 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Influence Signals for Data Debugging
Jun 13, 2025



Improving the quality of training samples is crucial for improving the reliability and performance of ML models. In this paper, we conduct a comparative evaluation of influence-based signals for debugging training data. These signals can potentially identify both mislabeled and anomalous samples from a potentially noisy training set as we build the models and hence alleviate the need for dedicated glitch detectors. Although several influence-based signals (e.g., Self-Influence, Average Absolute Influence, Marginal Influence, GD-class) have been recently proposed in the literature, there are no experimental studies for assessing their power in detecting different glitch types (e.g., mislabeled and anomalous samples) under a common influence estimator (e.g., TraceIn) for different data modalities (image and tabular), and deep learning models (trained from scratch or foundation). Through extensive experiments, we show that signals like Self-Influence effectively detect mislabeled samples, but none of the existing signals can detect anomalies. Existing signals do not take into account the training dynamics, i.e., how the samples' influence on the model changes during training, while some signals fall into influence cancellation effects, i.e., influence score is zero due to unsigned scores accumulation, resulting in misleading influence attribution.
SeeABLE: Soft Discrepancies and Bounded Contrastive Learning for Exposing Deepfakes
Nov 21, 2022Modern deepfake detectors have achieved encouraging results, when training and test images are drawn from the same collection. However, when applying these detectors to faces manipulated using an unknown technique, considerable performance drops are typically observed. In this work, we propose a novel deepfake detector, called SeeABLE, that formalizes the detection problem as a (one-class) out-of-distribution detection task and generalizes better to unseen deepfakes. Specifically, SeeABLE uses a novel data augmentation strategy to synthesize fine-grained local image anomalies (referred to as soft-discrepancies) and pushes those pristine disrupted faces towards predefined prototypes using a novel regression-based bounded contrastive loss. To strengthen the generalization performance of SeeABLE to unknown deepfake types, we generate a rich set of soft discrepancies and train the detector: (i) to localize, which part of the face was modified, and (ii) to identify the alteration type. Using extensive experiments on widely used datasets, SeeABLE considerably outperforms existing detectors, with gains of up to +10\% on the DFDC-preview dataset in term of detection accuracy over SoTA methods while using a simpler model. Code will be made publicly available.
A Meta-level Analysis of Online Anomaly Detectors
Sep 13, 2022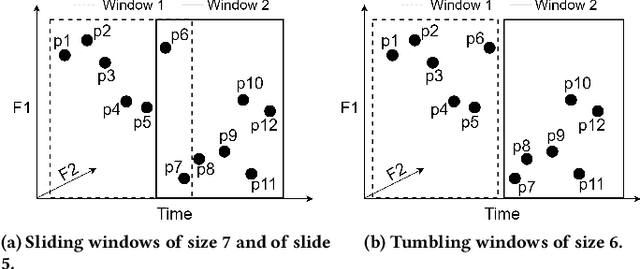
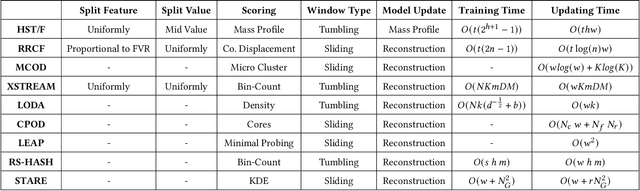
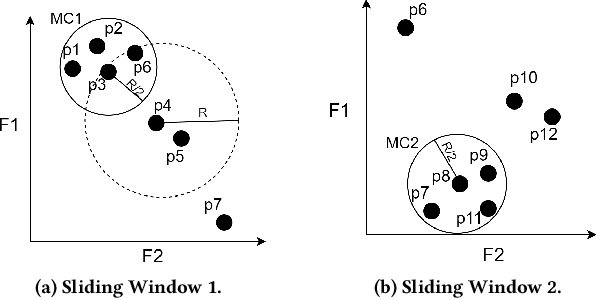
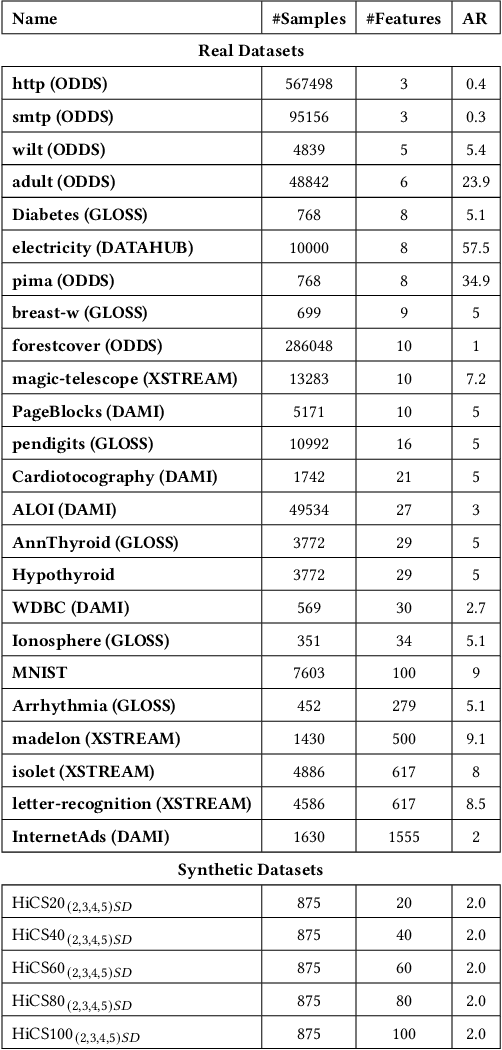
Real-time detection of anomalies in streaming data is receiving increasing attention as it allows us to raise alerts, predict faults, and detect intrusions or threats across industries. Yet, little attention has been given to compare the effectiveness and efficiency of anomaly detectors for streaming data (i.e., of online algorithms). In this paper, we present a qualitative, synthetic overview of major online detectors from different algorithmic families (i.e., distance, density, tree or projection-based) and highlight their main ideas for constructing, updating and testing detection models. Then, we provide a thorough analysis of the results of a quantitative experimental evaluation of online detection algorithms