 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Planning for Optimal Data Pipeline Instantiation
Mar 16, 2025
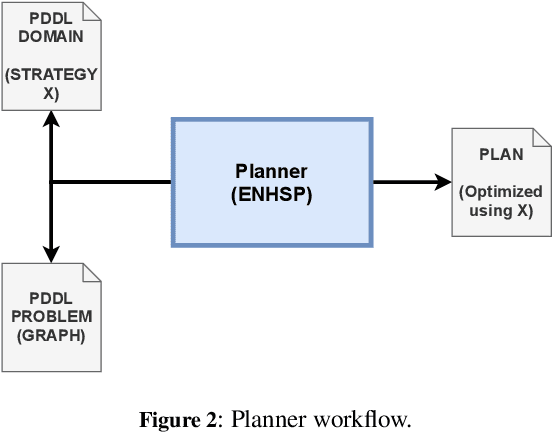


Data pipeline frameworks provide abstractions for implementing sequences of data-intensive transformation operators, automating the deployment and execution of such transformations in a cluster. Deploying a data pipeline, however, requires computing resources to be allocated in a data center, ideally minimizing the overhead for communicating data and executing operators in the pipeline while considering each operator's execution requirements. In this paper, we model the problem of optimal data pipeline deployment as planning with action costs, where we propose heuristics aiming to minimize total execution time. Experimental results indicate that the heuristics can outperform the baseline deployment and that a heuristic based on connections outperforms other strategies.
A Meta-level Analysis of Online Anomaly Detectors
Sep 13, 2022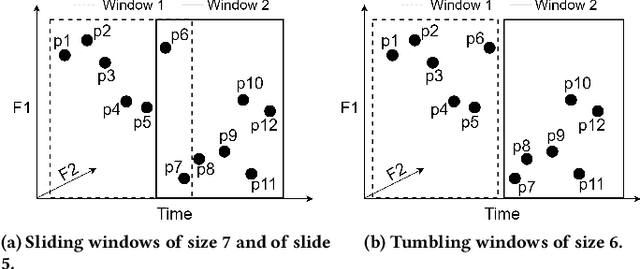
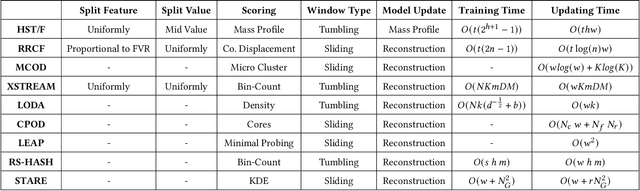
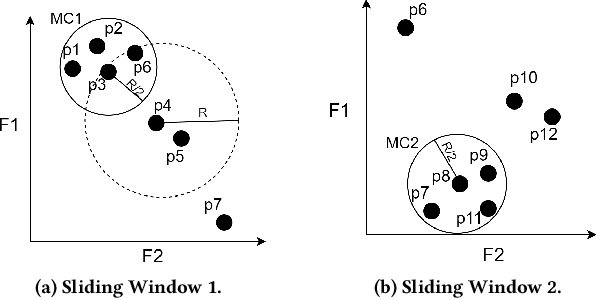
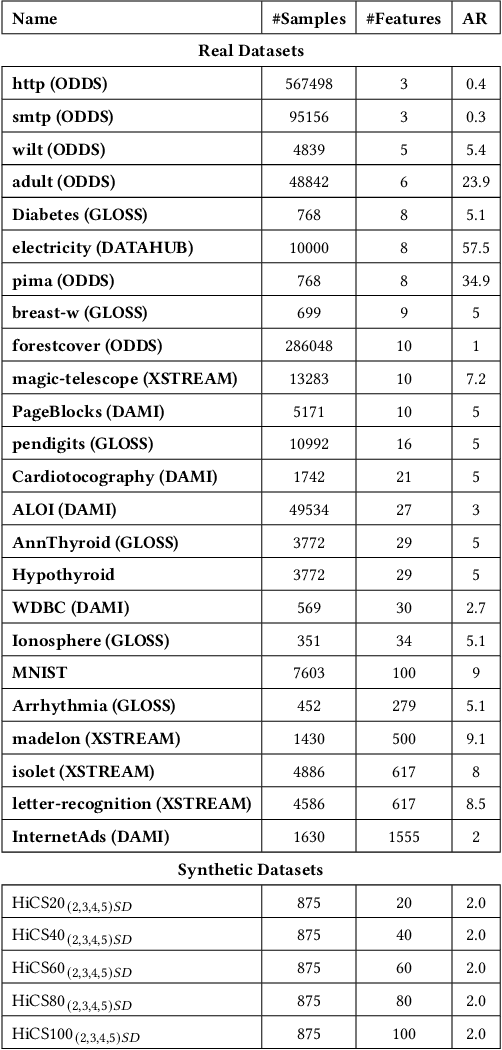
Real-time detection of anomalies in streaming data is receiving increasing attention as it allows us to raise alerts, predict faults, and detect intrusions or threats across industries. Yet, little attention has been given to compare the effectiveness and efficiency of anomaly detectors for streaming data (i.e., of online algorithms). In this paper, we present a qualitative, synthetic overview of major online detectors from different algorithmic families (i.e., distance, density, tree or projection-based) and highlight their main ideas for constructing, updating and testing detection models. Then, we provide a thorough analysis of the results of a quantitative experimental evaluation of online detection algorithms along with their offline counterparts. The behavior of the detectors is correlated with the characteristics of different datasets (i.e., meta-features), thereby providing a meta-level analysis of their performance. Our study addresses several missing insights from the literature such as (a) how reliable are detectors against a random classifier and what dataset characteristics make them perform randomly; (b) to what extent online detectors approximate the performance of offline counterparts; (c) which sketch strategy and update primitives of detectors are best to detect anomalies visible only within a feature subspace of a dataset; (d) what are the tradeoffs between the effectiveness and the efficiency of detectors belonging to different algorithmic families; (e) which specific characteristics of datasets yield an online algorithm to outperform all others.