 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Causal Discovery: a case study on 5G telecommunication data
Feb 22, 2024We introduce the concept of Automated Causal Discovery (AutoCD), defined as any system that aims to fully automate the application of causal discovery and causal reasoning methods. AutoCD's goal is to deliver all causal information that an expert human analyst would and answer a user's causal queries. We describe the architecture of such a platform, and illustrate its performance on synthetic data sets. As a case study, we apply it on temporal telecommunication data. The system is general and can be applied to a plethora of causal discovery problems.
A Meta-level Analysis of Online Anomaly Detectors
Sep 13, 2022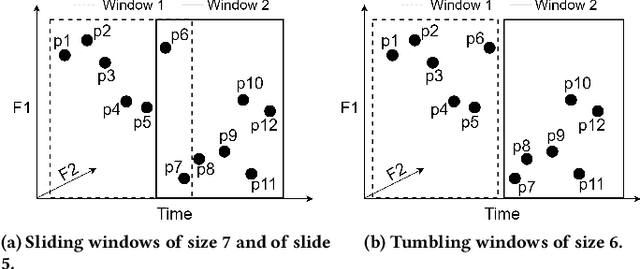
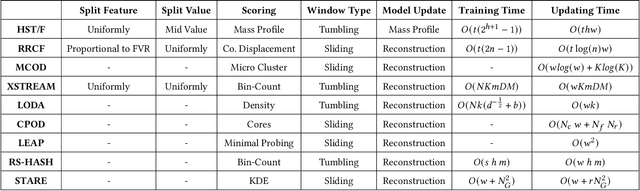
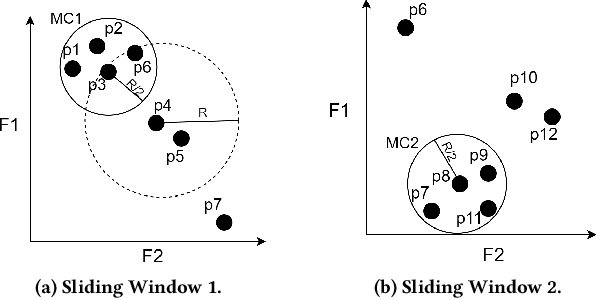
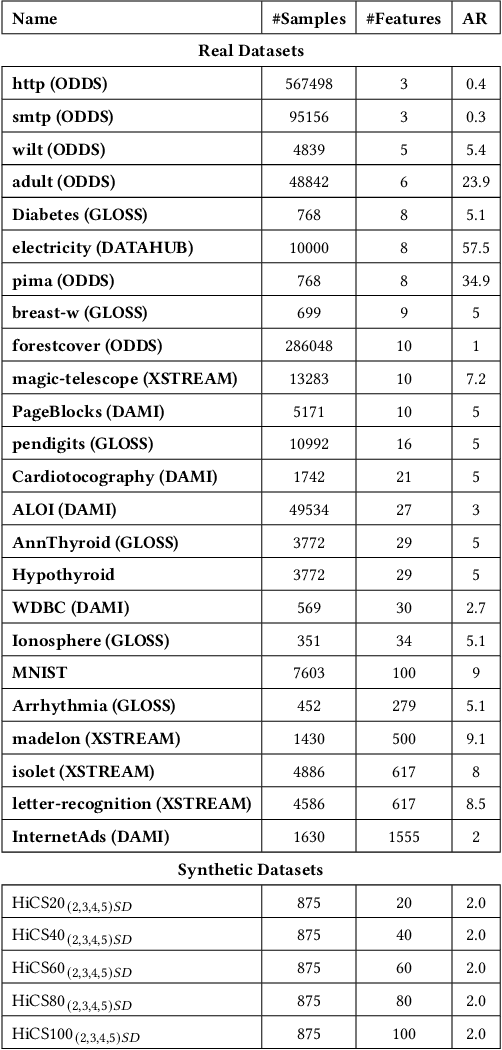
Real-time detection of anomalies in streaming data is receiving increasing attention as it allows us to raise alerts, predict faults, and detect intrusions or threats across industries. Yet, little attention has been given to compare the effectiveness and efficiency of anomaly detectors for streaming data (i.e., of online algorithms). In this paper, we present a qualitative, synthetic overview of major online detectors from different algorithmic families (i.e., distance, density, tree or projection-based) and highlight their main ideas for constructing, updating and testing detection models. Then, we provide a thorough analysis of the results of a quantitative experimental evaluation of online detection algorithms along with their offline counterparts. The behavior of the detectors is correlated with the characteristics of different datasets (i.e., meta-features), thereby providing a meta-level analysis of their performance. Our study addresses several missing insights from the literature such as (a) how reliable are detectors against a random classifier and what dataset characteristics make them perform randomly; (b) to what extent online detectors approximate the performance of offline counterparts; (c) which sketch strategy and update primitives of detectors are best to detect anomalies visible only within a feature subspace of a dataset; (d) what are the tradeoffs between the effectiveness and the efficiency of detectors belonging to different algorithmic families; (e) which specific characteristics of datasets yield an online algorithm to outperform all others.