along with their offline counterparts. The behavior of the detectors is correlated with the characteristics of different datasets (i.e., meta-features), thereby providing a meta-level analysis of their performance. Our study addresses several missing insights from the literature such as (a) how reliable are detectors against a random classifier and what dataset characteristics make them perform randomly; (b) to what extent online detectors approximate the performance of offline counterparts; (c) which sketch strategy and update primitives of detectors are best to detect anomalies visible only within a feature subspace of a dataset; (d) what are the tradeoffs between the effectiveness and the efficiency of detectors belonging to different algorithmic families; (e) which specific characteristics of datasets yield an online algorithm to outperform all others.
Knowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
Mar 17, 2022
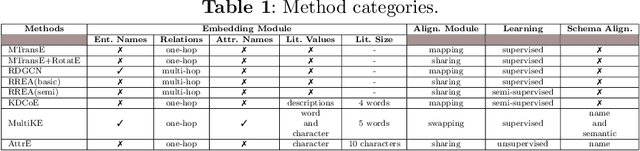


In recent years, we have witnessed the proliferation of knowledge graphs (KG) in various domains, aiming to support applications like question answering, recommendations, etc. A frequent task when integrating knowledge from different KGs is to find which subgraphs refer to the same real-world entity. Recently, embedding methods have been used for entity alignment tasks, that learn a vector-space representation of entities which preserves their similarity in the original KGs. A wide variety of supervised, unsupervised, and semi-supervised methods have been proposed that exploit both factual (attribute based) and structural information (relation based) of entities in the KGs. Still, a quantitative assessment of their strengths and weaknesses in real-world KGs according to different performance metrics and KG characteristics is missing from the literature. In this work, we conduct the first meta-level analysis of popular embedding methods for entity alignment, based on a statistically sound methodology. Our analysis reveals statistically significant correlations of different embedding methods with various meta-features extracted by KGs and rank them in a statistically significant way according to their effectiveness across all real-world KGs of our testbed. Finally, we study interesting trade-offs in terms of methods' effectiveness and efficiency.
On Predictive Explanation of Data Anomalies
Oct 18, 2021Numerous algorithms have been proposed for detecting anomalies (outliers, novelties) in an unsupervised manner. Unfortunately, it is not trivial, in general, to understand why a given sample (record) is labelled as an anomaly and thus diagnose its root causes. We propose the following reduced-dimensionality, surrogate model approach to explain detector decisions: approximate the detection model with another one that employs only a small subset of features. Subsequently, samples can be visualized in this low-dimensionality space for human understanding. To this end, we develop PROTEUS, an AutoML pipeline to produce the surrogate model, specifically designed for feature selection on imbalanced datasets. The PROTEUS surrogate model can not only explain the training data, but also the out-of-sample (unseen) data. In other words, PROTEUS produces predictive explanations by approximating the decision surface of an unsupervised detector. PROTEUS is designed to return an accurate estimate of out-of-sample predictive performance to serve as a metric of the quality of the approximation. Computational experiments confirm the efficacy of PROTEUS to produce predictive explanations for different families of detectors and to reliably estimate their predictive performance in unseen data. Unlike several ad-hoc feature importance methods, PROTEUS is robust to high-dimensional data.
