 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Level Survey of Optical Remote Sensing
Feb 19, 2026In recent years, significant advances in computer vision have also propelled progress in remote sensing. Concurrently, the use of drones has expanded, with many organizations incorporating them into their operations. Most drones are equipped by default with RGB cameras, which are both robust and among the easiest sensors to use and interpret. The body of literature on optical remote sensing is vast, encompassing diverse tasks, capabilities, and methodologies. Each task or methodology could warrant a dedicated survey. This work provides a comprehensive overview of the capabilities of the field, while also presenting key information, such as datasets and insights. It aims to serve as a guide for researchers entering the field, offering high-level insights and helping them focus on areas most relevant to their interests. To the best of our knowledge, no existing survey addresses this holistic perspective.
Relationship Detection on Tabular Data Using Statistical Analysis and Large Language Models
Jun 04, 2025



Over the past few years, table interpretation tasks have made significant progress due to their importance and the introduction of new technologies and benchmarks in the field. This work experiments with a hybrid approach for detecting relationships among columns of unlabeled tabular data, using a Knowledge Graph (KG) as a reference point, a task known as CPA. This approach leverages large language models (LLMs) while employing statistical analysis to reduce the search space of potential KG relations. The main modules of this approach for reducing the search space are domain and range constraints detection, as well as relation co-appearance analysis. The experimental evaluation on two benchmark datasets provided by the SemTab challenge assesses the influence of each module and the effectiveness of different state-of-the-art LLMs at various levels of quantization. The experiments were performed, as well as at different prompting techniques. The proposed methodology, which is publicly available on github, proved to be competitive with state-of-the-art approaches on these datasets.
Knowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
Mar 17, 2022
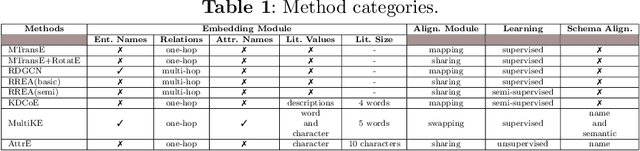


In recent years, we have witnessed the proliferation of knowledge graphs (KG) in various domains, aiming to support applications like question answering, recommendations, etc. A frequent task when integrating knowledge from different KGs is to find which subgraphs refer to the same real-world entity. Recently, embedding methods have been used for entity alignment tasks, that learn a vector-space representation of entities which preserves their similarity in the original KGs. A wide variety of supervised, unsupervised, and semi-supervised methods have been proposed that exploit both factual (attribute based) and structural information (relation based) of entities in the KGs. Still, a quantitative assessment of their strengths and weaknesses in real-world KGs according to different performance metrics and KG characteristics is missing from the literature. In this work, we conduct the first meta-level analysis of popular embedding methods for entity alignment, based on a statistically sound methodology. Our analysis reveals statistically significant correlations of different embedding methods with various meta-features extracted by KGs and rank them in a statistically significant way according to their effectiveness across all real-world KGs of our testbed. Finally, we study interesting trade-offs in terms of methods' effectiveness and efficiency.
BI-REC: Guided Data Analysis for Conversational Business Intelligence
May 02, 2021

