 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadCLIP: Enhancing Radiologic Image Analysis through Contrastive Language-Image Pre-training
Mar 15, 2024



The integration of artificial intelligence (AI) with radiology has marked a transformative era in medical diagnostics. Vision foundation models have been adopted to enhance radiologic imaging analysis. However, the distinct complexities of radiological imaging, including the interpretation of 2D and 3D radiological data, pose unique challenges that existing models, trained on general non-medical images, fail to address adequately. To bridge this gap and capitalize on the diagnostic precision required in medical imaging, we introduce RadCLIP: a pioneering cross-modal foundational model that harnesses Contrastive Language-Image Pre-training (CLIP) to refine radiologic image analysis. RadCLIP incorporates a novel 3D slice pooling mechanism tailored for volumetric image analysis and is trained using a comprehensive and diverse dataset of radiologic image-text pairs. Our evaluations demonstrate that RadCLIP effectively aligns radiological images with their corresponding textual annotations, and in the meantime, offers a robust vision backbone for radiologic imagery with significant promise.
Joint Self-Supervised and Supervised Contrastive Learning for Multimodal MRI Data: Towards Predicting Abnormal Neurodevelopment
Dec 22, 2023



The integration of different imaging modalities, such as structural, diffusion tensor, and functional magnetic resonance imaging, with deep learning models has yielded promising outcomes in discerning phenotypic characteristics and enhancing disease diagnosis. The development of such a technique hinges on the efficient fusion of heterogeneous multimodal features, which initially reside within distinct representation spaces. Naively fusing the multimodal features does not adequately capture the complementary information and could even produce redundancy. In this work, we present a novel joint self-supervised and supervised contrastive learning method to learn the robust latent feature representation from multimodal MRI data, allowing the projection of heterogeneous features into a shared common space, and thereby amalgamating both complementary and analogous information across various modalities and among similar subjects. We performed a comparative analysis between our proposed method and alternative deep multimodal learning approaches. Through extensive experiments on two independent datasets, the results demonstrated that our method is significantly superior to several other deep multimodal learning methods in predicting abnormal neurodevelopment. Our method has the capability to facilitate computer-aided diagnosis within clinical practice, harnessing the power of multimodal data.
A Novel Collaborative Self-Supervised Learning Method for Radiomic Data
Feb 20, 2023



The computer-aided disease diagnosis from radiomic data is important in many medical applications. However, developing such a technique relies on annotating radiological images, which is a time-consuming, labor-intensive, and expensive process. In this work, we present the first novel collaborative self-supervised learning method to solve the challenge of insufficient labeled radiomic data, whose characteristics are different from text and image data. To achieve this, we present two collaborative pretext tasks that explore the latent pathological or biological relationships between regions of interest and the similarity and dissimilarity information between subjects. Our method collaboratively learns the robust latent feature representations from radiomic data in a self-supervised manner to reduce human annotation efforts, which benefits the disease diagnosis. We compared our proposed method with other state-of-the-art self-supervised learning methods on a simulation study and two independent datasets. Extensive experimental results demonstrated that our method outperforms other self-supervised learning methods on both classification and regression tasks. With further refinement, our method shows the potential advantage in automatic disease diagnosis with large-scale unlabeled data available.
A Novel Ontology-guided Attribute Partitioning Ensemble Learning Model for Early Prediction of Cognitive Deficits using Quantitative Structural MRI in Very Preterm Infants
Feb 08, 2022

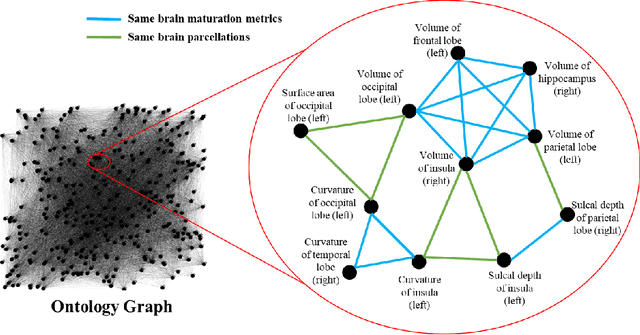
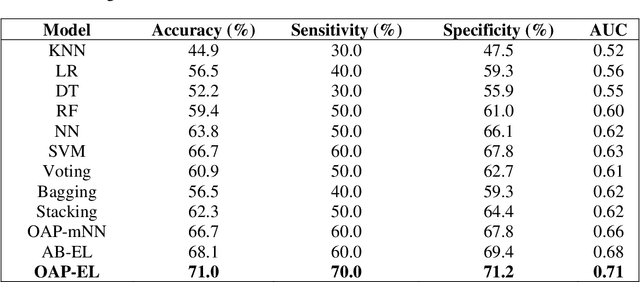
Structural magnetic resonance imaging studies have shown that brain anatomical abnormalities are associated with cognitive deficits in preterm infants. Brain maturation and geometric features can be used with machine learning models for predicting later neurodevelopmental deficits. However, traditional machine learning models would suffer from a large feature-to-instance ratio (i.e., a large number of features but a small number of instances/samples). Ensemble learning is a paradigm that strategically generates and integrates a library of machine learning classifiers and has been successfully used on a wide variety of predictive modeling problems to boost model performance. Attribute (i.e., feature) bagging method is the most commonly used feature partitioning scheme, which randomly and repeatedly draws feature subsets from the entire feature set. Although attribute bagging method can effectively reduce feature dimensionality to handle the large feature-to-instance ratio, it lacks consideration of domain knowledge and latent relationship among features. In this study, we proposed a novel Ontology-guided Attribute Partitioning (OAP) method to better draw feature subsets by considering domain-specific relationship among features. With the better partitioned feature subsets, we developed an ensemble learning framework, which is referred to as OAP Ensemble Learning (OAP-EL). We applied the OAP-EL to predict cognitive deficits at 2 year of age using quantitative brain maturation and geometric features obtained at term equivalent age in very preterm infants. We demonstrated that the proposed OAP-EL approach significantly outperformed the peer ensemble learning and traditional machine learning approaches.