 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity And Complex Test Data Generation For Real-World SQL Code Generation Services
Apr 24, 2025



The demand for high-fidelity test data is paramount in industrial settings where access to production data is largely restricted. Traditional data generation methods often fall short, struggling with low-fidelity and the ability to model complex data structures and semantic relationships that are critical for testing complex SQL code generation services like Natural Language to SQL (NL2SQL). In this paper, we address the critical need for generating syntactically correct and semantically ``meaningful'' mock data for complex schema that includes columns with nested structures that we frequently encounter in Google SQL code generation workloads. We highlight the limitations of existing approaches used in production, particularly their inability to handle large and complex schema, as well as the lack of semantically coherent test data that lead to limited test coverage. We demonstrate that by leveraging Large Language Models (LLMs) and incorporating strategic pre- and post-processing steps, we can generate realistic high-fidelity test data that adheres to complex structural constraints and maintains semantic integrity to the test targets (SQL queries/functions). This approach supports comprehensive testing of complex SQL queries involving joins, aggregations, and even deeply nested subqueries, ensuring robust evaluation of SQL code generation services, like NL2SQL and SQL Code Assistant services. Our results demonstrate the practical utility of an out-of-the-box LLM (\textit{gemini}) based test data generation for industrial SQL code generation services where generating realistic test data is essential due to the frequent unavailability of production datasets.
Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL
Jan 21, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks. In particular, improvements in reasoning abilities and the expansion of context windows have opened new avenues for leveraging these powerful models. NL2SQL is challenging in that the natural language question is inherently ambiguous, while the SQL generation requires a precise understanding of complex data schema and semantics. One approach to this semantic ambiguous problem is to provide more and sufficient contextual information. In this work, we explore the performance and the latency trade-offs of the extended context window (a.k.a., long context) offered by Google's state-of-the-art LLM (\textit{gemini-1.5-pro}). We study the impact of various contextual information, including column example values, question and SQL query pairs, user-provided hints, SQL documentation, and schema. To the best of our knowledge, this is the first work to study how the extended context window and extra contextual information can help NL2SQL generation with respect to both accuracy and latency cost. We show that long context LLMs are robust and do not get lost in the extended contextual information. Additionally, our long-context NL2SQL pipeline based on Google's \textit{gemini-pro-1.5} achieve a strong performance with 67.41\% on BIRD benchmark (dev) without finetuning and expensive self-consistency based techniques.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
BI-REC: Guided Data Analysis for Conversational Business Intelligence
May 02, 2021

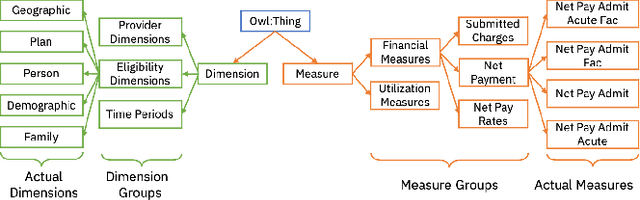
Conversational interfaces to Business Intelligence (BI) applications enable data analysis using a natural language dialog in small incremental steps. To truly unleash the power of conversational BI to democratize access to data, a system needs to provide effective and continuous support for data analysis. In this paper, we propose BI-REC, a conversational recommendation system for BI applications to help users accomplish their data analysis tasks. We define the space of data analysis in terms of BI patterns, augmented with rich semantic information extracted from the OLAP cube definition, and use graph embeddings learned using GraphSAGE to create a compact representation of the analysis state. We propose a two-step approach to explore the search space for useful BI pattern recommendations. In the first step, we train a multi-class classifier using prior query logs to predict the next high-level actions in terms of a BI operation (e.g., {\em Drill-Down} or {\em Roll-up}) and a measure that the user is interested in. In the second step, the high-level actions are further refined into actual BI pattern recommendations using collaborative filtering. This two-step approach allows us to not only divide and conquer the huge search space, but also requires less training data. Our experimental evaluation shows that BI-REC achieves an accuracy of 83% for BI pattern recommendations and up to 2X speedup in latency of prediction compared to a state-of-the-art baseline. Our user study further shows that BI-REC provides recommendations with a precision@3 of 91.90% across several different analysis tasks.