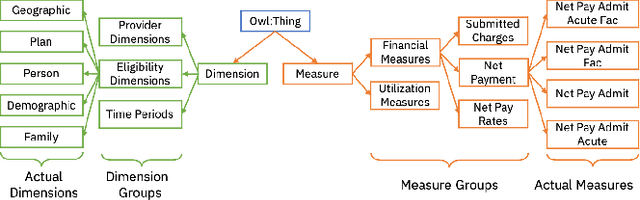
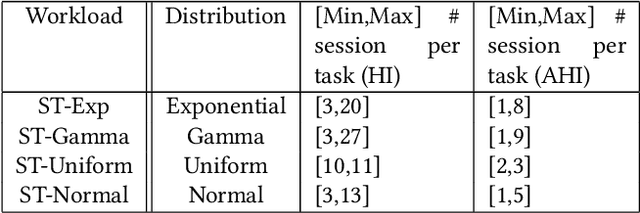
Conversational interfaces to Business Intelligence (BI) applications enable data analysis using a natural language dialog in small incremental steps. To truly unleash the power of conversational BI to democratize access to data, a system needs to provide effective and continuous support for data analysis. In this paper, we propose BI-REC, a conversational recommendation system for BI applications to help users accomplish their data analysis tasks. We define the space of data analysis in terms of BI patterns, augmented with rich semantic information extracted from the OLAP cube definition, and use graph embeddings learned using GraphSAGE to create a compact representation of the analysis state. We propose a two-step approach to explore the search space for useful BI pattern recommendations. In the first step, we train a multi-class classifier using prior query logs to predict the next high-level actions in terms of a BI operation (e.g., {\em Drill-Down} or {\em Roll-up}) and a measure that the user is interested in. In the second step, the high-level actions are further refined into actual BI pattern recommendations using collaborative filtering. This two-step approach allows us to not only divide and conquer the huge search space, but also requires less training data. Our experimental evaluation shows that BI-REC achieves an accuracy of 83% for BI pattern recommendations and up to 2X speedup in latency of prediction compared to a state-of-the-art baseline. Our user study further shows that BI-REC provides recommendations with a precision@3 of 91.90% across several different analysis tasks.
Medical Entity Disambiguation Using Graph Neural Networks
Apr 03, 2021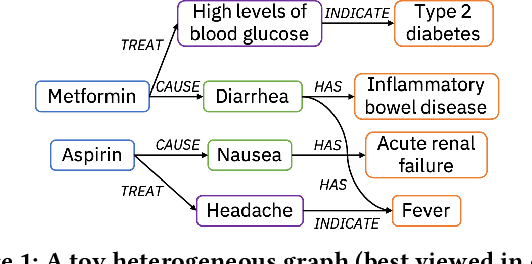
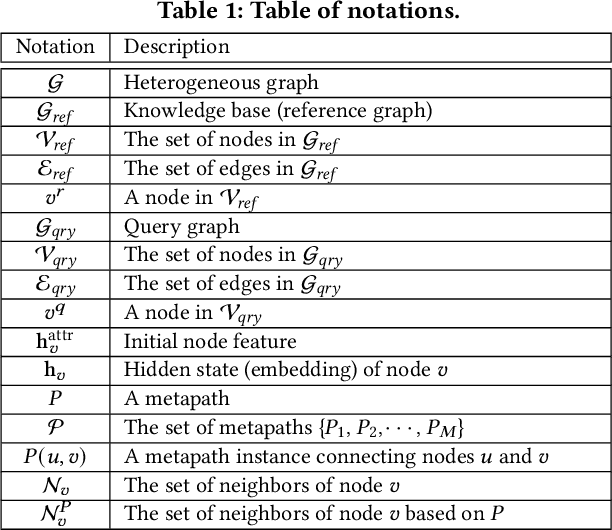
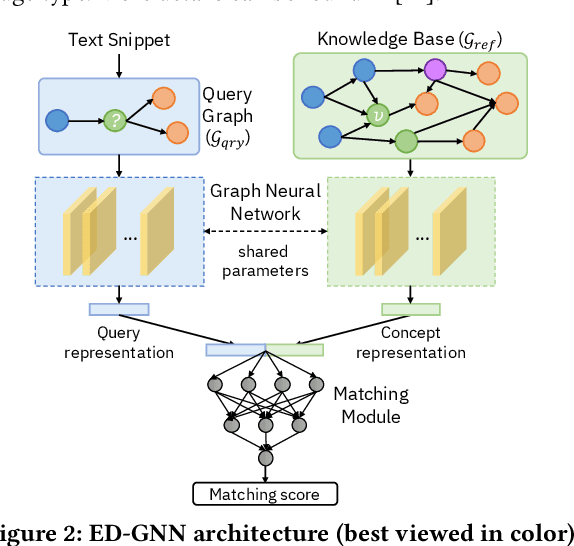
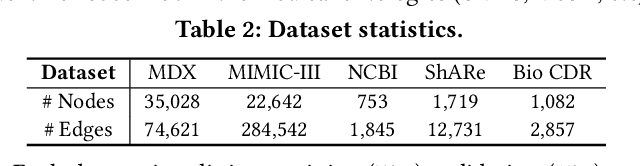
Medical knowledge bases (KBs), distilled from biomedical literature and regulatory actions, are expected to provide high-quality information to facilitate clinical decision making. Entity disambiguation (also referred to as entity linking) is considered as an essential task in unlocking the wealth of such medical KBs. However, existing medical entity disambiguation methods are not adequate due to word discrepancies between the entities in the KB and the text snippets in the source documents. Recently, graph neural networks (GNNs) have proven to be very effective and provide state-of-the-art results for many real-world applications with graph-structured data. In this paper, we introduce ED-GNN based on three representative GNNs (GraphSAGE, R-GCN, and MAGNN) for medical entity disambiguation. We develop two optimization techniques to fine-tune and improve ED-GNN. First, we introduce a novel strategy to represent entities that are mentioned in text snippets as a query graph. Second, we design an effective negative sampling strategy that identifies hard negative samples to improve the model's disambiguation capability. Compared to the best performing state-of-the-art solutions, our ED-GNN offers an average improvement of 7.3% in terms of F1 score on five real-world datasets.