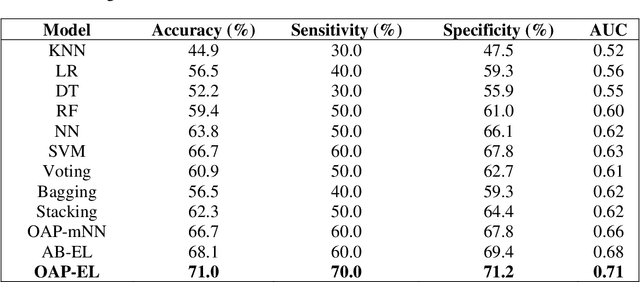
Structural magnetic resonance imaging studies have shown that brain anatomical abnormalities are associated with cognitive deficits in preterm infants. Brain maturation and geometric features can be used with machine learning models for predicting later neurodevelopmental deficits. However, traditional machine learning models would suffer from a large feature-to-instance ratio (i.e., a large number of features but a small number of instances/samples). Ensemble learning is a paradigm that strategically generates and integrates a library of machine learning classifiers and has been successfully used on a wide variety of predictive modeling problems to boost model performance. Attribute (i.e., feature) bagging method is the most commonly used feature partitioning scheme, which randomly and repeatedly draws feature subsets from the entire feature set. Although attribute bagging method can effectively reduce feature dimensionality to handle the large feature-to-instance ratio, it lacks consideration of domain knowledge and latent relationship among features. In this study, we proposed a novel Ontology-guided Attribute Partitioning (OAP) method to better draw feature subsets by considering domain-specific relationship among features. With the better partitioned feature subsets, we developed an ensemble learning framework, which is referred to as OAP Ensemble Learning (OAP-EL). We applied the OAP-EL to predict cognitive deficits at 2 year of age using quantitative brain maturation and geometric features obtained at term equivalent age in very preterm infants. We demonstrated that the proposed OAP-EL approach significantly outperformed the peer ensemble learning and traditional machine learning approaches.
SEA: A Combined Model for Heat Demand Prediction
Jul 28, 2018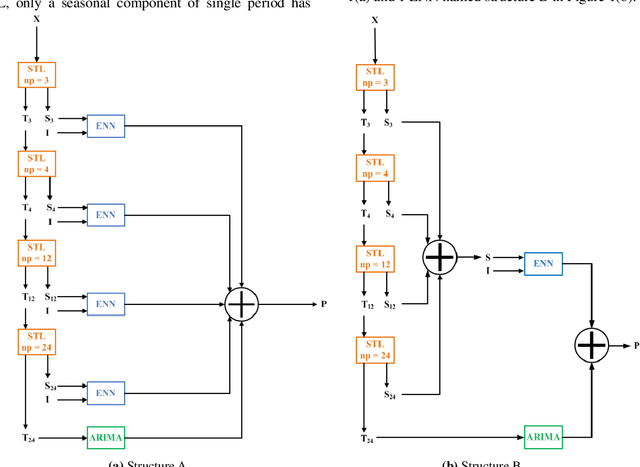
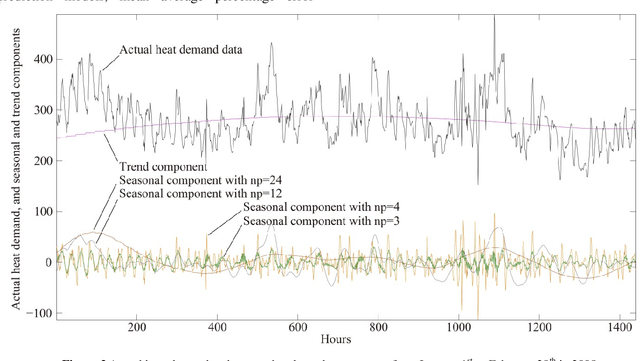
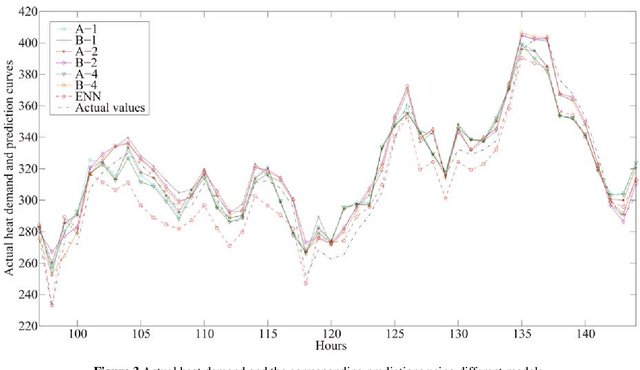
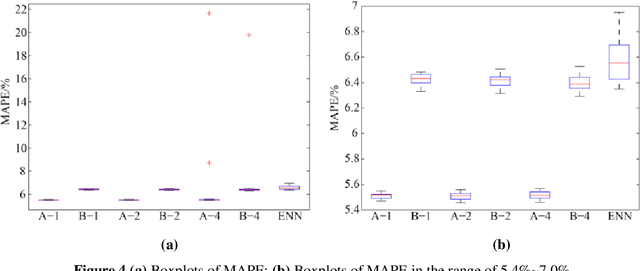
Heat demand prediction is a prominent research topic in the area of intelligent energy networks. It has been well recognized that periodicity is one of the important characteristics of heat demand. Seasonal-trend decomposition based on LOESS (STL) algorithm can analyze the periodicity of a heat demand series, and decompose the series into seasonal and trend components. Then, predicting the seasonal and trend components respectively, and combining their predictions together as the heat demand prediction is a possible way to predict heat demand. In this paper, STL-ENN-ARIMA (SEA), a combined model, was proposed based on the combination of the Elman neural network (ENN) and the autoregressive integrated moving average (ARIMA) model, which are commonly applied to heat demand prediction. ENN and ARIMA are used to predict seasonal and trend components, respectively. Experimental results demonstrate that the proposed SEA model has a promising performance.