Improving Performance of heavily loaded agents
Dec 11, 2000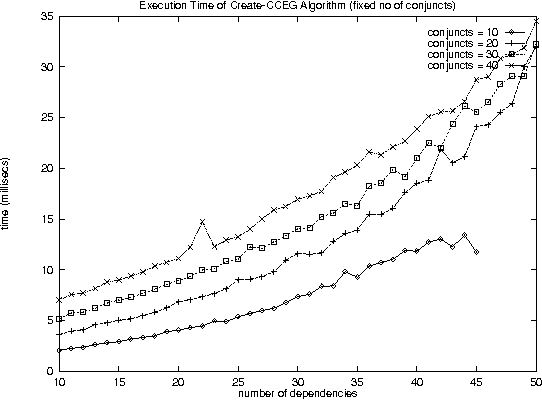
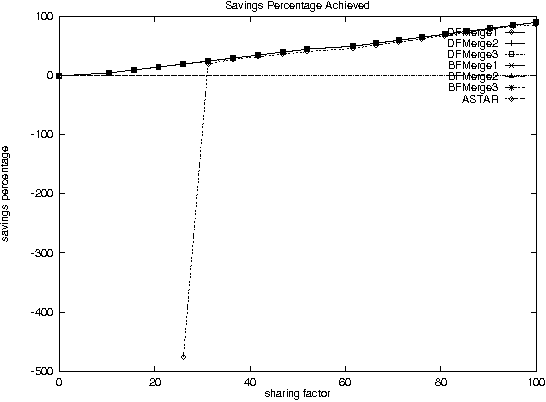
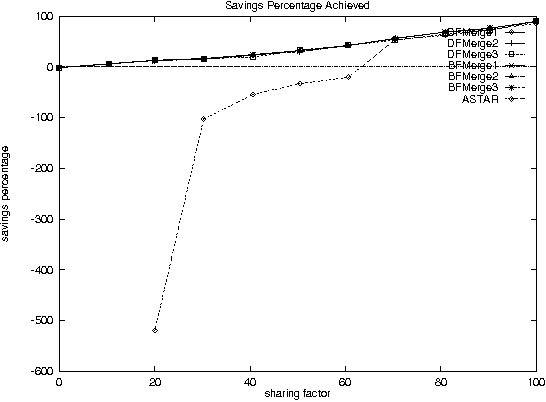
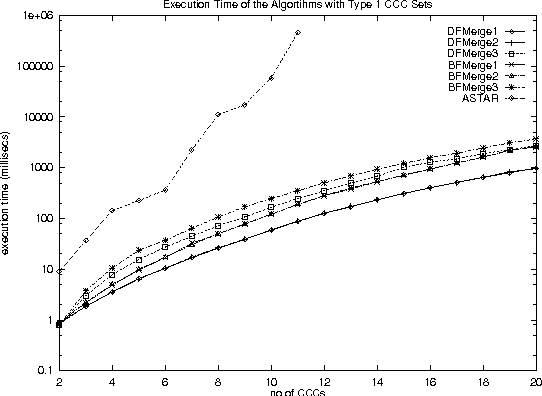
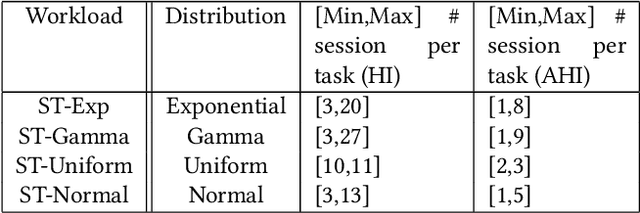
With the increase in agent-based applications, there are now agent systems that support \emph{concurrent} client accesses. The ability to process large volumes of simultaneous requests is critical in many such applications. In such a setting, the traditional approach of serving these requests one at a time via queues (e.g. \textsf{FIFO} queues, priority queues) is insufficient. Alternative models are essential to improve the performance of such \emph{heavily loaded} agents. In this paper, we propose a set of \emph{cost-based algorithms} to \emph{optimize} and \emph{merge} multiple requests submitted to an agent. In order to merge a set of requests, one first needs to identify commonalities among such requests. First, we provide an \emph{application independent framework} within which an agent developer may specify relationships (called \emph{invariants}) between requests. Second, we provide two algorithms (and various accompanying heuristics) which allow an agent to automatically rewrite requests so as to avoid redundant work---these algorithms take invariants associated with the agent into account. Our algorithms are independent of any specific agent framework. For an implementation, we implemented both these algorithms on top of the \impact agent development platform, and on top of a (non-\impact) geographic database agent. Based on these implementations, we conducted experiments and show that our algorithms are considerably more efficient than methods that use the $A^*$ algorithm.