Massively-Parallel Feature Selection for Big Data
Aug 23, 2017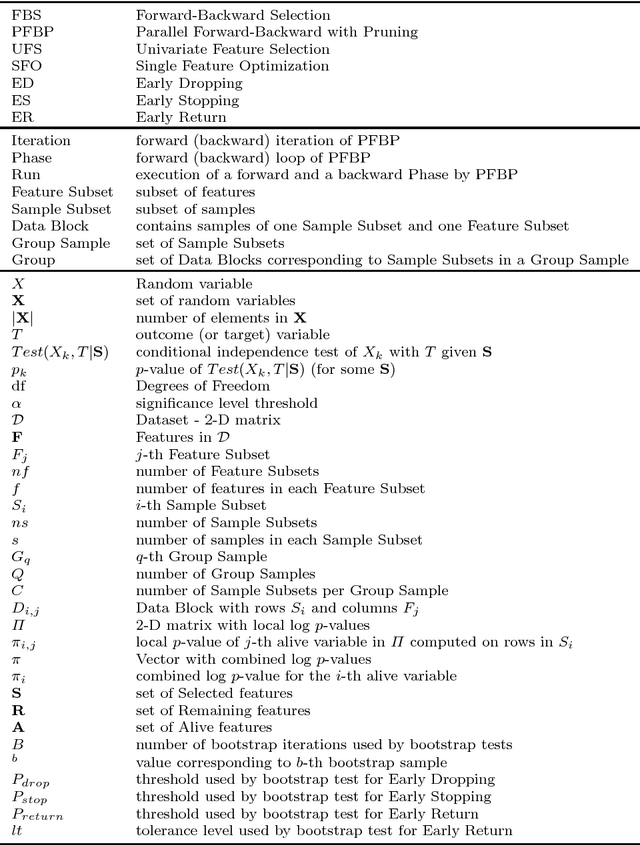
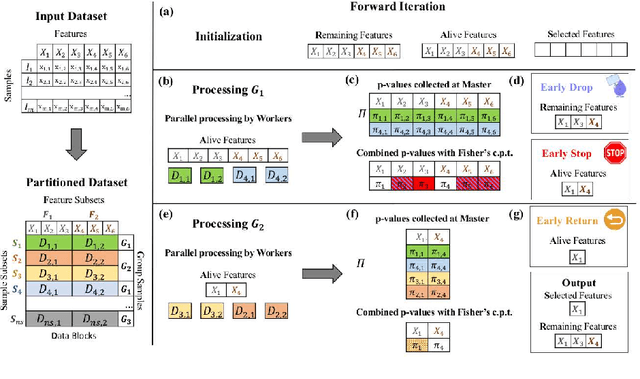
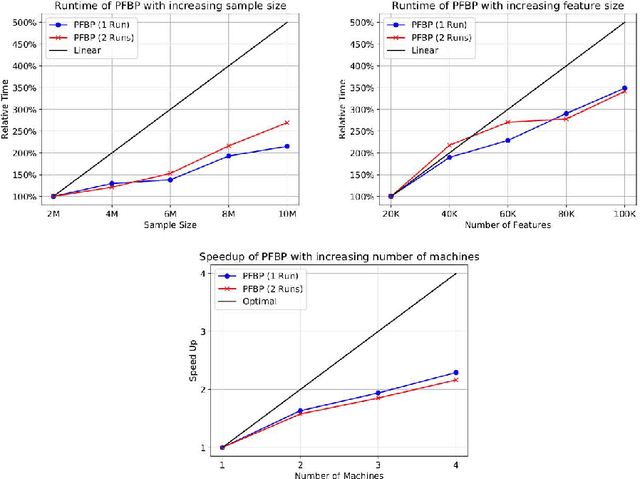
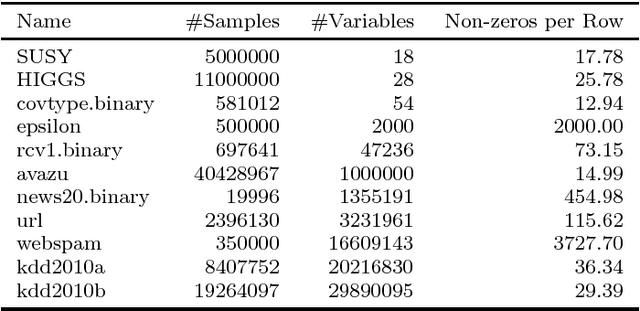
We present the Parallel, Forward-Backward with Pruning (PFBP) algorithm for feature selection (FS) in Big Data settings (high dimensionality and/or sample size). To tackle the challenges of Big Data FS PFBP partitions the data matrix both in terms of rows (samples, training examples) as well as columns (features). By employing the concepts of $p$-values of conditional independence tests and meta-analysis techniques PFBP manages to rely only on computations local to a partition while minimizing communication costs. Then, it employs powerful and safe (asymptotically sound) heuristics to make early, approximate decisions, such as Early Dropping of features from consideration in subsequent iterations, Early Stopping of consideration of features within the same iteration, or Early Return of the winner in each iteration. PFBP provides asymptotic guarantees of optimality for data distributions faithfully representable by a causal network (Bayesian network or maximal ancestral graph). Our empirical analysis confirms a super-linear speedup of the algorithm with increasing sample size, linear scalability with respect to the number of features and processing cores, while dominating other competitive algorithms in its class.